

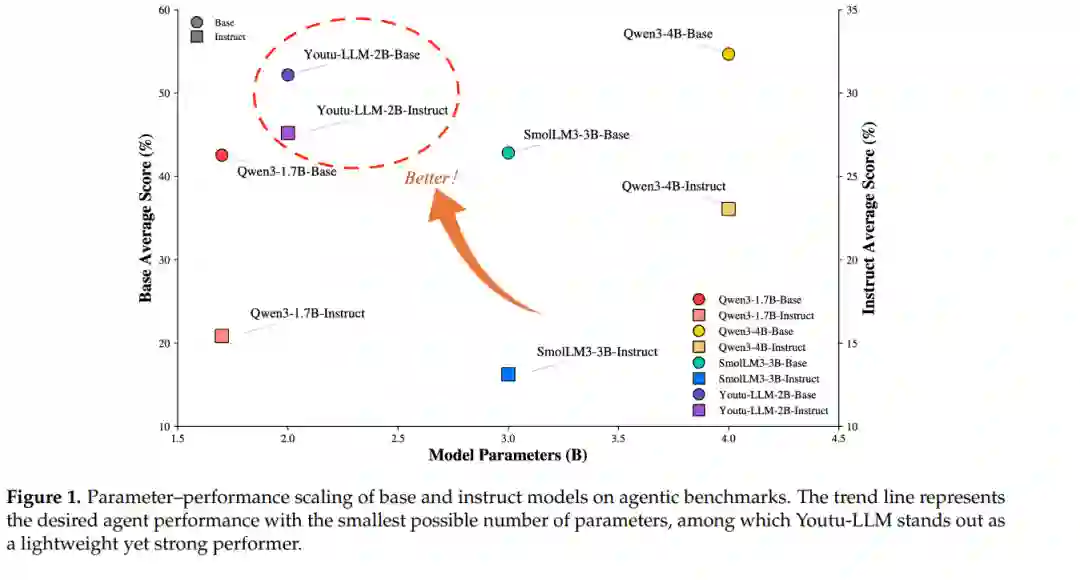
我们推出了 Youtu-LLM,这是一款轻量且强大的语言模型,它成功兼顾了高计算效率与原生智能体能力。不同于依赖知识蒸馏的典型小模型,Youtu-LLM(规模为 1.96B)采用从零开始的预训练方式,旨在系统性地培养推理与规划能力。其核心技术突破如下: (1) 支持长上下文的紧凑型架构:Youtu-LLM 基于稠密的多隐变量注意力(Multi-Latent Attention, MLA)架构,并构建了全新的面向 STEM 的词表,支持高达 128k 的上下文窗口。该设计使其能够在极小的内存占用下实现鲁棒的长文本推理与状态跟踪,是处理长程智能体及推理任务的理想选择。 (2) 原则性的“常识-STEM-智能体”课程化训练:我们策划了约 11T tokens 的海量语料库,并实施了多阶段训练策略。通过将预训练数据分布从通用常识逐步转向复杂的 STEM 和智能体任务,我们确保模型获得深层认知能力,而非表层对齐。 (3) 可扩展的智能体中期训练(Mid-training):针对智能体能力的专项中期训练,我们采用多样化的数据构建方案,在数学、编程和工具调用领域合成了丰富且多样的执行轨迹。这些高质量数据使模型能够有效地内化规划与反思行为。 广泛的评估结果表明,Youtu-LLM 树立了 2B 以下规模大语言模型的新标杆。在通用基准测试中,它展现出可与更大型模型竞争的性能;而在智能体特定任务中,它显著超越了现有的先进基准(SOTA),证明了轻量化模型同样可以具备强大的内在智能体能力。

1 引言
近年来,大语言模型(LLMs)取得了显著进展,正稳步迈向通用人工智能(AGI)[Hendrycks et al., 2025]。通过利用海量多领域语料库、不断增长的参数规模以及持续演进的训练范式,现代 LLM 在推理、问题解决和决策制定方面展现出强大的能力 [Guo et al., 2025, Yang et al., 2025]。值得注意的是,近期涌现的推理导向型模型在具有挑战性的智能体基准测试中取得了惊人的表现,凸显了大声规模训练在激发复杂认知行为方面的有效性 [Plaat et al., 2025]。 尽管取得了这些成功,目前的进展仍与参数缩放紧密耦合。尖端模型通常依赖数百亿甚至数千亿个参数,在训练和部署阶段都会产生巨大的计算、财务和环境成本 [Belcak et al., 2025]。这些限制显著阻碍了模型的可访问性以及在现实世界中的研究与应用,特别是在延迟敏感或资源受限的环境中。因此,开发既能保留强大的通用与推理能力,又具备部署实用性的轻量化大语言模型重新引起了研究兴趣。目前,更多知名的开源模型系列开始发布参数量少于 7B 甚至少于 2B 的模型 [Hu et al., 2024, Bakouch et al., 2025]。现有的提升小模型性能的方法主要依赖于蒸馏、指令微调或架构简化 [Sharma and Mehta, 2025]。尽管这些方法在一定程度上有效,但它们主要侧重于对齐输出行为,而非系统性地培养底层认知能力。因此,轻量化模型往往缺乏健壮性、泛化性及规划能力。 迫切的是,随着深度研究、编程和工具增强工作流等复杂任务的迅速崛起,轻量化 LLM 的上述局限性在现实世界的智能体场景中变得愈发显著。社区的普遍共识认为,有效的智能体不仅需要强大的语言理解能力,还需要具备规划、工具执行、状态感知和反馈驱动反思的内在能力 [Luo et al., 2025]。因此,近期的工作已开始探索语言模型中的这些原生智能体能力(Native agentic capabilities),从纯粹的外部智能体框架转向内化的推理与交互行为 [Zeng et al., 2025]。特别是,基于轨迹的训练以及在结构化交互数据上的持续预训练,在增强规划、推理和工具使用能力方面展现出巨大的潜力 [Li et al., 2025]。然而,现有研究仍留下了一个关键的开放性问题:轻量化 LLM 能否通过预训练(而非后期增强,如后期训练或智能体框架)获得强大的智能体能力? 在本研究中,我们主张,只要通过智能体化预训练过程早期且系统地注入面向智能体的信号,轻量化 LLM 也能实现强大的智能体性能。具体而言,我们推出了 Youtu-LLM,一款 2B 规模的轻量化开源模型,旨在平衡紧凑性与鲁棒的通用及智能体性能。我们的方法在“以 STEM 和智能体为中心”的训练原则下,整合了分词器(Tokenizer)设计、数据分配和多阶段学习策略方面的创新。具体来说,我们提出了一系列可扩展的框架,用于构建高质量的预训练智能体轨迹数据。这些框架涵盖了数学、编程、深度研究和通用工具使用等多个领域,涉及推理、反思和规划等广泛能力。通过所提出的数据流水线,我们获得了超过 200B tokens 的高质量智能体轨迹数据,为智能体化预训练提供了动力。 Youtu-LLM 在通用基准测试(图 2)和智能体基准测试(图 1)中均显著优于现有的同规模先进模型,且在多个设置下可与规模大得多的模型相媲美。除了性能提升外,我们的分析提供了首个系统性证据,证明智能体化预训练可以释放轻量化 LLM 的智能体潜力,并揭示了智能体能力的可扩展增长(Scalable growth)等现象。我们将 Youtu-LLM 的主要贡献、亮点和见解总结如下: * 轻量化智能体 LLM:我们推出了 Youtu-LLM,这是一款轻量化开源语言模型,其在智能体基准测试中的表现显著优于同等规模甚至更大规模的先进模型。 * 原生智能体能力诱导:在以智能体为中心的理念指导下,我们通过分词器设计、数据分配和多阶段学习等方面的创新,提出了一种增强原生智能体能力的原则性训练范式。 * 可扩展的智能体轨迹构建:我们提出了一系列可扩展的框架,用于构建高质量的智能体轨迹数据,涵盖数学、编程、深度研究和通用工具使用等多个领域的推理、反思和规划能力。 * 实证见解:我们对轻量化 LLM 的智能体化预训练进行了首次系统分析,揭示了智能体能力的可扩展增长规律。

