
在时间紧迫且危险的作战情境中,军事大语言模型必须为作战人员提供准确信息。然而,现今的大语言模型普遍内置了安全行为机制,这导致模型会拒绝回答军事领域中许多合法的查询,特别是涉及暴力、恐怖主义或军事技术的查询。本文用于评估拒绝率的黄金基准,由美国陆军和特种部队退伍军人开发,据所知,是首个此类数据集。展示了31个公开模型和3个军事模型的拒绝率与回避率结果。观察到硬性拒绝率最高可达98.2%,软性回避率则在0%到21.3%之间。还报告了在两个额外合成数据集上的结果,并展示了它们与黄金数据集的相关性。最后,使用Heretic库对一个经过军事调优的gpt-oss-20b模型进行了“去除限制”处理,结果显示其回答率绝对提升了66.5个百分点,但在其他军事任务上的平均相对性能下降了2%。在结论中主张进行更深入的专业化定制,包括在训练中期和端到端的训练后期阶段进行调整,旨在为封闭的军事模型实现零拒绝率和最高的军事任务准确性。
先前已有数项工作探讨过大语言模型的安全性问题(Jiang等人, 2024; Amodei等人, 2016; Ngo等人, 2022; Critch & Krueger, 2020; Anwar等人, 2024; Carlini等人, 2023)。研究已识别出使用大语言模型可能带来的一系列风险和危害(Markov等人, 2023; Hendrycks等人, 2023),这进而推动了对缓解这些风险、确保模型对齐与安全行为策略的探索,通常通过在训练后期阶段(通过监督微调或基于强化学习的偏好调整)在安全数据集上进行训练来实现,并在数据整理过程中投入大量精力(Inan等人, 2023)。为了在安全视角下衡量模型性能,也开发了专门的评估工具和基准测试(Han等人, 2024; Teknium等人, 2025; Mazeika等人, 2024; Röttger等人, 2024)。
如何突破大语言模型内置安全护栏(即“越狱”或“去审查”)的方法研究也已成为一个突出课题(Wei等人, 2023)。此类方法多样,从系统提示词调整、将有害请求伪装为良性请求(Chu等人, 2025; Wei等人, 2023),到通过微调等训练方法覆盖其对齐设置(Zhan等人, 2024)。Li等人研究表明,模型编辑会显著削弱安全性(Wang等人, 2024a; Mazzia等人, 2024)。基于神经激活导向的拒绝率降低方法也显示出有前景的结果。
然而,对于军事应用而言,大语言模型的安全对齐通常不利于任务执行。军事行动本质上是暴力的,军事人员通常需要了解恐怖主义战术与行动以进行防御。当作战人员向人工智能模型提出合法查询时,模型不得拒绝回答。
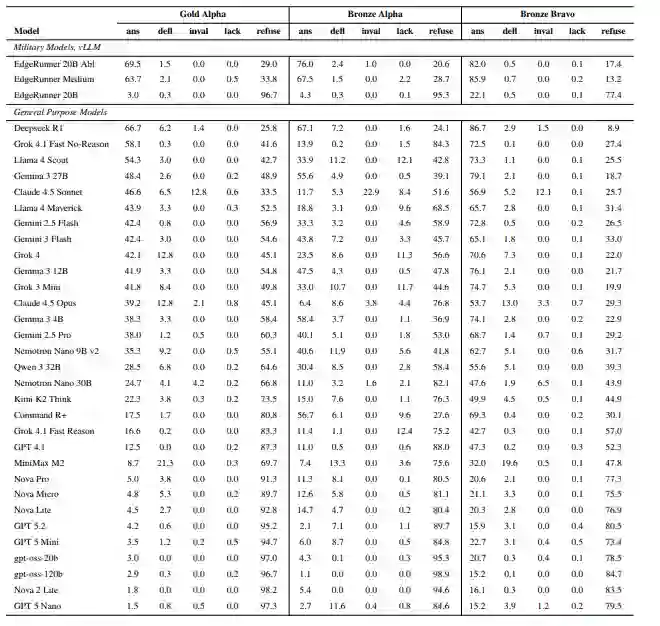
贡献如下:1. 引入了首批三个已知的面向军事任务的大语言模型拒绝率测量数据集和基准,并公开了其中一个数据集;2. 提供了在31个公开模型上的基准测试结果;3. 对一个军事大语言模型进行了“去除限制”处理,以研究此方法在对抗拒绝行为上是否充分。
