
导读
大语言模型(LLM)的预训练数据组合,常被比作模型的“数字DNA”——它从根本上决定了模型的行为、能力倾向和失败模式。然而,这层最重要的信息却是AI行业最被严密保守的秘密之一。当我们面对一个强大的LLM时,我们几乎完全不了解它“吃”了哪些领域的数据,每个领域的数据占了多少比例。这种不透明性为审计模型偏见、评估版权侵权风险、解释不同领域性能差异带来了巨大障碍。
针对这一痛点,来自MBZUAI的研究团队(Yaxin Luo, Jiacheng Cui, Xiaohan Zhao等)在ACL 2026主会上发表了题为《LLMSurgeon: Diagnosing Data Mixture of Large Language Models》的论文。他们开创性地将问题从“这个样本是否在训练集中?”(会员推理攻击)提升到“这个模型的训练数据域级分布是什么?”,并提出了核心框架LLMSurgeon。该框架仅需利用目标LLM的生成文本,通过逆问题方法恢复其预训练语料的域级分布,无需访问模型的权重或任何训练数据。
这篇论文最大的创新在于:它将数据混合恢复问题形式化为“标签偏移假设下的逆问题”,通过估计校准的软混淆矩阵并求解约束逆问题,巧妙地去除了分类器系统偏差,实现了从宏观上“透视”模型训练数据组成的目标。他们还构建了LLMScan基准,一个包含8个开源模型(1B-65B)的标准评估套件,为这类后验审计方法提供了可验证的实验平台。对于关注AI安全、透明度、以及模型治理的读者来说,这是一篇极具启发性和实用价值的工作。
论文基本信息
英文题目 LLMSurgeon: Diagnosing Data Mixture of Large Language Models 作者 Yaxin Luo, Jiacheng Cui, Xiaohan Zhao, Xinyi Shang, Jiacheng Liu, Xinyue Bi, Zhaoyi Li, Zhiqiang Shen arXiv ID 2605.30348 类别 cs.CL, cs.AI, cs.LG Comments/接收信息 ACL 2026 Main. Code at https://github.com/Yaxin9Luo/LLMSurgeon 原文链接 http://arxiv.org/abs/2605.30348v1
摘要
大语言模型的预训练数据混合构成了它们的“数字DNA”,塑造了模型行为、能力与失败模式。然而,这种组成极少被公开,使得事后审计数据组合或来源变得困难。 在这项工作中,作者形式化了数据混合手术(Data Mixture Surgery, DMS)问题:在给定目标LLM生成文本的情况下,估计其预训练语料在预定义分类法下的域级分布。作者提出了LLMSurgeon,一个强大的框架,将DMS视为标签偏移假设下的逆问题。LLMSurgeon并非直接聚合分类器输出,而是估计一个经过校准的软混淆矩阵,并求解一个约束逆问题,以纠正系统性的领域混淆,恢复潜在的混合先验。 为了进行评估,作者引入了LLMScan,一个基于具有透明预训练混合的开源LLM构建的、配方可验证的评估套件。在LLMScan上,LLMSurgeon在固定协议下高保真地恢复了域混合。这项工作提出了一种实用的、事后方法,用于在无需访问训练数据的情况下审计基础模型的“数字DNA”。
引言:论文要解决什么问题
现代大语言模型是一个巨大的“数字炼金术”:其卓越的推理与编码能力毋庸置疑,但构成其庞大规模训练语料的“成分”,却是AI行业中最讳莫如深的秘密之一。这种透明度的缺失,为安全、问责与治理带来了关键瓶颈。无法获取这些模型的“数字DNA”及其预训练数据组成,就无法审计人口统计偏见、评估版权侵权风险,或解释跨领域的性能差异。 然而,当前试图窥探这些黑盒的努力,主要依赖于会员推理攻击(Membership Inference Attacks, MIA)。虽然MIA工具在微观层面(识别特定文档是否出现在训练集中)是有效的,但它们无法回答关于数据分布的宏观问题。这造成了一个悖论:MIA工具可以发现一粒沙(特定样本),却无法描述整个沙滩(域级组成)。试图通过聚合数百万个噪音大、实例级的MIA预测来估计全局组成,在计算上极其昂贵,并且容易产生灾难性的误差累积。 这个缺口要求研究焦点从实例级检测转向了数据混合手术(DMS):估计构成模型世界知识基础的领域全局比例。作者将DMS定义为一个有目标的审计任务,而非开放式的发现任务。为了解决这个问题,作者提出了LLMSurgeon,一个精心设计的框架,将DMS视为由标签偏移假设控制的逆问题。
核心创新点
- 形式化新问题:首次形式化了**数据混合手术(DMS)**问题,将研究视角从“是否在训练集中”提升到“训练数据宏观分布是什么”。
- 提出有效方法:提出了LLMSurgeon,一种轻量级的、能准确从生成文本中推断出潜在域先验的方法,无需访问模型权重或训练数据。
- 建立标准基准:提出了LLMScan,一个首个、可验证的基准测试,用于标准化数据混合手术的评估。
图1:LLMSurgeon 的三步流程。先训练域分类器并估计软混淆矩阵,再用中性提示采样目标 LLM 的生成文本,最后通过带约束的逆校正恢复预训练语料的域级混合比例。来源:根据原论文 图 2 中文重绘。
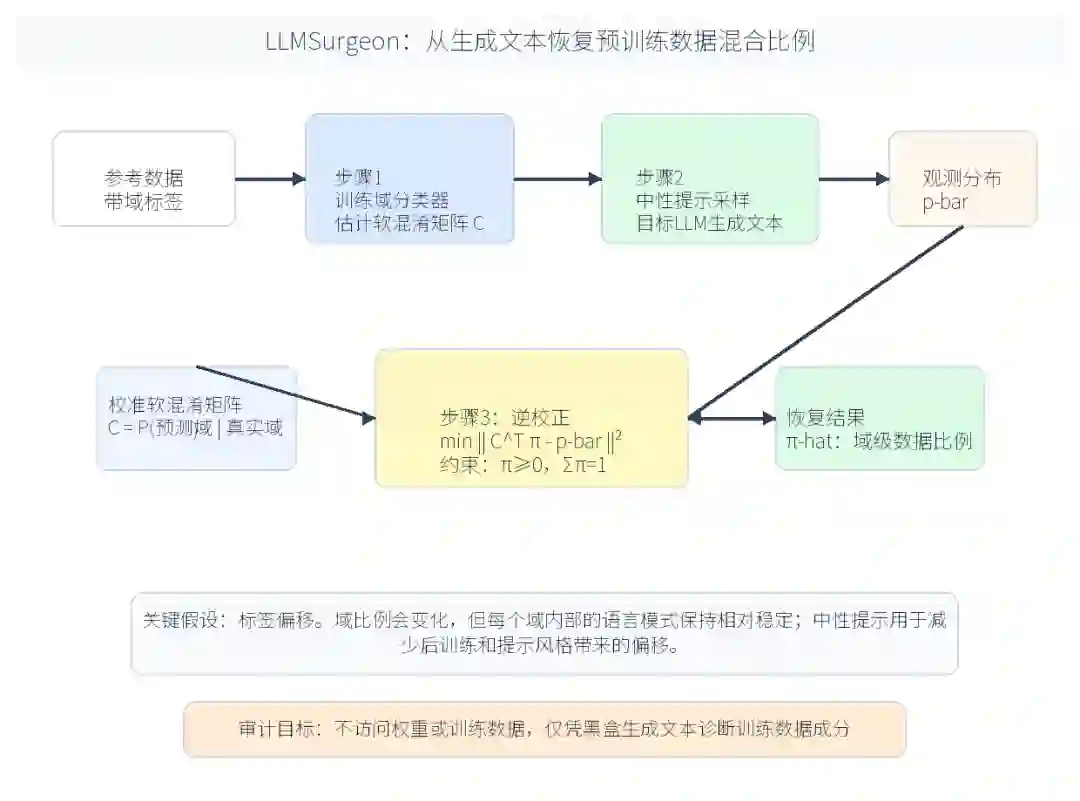 图1:LLMSurgeon 的三步流程。先训练域分类器并估计软混淆矩阵,再用中性提示采样目标 LLM 的生成文本,最后通过带约束的逆校正恢复预训练语料的域级混合比例。来源:根据原论文 图 2 中文重绘。
图1:LLMSurgeon 的三步流程。先训练域分类器并估计软混淆矩阵,再用中性提示采样目标 LLM 的生成文本,最后通过带约束的逆校正恢复预训练语料的域级混合比例。来源:根据原论文 图 2 中文重绘。方法:核心思路与技术路线
问题形式化
设 X 为文本序列空间,Y = {1, ..., K} 为 K 个不相交的语义域集合(如论文、维基百科、代码)。每个域内的文本条件分布定义为 p_i(x) ≜ p(x|y=i)。 在预训练期间,LLM在训练语料 D_train 上优化参数 θ。该语料被建模为由真值混合向量 α ϵ Δ^(K-1) 定义的混合分布: p_α(x) = Σ_i=1^K α_i p_i(x) 其中 α_i 代表域 i 在训练集中的真实比例(这就是我们想要审计的量)。 当使用中性提示查询时,训练好的LLM会从诱导分布 q(x) 中生成样本。由于优化动力学、欠拟合或采样温度等原因,模型内部对域的使用可能与精确的训练比例略有偏差。生成分布被建模为: q_π(x) = Σ_i=1^K π_i p_i(x) 其中 π ϵ ∆^(K-1) 是潜在有效先验,即模型行为实际编码的域混合。 预测目标:给定一组生成样本 X_gen = {x_n}_{n=1}^N ~ q_π(x),目标是估计向量 π。作者假设生成过程遵循标签偏移假设,即边际分布从训练的先验 α 偏移到生成的先验 π,但给定域的条件特征分布保持不变: q(x|y=i) ≈ p(x|y=i) 这意味着模型生成代码时,其统计特征与训练时看到的代码相似,即便生成频率不同。这允许将 π 的恢复视为一个分布匹配问题。
挑战:为什么简单的MIA聚合不行?
一个直接的思路是聚合MIA信号,但面临三个主要障碍:
- Token限制:MIA通常为短序列设计,难以规模扩展到文档级语料。
- 误差累积:点对点的预测误差在成百上千万样本聚合时会被放大,导致高方差的分布估计。
- 算法偏置:MIA在不同域上表现不一致(例如,对记忆的代码准确率高,但对普通文本准确率低),引入系统性的偏斜。
为什么这是一个逆问题
LLMSurgeon 的关键不是“把分类器预测结果数一数”,而是承认分类器本身会系统性混淆相近领域。例如,ArXiv 与论文类文本、C 与 C++、C4 与 CommonCrawl 之间存在天然语义重叠。若直接把生成文本丢给域分类器,再按预测标签计数,得到的是有偏观测分布,而不是真实训练域先验。 论文将这一关系写成 p_bar ≈ C^T π。其中 p_bar 是分类器在目标模型生成文本上的平均输出,C 是在参考数据上估计出的软混淆矩阵,π 则是希望恢复的真实域混合比例。于是问题变成一个带 simplex 约束的线性逆问题:寻找非负且和为 1 的 π,使得经过分类器混淆矩阵后最接近观测分布。这个视角把“域分类”提升为“校准后的分布恢复”,也是 LLMSurgeon 相比普通 MIA 聚合方法的核心差异。
LLMSurgeon框架:三步流程
LLMSurgeon是一个严格的三阶段流水线,核心思想是将DMS作为一个逆问题来解决。 步骤一:训练外部分类器并计算软混淆矩阵
- 目标 在已知参考数据上训练一个代理分类器,并计算其系统偏置。
- 操作 在参考数据集(如SlimPajama)上训练一个外部分类器
f_ϕ(默认用DistilBERT)。这个分类器用于将文本分配到K个预定义的域。 - 构建软混淆矩阵 分类器会存在偏置(例如,将“生物学论文”误判为“医学论文”)。为了量化这种偏置,作者在参考数据的一个校准集上,通过比较分类器的预测结果与真实标签,计算一个校准的软混淆矩阵
C。C_ij = P(ŷ = i | y = j),即给定真实标签j,分类器预测为域i的概率。这个矩阵编码了分类器固有的系统性“混淆模式”。
步骤二:采样目标LLM并获取有偏观察
- 目标 从目标LLM获取其生成文本,并通过冻结的分类器得到有偏的域分布估计。
- 操作 使用一组中性提示(例如,“继续写下一段:”、“本文讨论了:”)对目标LLM进行采样,得到生成文本集
X_gen。作者强调,中性提示是核心,旨在最小化后训练对齐(如RLHF)对生成分布的扭曲,使得生成的文本能更真实地反映模型的训练先验。 - 获取有偏观察 将
X_gen输入到步骤一冻结的代理分类器f_ϕ中,得到每个文档的预测结果。然后对这些预测进行平均,得到观察分布p_obs。p_obs是域的预测比例,但由于分类器存在偏置,它并不等于真实的生成先验π。
步骤三:逆校正——求解约束逆问题
-
目标 利用步骤一的混淆矩阵,对步骤二的有偏观察进行数学“去模糊”,恢复潜在的域先验。
-
核心原理 根据混淆矩阵的定义,观察分布
p_obs与真实先验π之间存在线性关系:p_obs = C^T * π。因此,恢复π的问题就变成了一个逆问题。 -
求解过程 LLMSurgeon通过求解一个带约束的逆问题来恢复
π:π̂ = argmin_π || C^T π - p_obs ||_2^2 s.t. π ≥ 0, Σ_i π_i = 1 -
意义 这类似于图像去模糊中的“反卷积”。分类器的有偏输出被视为“失真的信号”,混淆矩阵描述了“模糊核”,而逆校正过程就是恢复原始“清晰信号”的过程。这个过程有效地纠正了分类器的系统性域混淆,得到了高保真的域先验估计。
实验:设置、指标与结果
实验设置与指标
基准:LLMScan,一个由作者建立的标准化评估套件,包含8个完全开源且预训练数据配方透明的LLM。这8个模型覆盖了三个粒度级别,以评估方法的鲁棒性:
- 粗粒度(Coarse-Grained)
K=6,包括LLaMA-1-7B/65B, OLMo-1B, Amber-13B。参考数据来自SlimPajama-DC。 - 中粒度(Mid-Grained)
K=17,包括GPT-Neo-2.7B, Pythia-2.8B/12B。参考数据来自The Pile。 - 细粒度(Fine-Grained)
K=87,包括StarCoder-15.5B。参考数据来自The Stack(区分87种编程语言)。
评估指标:
- 重叠准确率(Overlap Accuracy)
1 - 1/2 * Σ_k |α_k - π_k|,衡量恢复出的比例与真实比例的相似度。范围[0, 1],越高越好。 - 平均绝对误差(Mean Absolute Error, MAE) 恢复比例的绝对偏差平均值。
- 决定系数(Coefficient of Determination, R²) 评估结构相关性。
基线方法:
- MIA方法 包括Joint-Logit, Loss, Ref, GradNorm, Zlib, Neighbor, Min-K%, Min-K%++, DC-PDD, Recall。这些基线通过聚合MIA信号来估算域比例。
- 无逆校正方法(w/o Inverse Correction) 直接使用原始分类器的聚合输出作为估计,不进行逆校正。
- DUCI 一种基于聚合去偏会员预测的估计方法。
硬件:LLaMA1-65B在4块NVIDIA A100上推理,其余模型在NVIDIA RTX 4090上执行。
LLMScan基准的三层粒度
LLMScan 是本文构建的 recipe-verifiable 评估套件,强调“真实公开配方”而不是合成混合。它包含 8 个开源基础模型,规模从 1B 到 65B,覆盖三种审计粒度。 第一类是粗粒度审计,K=6,使用 SlimPajama-627B-DC 定义的高层数据域,用于 LLaMA-1、OLMo 和 Amber 等通用模型,领域包括 Web、GitHub、Wikipedia、Books、ArXiv、StackExchange 等。第二类是中粒度审计,K=17,使用 The Pile 的域划分,用于 Pythia 和 GPT-Neo。第三类是细粒度审计,K=87,使用 The Stack,把 StarCoder 的训练数据细分为不同编程语言。三层设置由易到难:域越细,语义重叠越强,混淆矩阵越容易病态,恢复任务也越困难。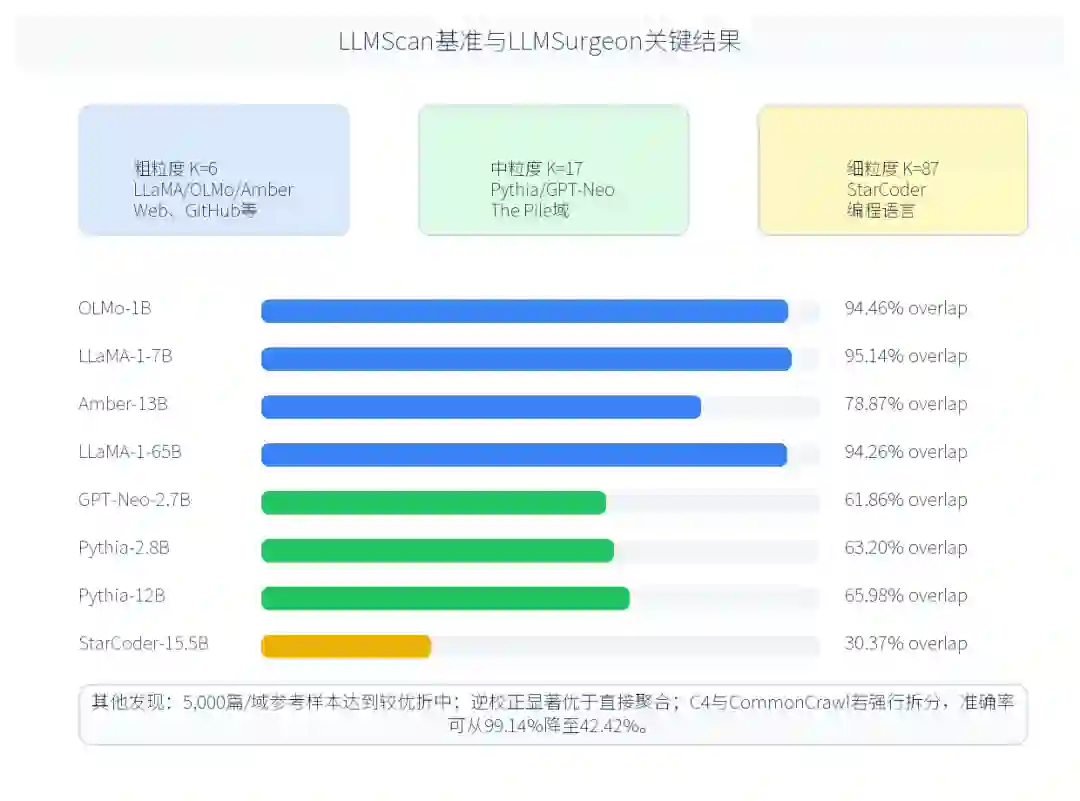
主要结果:LLMScan基准测试
粗粒度结果:
- 在OLMo-1B和LLaMA1-7B上,LLMSurgeon的重叠准确率分别达到了惊人的94.46%和95.14%。
- 相比之下,所有MIA基线的表现均低于50%,证明了简单的聚合方法在此宏观任务上的无力。
- 在Amber-13B和LLaMA1-65B上,LLMSurgeon也分别取得了78.87%和94.26%的优异表现,显示出良好的模型规模鲁棒性。
中粒度结果:
- 在Pythia-2.8B、Pythia-12B和GPT-Neo-2.7B上,LLMSurgeon的准确率分别为63.20%、65.98%和61.86%,显著优于最佳基线(GradNorm表现分别为55.66%、35.98%、58.78%)。
- 虽然准确率相对于粗粒度有所下降,但LLMSurgeon保持了稳定且最先进的表现。
细粒度结果:
- 在区分87种编程语言的StarCoder上,所有方法的准确率都大幅下降。LLMSurgeon取得了**30.37%**的重叠准确率,依然超越了最佳基线(GradNorm:27.54%)。
- 这表明在极度相似、高度重叠的领域语义下,逆校正方法虽然有效,但精度受限于混淆矩阵的稳定性。
关键实验数字
在 LLMScan 主表中,LLMSurgeon 在粗粒度设置上表现最强:OLMo-1B 达到 94.46% overlap accuracy,LLaMA-1-7B 达到 95.14%,Amber-13B 为 78.87%,LLaMA-1-65B 为 94.26%。这说明在高层数据域上,模型生成文本足以暴露相当稳定的训练数据先验。 在中粒度 The Pile 设置中,任务更难,但 LLMSurgeon 仍明显优于 MIA 类基线:GPT-Neo-2.7B 为 61.86%,Pythia-2.8B 为 63.20%,Pythia-12B 为 65.98%。在最难的 StarCoder 细粒度语言识别上,LLMSurgeon 达到 30.37%,虽然绝对数不高,但仍超过最佳基线 GradNorm 的 27.54%。论文解释,这并非方法完全失效,而是 87 种编程语言之间存在高度重叠,例如 C/C++、Java/JavaScript、Markdown/文本脚本等类别很难仅凭短生成片段稳定区分。 作者还报告了多个实用分析。参考样本数量方面,100篇/域明显不足,1,000篇/域带来显著提升,而 5,000篇/域基本达到较优折中;继续增加到 10,000篇/域收益有限甚至略有退化。域预定义方面,如果把 C4 和 CommonCrawl 强行拆开,LLaMA 分析准确率会从 99.14% 降至 42.42%,说明 DMS 的前提是域之间必须有可分辨的语言模式。
消融与分析
分类器骨干网络消融: 作者评估了不同分类器对最终结果的影响,包括TF-IDF+逻辑回归、MLP、Transformer和DistilBERT。结果显示:
- DistilBERT在所有模型上的表现最佳或接近最佳(例如OLMo-1B: 94.46%, LLaMA1-7B: 95.14%),是默认的推荐选择。
- Transformer表现良好,但不如DistilBERT稳定。
- TF-IDF在某些粗粒度场景下(如LLaMA1-65B)表现不俗(92.64%),但在细粒度或更难的场景下显著下降。
- 这证明了更强、更可靠的分类器能为逆校正过程提供更好的输入,从而提升最终性能。
逆校正的必要性: 作者将LLMSurgeon与“无逆校正”基线(即直接使用分类器输出)进行了比较。在所有设置下,LLMSurgeon都大幅超越了直接估计。这强力证明了逆校正步骤是获得高保真域估计的关键,它有效解决了分类器在不同域上的系统性偏置问题。
泛化与安全审计价值
除主基准外,论文还做了两个很有启发的扩展实验。第一是 OLMo 系列的时间外推:在 OLMo-1B 和 OLMo-2 上固定所有评估选择后,直接测试 held-out 的 OLMo-3,仍达到 86.41% overlap accuracy,并能较好恢复 Web 这一主导成分。这说明 LLMSurgeon 不是只记住某个模型的具体配方,而是具备一定跨版本泛化能力。 第二是受控 GPT-2 沙盒和毒性注入实验。作者训练了 balanced、book-heavy、web-heavy 三种 GPT-2 混合,LLMSurgeon 分别得到 75.62%、50.15%、87.53% overlap accuracy。在安全审计实验中,训练语料中注入 5%、10%、20% Toxic 数据,估计结果分别为 7.90%、12.00%、22.73%,毒性质量估计准确率约为 97%-98%。这表明 DMS 可以作为低成本安全分诊工具:它不能替代红队或输出毒性评测,但可以帮助审计者优先定位训练暴露风险更高的模型或 checkpoint。
方法边界与治理意义
从治理角度看,LLMSurgeon 的定位很清晰:它不是要证明某一段文本是否出现在训练集中,而是要回答更宏观的问题——模型总体上更像是由哪些领域塑造出来的。这个区别很重要。样本级成员推断常常面临强隐私和法律争议,也容易被记忆、重复、去重策略影响;域级混合恢复则更接近模型审计中的“成分分析”,用于判断模型是否过度依赖 Web、代码、论文、论坛或高风险内容。 这类方法的现实价值在于,它为闭源模型和半透明模型提供了一种外部审计入口。即使模型提供方不披露训练配方,审计者仍可以通过标准化提示采样,估计其生成分布背后的域级先验,再与模型在不同领域的能力、偏见和安全行为进行关联分析。例如,如果一个模型在代码任务上表现异常强,但估计出的 GitHub/代码比例也很高,那么能力来源就有了更可解释的线索;如果毒性数据占比估计偏高,则可以优先进入更细的红队测试流程。 当然,LLMSurgeon 的输出应被理解为“统计审计信号”,而不是绝对真相。它依赖参考语料、域定义、采样提示、分类器校准和生成文本长度等因素。最理想的使用方式,是把它和模型卡、数据声明、行为评测、红队测试、版权审查等机制结合起来,形成多证据链的透明度评估。
结论:贡献、局限与启发
贡献总结
- 形式化新问题:首次提出并形式化了**数据混合手术(Data Mixture Surgery, DMS)**问题,将LLM审计的粒度从实例级提升到域级。
- 提出有效方法:提出了LLMSurgeon框架,通过标签偏移假设下的逆问题方法,仅从LLM生成文本中即可高保真地恢复其预训练数据的域级混合比例。
- 建立首个基准:建立了LLMScan基准,一个由具有透明预训练混合的开源模型构成的标准化评估套件,为未来该领域研究提供了基础平台。
- 促进透明度:这项工作为在无需依赖自愿披露的情况下,对基础模型进行事后审计提供了实用机制,有助于推动AI领域的数据透明和责任担当。
局限性
- 依赖标签偏移假设:方法成立的关键是中性提示能准确反映训练先验。但经过大量后训练对齐(如RLHF或指令微调)的模型,其生成分布可能会被扭曲,从而影响估计精度。
- 闭世界假设:方法依赖于一个预定义的固定分类体系,无法发现或处理该体系之外的新兴领域。
- 精度受领域语义可分离性限制:当目标域之间高度重叠(例如C和C++编程语言)时,混淆矩阵会变得稠密且病态,导致线性逆校正的稳定性下降,影响估计的最终精度。
启发与未来方向
- “逆对齐”技术 未来可以探索“逆对齐”技术,以从模型的生成文本中分离出基础训练分布与对齐后带来的分布偏移。
- 层次化推理 针对高重叠域,可以采用层次化推理策略,先区分大类,再在大类内部进行精细区分,避免一次性处理病态矩阵。
- 扩展到多语言与多模型家族 将框架扩展到更广泛的模型家族和多语言语料,以进一步验证其通用性。
原文信息
- 英文题目 LLMSurgeon: Diagnosing Data Mixture of Large Language Models
- 中文题目 LLMSurgeon:诊断大语言模型的数据混合比例
- 作者 Yaxin Luo, Jiacheng Cui, Xiaohan Zhao, Xinyi Shang, Jiacheng Liu, Xinyue Bi, Zhaoyi Li, Zhiqiang Shen
- 机构 Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), University College London (UCL)
- arXiv ID 2605.30348
- 接收信息 ACL 2026 Main
- 代码与数据 https://github.com/Yaxin9Luo/LLMSurgeon
- 原文链接 http://arxiv.org/abs/2605.30348v1
