摘要:AI 智能体(AI Agents)——即结合了基座模型与推理、规划、记忆及工具调用能力的系统——正迅速成为自然语言意图与现实世界计算之间的实用接口。本综述综合分析了新兴的 AI 智能体架构景观,重点关注以下三个维度:(i) 审议与推理(如:思维链式分解、自我反思与验证、以及约束感知决策);(ii) 规划与控制(从反应式策略到层级化及多步规划器);(iii) 工具调用与环境交互(检索、代码执行、API 接口及多模态感知)。 我们将前序工作组织为一个统一的分类体系,涵盖了智能体组件(策略/大语言模型核心、记忆、世界模型、规划器、工具路由及批判器)、编排模式(单智能体与多智能体;中心化与去中心化协作)以及部署场景(离线分析与在线交互辅助;安全敏感型与开放式任务)。此外,本文探讨了设计的关键权衡——包括延迟与准确性、自主性与可控性、以及能力与可靠性——并强调了评估工作的复杂性,这种复杂性源于非确定性、长程信用分配(long-horizon credit assignment)、工具与环境的可变性,以及重试机制和上下文增长等隐性成本。 最后,我们总结了测量与基准测试实践(任务集、人类偏好与效能指标、约束下的成功率、鲁棒性与安全性),并指出了亟待解决的挑战,包括工具行为的验证与护栏机制、可扩展的记忆与上下文管理、智能体决策的可解释性,以及真实工作负载下的可重复评估。
1.1 动机 (Motivation)
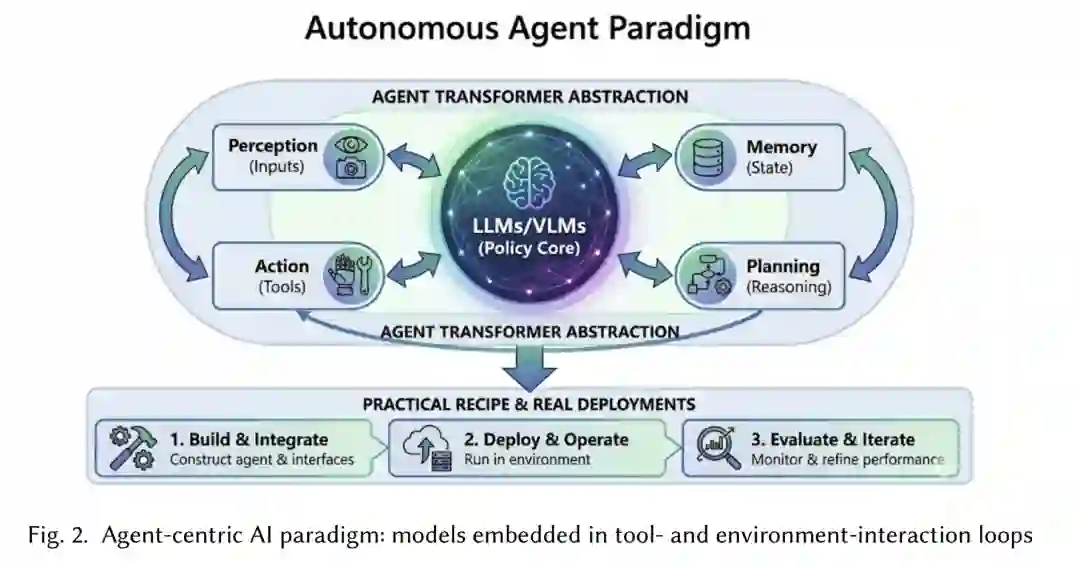
基座模型已使自然语言成为计算的实用接口,但大多数现实任务并非单轮问答。这些任务涉及从多个来源搜集信息、维护跨时间的执行状态、在不同工具间进行选择,以及在特定约束(延迟、权限、安全和成本)下执行多步动作。AI 智能体通过将基座模型与执行循环(Execution Loop)耦合,填补了这一空白;该循环能够观察环境、制定规划、调用工具、更新记忆并验证结果 [10, 31]。换言之,智能体不仅是文本生成器,更是一个控制器,负责将意图转化为在现实世界(软件仓库、浏览器、企业系统或物理机器人)中执行的程序。
1.2 背景 (Background)
现代数字化工作分散在各种界面和 API 之中:知识分布高度碎片化(文档、数据库、仪表盘),动作通过工具介导(搜索、代码执行、工单系统),而成功与否取决于端到端的最终结果,而非回复的“似真性”(Plausibility)。由于存在幻觉(Hallucinations)、缺乏**接地性(Grounding)**以及无法执行或验证动作,纯对话系统在这些场景中往往表现不佳。工具增强(Tool-augmented)与检索增强(RAG)设计通过将断言绑定至证据,并使中间产物可检查,从而提升了可靠性 [24, 64]。模块化的工具路由(如 MRKL 风格)通过将语言理解与专用工具分离,并强制执行可审计的结构化接口,进一步提升了治理能力 [21, 50]。
1.3 综述 (Overview)
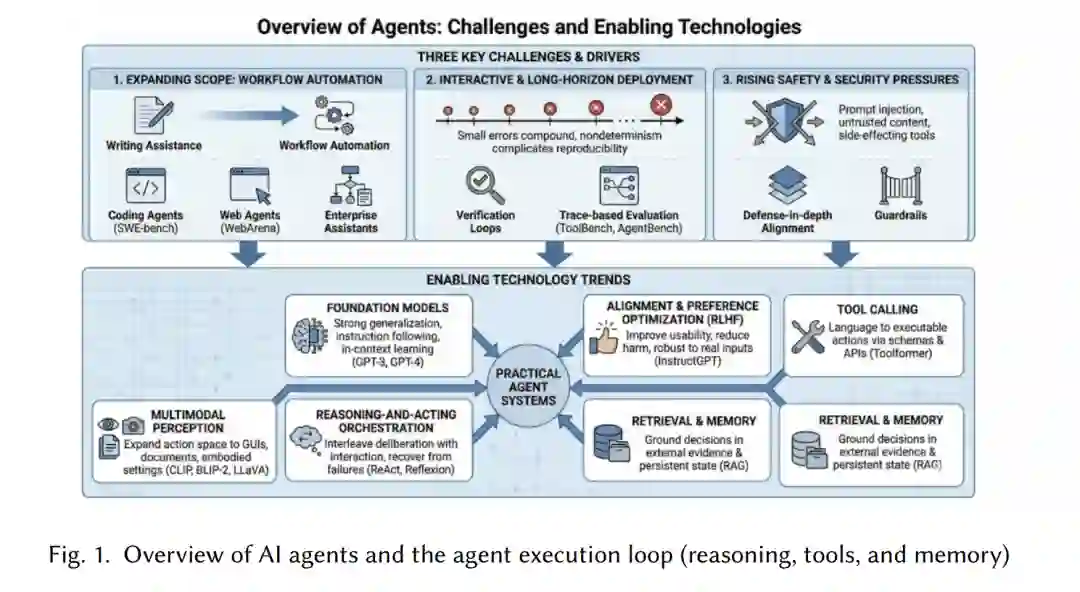
在当前时代,智能体尤为重要,原因有三: * 任务范畴扩展:从写作辅助转向工作流自动化。代码智能体可端到端解决问题 [20, 61],Web 智能体能在多变环境下操作真实网站 [14, 62, 67],企业助手则能在政策约束下编排多步操作。 * 部署模式演进:部署日益呈现出交互性与长程性(Long-horizon)特征。微小错误会随时间累积,且非确定性(如采样、工具故障)使可重复性变得复杂,这促使了验证循环与基于追踪(Trace-based)评估的发展 [29, 44, 65]。 * 安全与防护压力:提示词注入(Prompt Injection)、不可信的检索内容以及具有副作用(Side-effecting)的工具,要求在最终回复之外建立深度防御的对齐机制与护栏 [5]。
目前,若干技术趋势使实用的智能体系统成为可能。基座模型提供了强大的泛化能力、指令遵循能力以及涌现的语境学习(In-context Learning)能力,支持在不重训的情况下快速适配 [9, 36]。对齐与偏好优化(如 RLHF)提升了易用性并减少了有害行为,使智能体在面对真实用户输入时更具鲁棒性 [11, 37]。工具调用通过 Schema 和 API 将语言转化为可执行动作 [40, 50],而检索与记忆则将决策锚定在外部证据和持久状态中 [24, 38, 50]。**推理与行动(Reasoning-and-acting)**的编排模式将审议与环境交互交替进行,提升了接地性并能从失败中恢复 [53, 64]。最后,多模态感知通过将语言锚定在视觉输入中,将动作空间扩展到了图形用户界面(GUI)、文档及具身环境 [26, 28, 45]。
1.4 当前局限 (Current Gaps)
尽管进展迅速,智能体系统在规模化应用中仍受限于可靠性、可重复性和治理能力。长程任务会放大复合错误,而非确定性(采样、工具变动)使得在缺乏标准化协议和完整追踪记录的情况下,评估与调试变得极其困难 [29, 30, 44]。以工具为中心的智能体也引入了新的安全风险:不可信的检索内容和提示词注入可能操纵工具的使用,且具有副作用的动作需要比纯文本审核更强的约束机制 [5, 21, 48]。最后,系统层面的权衡——如自主性 vs. 可控性、延迟 vs. 可靠性以及能力 vs. 安全性——在跨领域和不同部署场景下尚未得到深入理解 [49, 66]。 本综述综合了推理、规划、工具使用及部署领域的新兴智能体架构。我们沿以下维度组织研究全景:(i) 学习策略与系统优化 (§3);(ii) 强调不同能力与评估体系的应用任务 (§5)。在全文中,我们将重点探讨循环往复的设计权衡,并强调在现实工具和环境多变性下的可重复评估。