
随着大语言模型被应用于日益增长的长篇幅、复杂任务,对能够评估选择性阅读与异构多模态信息源整合能力的现实长上下文基准测试需求愈发迫切。这一需求在诸如大规模军事行动规划等地理空间规划问题上尤为突出,此类任务要求能基于地图、命令、情报报告及其他分布式数据进行快速准确的推理。为填补这一空白,提出MilSCORE(军事场景上下文推理基准)。据所知,这是首个基于用于训练的复杂模拟军事规划场景、由专家编写的场景级多跳问答数据集。MilSCORE旨在评估高风险决策与规划能力,探究大语言模型跨多源信息融合战术与空间推理的能力,以及其在长跨度、地理空间信息丰富的上下文中的推理能力。该基准测试包含七大类多样化题型,既针对事实性信息提取,也针对约束条件、战略及空间分析的多步推理。提供了评估方案,并报告了一系列当代视觉语言模型的基线结果。研究结果凸显了模型在MilSCORE上存在显著提升空间,表明现有系统在处理现实的、场景级的长上下文规划任务时存在困难,从而将MilSCORE定位为未来工作的一个挑战性测试平台。
关键词:地理空间推理 · 视觉语言模型 · 长上下文基准测试 · 军事决策
地理空间信息分析被广泛用于多领域下游任务,包括交通、农业、公共卫生,以及自然灾害响应和军事行动等高风险场景。遥感、卫星系统、激光雷达和GPS技术的革新降低了地理空间数据生成成本,而机器学习和计算机视觉的进步则使得更有价值信息的提取更为高效。然而,随后的几何规划与推理过程需要整合几何坐标、地图、卫星影像和社会经济数据,这一任务传统上高度依赖大量人力专业知识与手动处理。
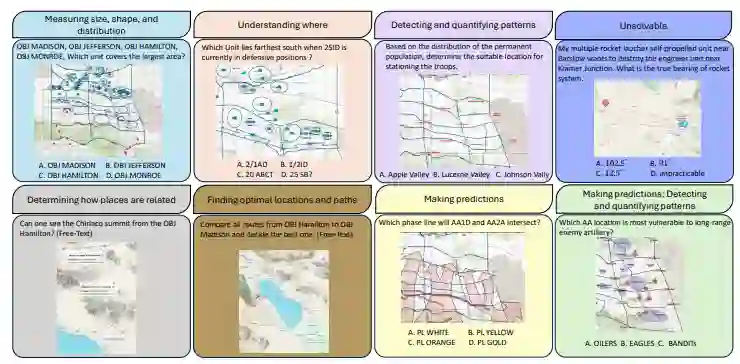
图1:按空间分析内容类别分组的MilSCORE问题示例。该图展示了每个类别的代表性题目:“理解位置”、“测量尺寸、形状与分布”、“确定地域关联性”、“寻找最优位置与路径”、“探测与量化模式”、“进行预测”以及“无解任务”——包含选择题和自由文本格式,反映了现实世界军事地理空间推理场景的多样性与复杂性。
先进的大语言模型及其多模态扩展——视觉语言模型,为自动化复杂地理空间推理任务提供了新途径,并已展现出广泛的世界知识。然而,将通用大语言模型直接应用于军事地理空间规划等专业领域存在若干挑战。一个关键问题是幻觉:大语言模型可能生成不正确或与现实不符的不一致地理空间信息。另一挑战是规划问题的长上下文特性——作战命令与支持文档通常篇幅冗长,且包含多种异构来源。当前的大语言模型难以处理如此大量的输入,其超长上下文窗口的实际利用率有限,且性能常随上下文长度增加而下降。这些局限性凸显了需要能反映军事作战命令场景中地理空间规划与推理实际需求的长上下文基准测试。
本工作中,利用行动方案地图,结合标准化地理空间特征数据和相关作战命令文档,研究视觉语言模型在军事决策任务上的表现。推出MilSCORE。据所知,这是首个基于复杂训练作战命令、由专家编写的场景级多跳问答数据集。MilSCORE包含超过100个综合性查询,涉及源自一个完整军事训练作战场景的50多幅不同地图。该基准测试旨在探究高风险决策与规划能力,包括兵力分配、阶段间协同以及条令约束下的风险评估。在MilSCORE上评估了多种专有和开源视觉语言模型,包括Llama-3.2 11B-Vision-Instruct、Qwen-2-VL-7B、GPT-4o和GPT-4o mini,采用了零样本提示和思维链推理两种协议,并分析了它们在长上下文、地理空间推理任务中的失败模式。
总结而言,本文的贡献如下:
- 提出了MilSCORE,这是一个新颖的场景级基准测试,包含基于训练作战命令和行动方案地图、由专家编写的多跳问答,旨在现实的长上下文地理空间规划环境中测试军事决策过程。
- 提出了一个评估方案,并对前沿视觉语言模型在MilSCORE上进行了全面的实证研究,确立了基线结果,并指出了未来利用大语言模型和视觉语言模型进行长上下文、决策导向的地理空间推理研究的关键挑战。

