
本研究旨在应对美国海军内部如何在进攻性网络作战与防御性网络作战之间分配有限资源的挑战。在美国海军中,美国舰队网络司令部/美国第十舰队司令部仅获得海军总资金的4%。随着网络能力在现代战争中扮演愈发重要的角色,理解如何优化进攻性网络作战、防御性网络作战-响应行动以及防御性网络作战-内部防御措施变得至关重要。本研究应用影响图和神经网络,模拟在不同资金水平、情报质量及对手实力条件下蓝军网络作战的效能。研究开发了深度Q网络,用以模拟一系列作战场景和对手行为,从而实现在不确定性下的战略决策。研究结果展示了不同资金策略如何影响作战成果,并确定了能够最大化任务效能的分配方案。该模型有助于决策者可视化权衡取舍并预测对手影响,为完善网络投资战略提供工具。未来工作应集成更具动态性的对手响应和实时情报更新,以进一步提升不确定环境下的决策能力。
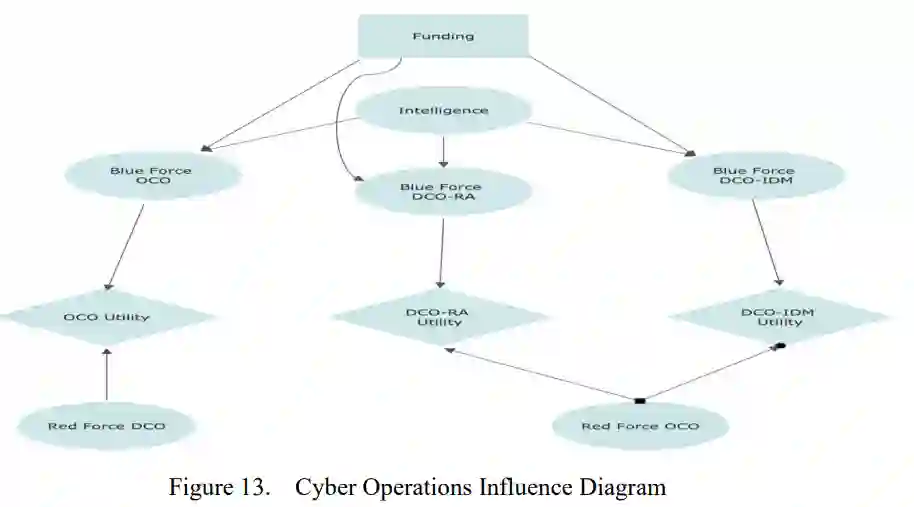
现代军事行动对网络空间的依赖日益加深,这凸显了有效实施进攻性网络作战与防御性网络作战的重要性。在预算受限且对手能力不断增强的情况下,美国海军必须分配有限的网络资源,以在应对多样化威胁时最大化任务效能,同时在不确定环境中降低风险。本研究致力于应对在不同情报质量和对手实力条件下,如何在攻防行动之间高效分配网络资金的挑战,并提供了一种基于决策理论和机器学习的数据驱动决策支持方法。
本研究的目标是开发并评估一种能够推荐适应不断变化的作战条件的网络资金策略的决策支持模型。具体而言,该模型旨在进攻性网络作战、防御性网络作战-响应行动和防御性网络作战-内部防御措施这三种网络能力之间分配资金,同时考虑当前情报状态和对手实力。研究探索了两种建模方法:一种是直接在影响图输出上训练的神经网络,另一种是通过与影响图输出所创建的环境进行交互来学习最优策略的深度Q网络。本论文的重点在于评估深度Q网络的性能和作战适用性。
方法论首先通过一个影响图来定义作战问题,该图明确了资金决策、情报质量、对手实力和任务效用之间的概率关系与时间关系。环境状态根据情报有效性、对手进攻实力和防御实力来定义,每个状态均使用贝塔分布进行量化,其参数反映了优、中、差条件。通过模拟伯努利试验来评估针对三种网络能力的一组离散资金分配方案所产生的期望效用结果,从而生成一个“状态-行动-奖励”元组数据集。随后,该数据集既用于训练神经网络基线模型,也作为深度Q网络的训练环境。
深度Q网络使用PyTorch实现,并依据强化学习原理进行训练。状态空间由情报和对手参数构成,而行动空间则由资金分配方案构成。模型通过在模拟环境中探索资金决策进行学习,更新其策略以最大化期望效用。为确保稳健学习,模型采用了经验回放和目标网络。
结果表明,深度Q网络能够有效地学习针对每个作战场景定制最优资金策略。与决策理论资金策略相比,深度Q网络实现了0.10的平均绝对误差和0.997的ℝ2值,表明其具有极佳的预测保真度。在±0.2的效用容差下,该模型实现了约88%的平均准确率;在±0.3的容差下,准确率超过95%。误差分布分析揭示了一个轻微的高估偏差,特别是在对手较弱且情报中等的情景中。尽管如此,总体误差分布仍集中在零附近。
在作战层面,深度Q网络展现了适应性和合理的决策能力。在情报良好且对手强大的情景中,深度Q网络建议在进攻性网络作战和防御性网络作战-响应行动之间进行近乎均等的分配,保持一种进取而平衡的态势。随着情报质量下降和对手实力减弱,模型将资金从进攻性网络作战转向防御性行动,特别是防御性网络作战-内部防御措施,在不确定性高时强调防御和恢复能力。示例建议表明,该模型能够动态调整策略,提供与作战优先事项相一致的可操作性指导。
研究确定了若干可改进的领域。误差偏差表明存在通过改进奖励塑造或在更多样化的场景上训练来提高校准度的机会。状态空间和行动空间为便于处理进行了离散化处理,限制了粒度;未来模型可采用连续的状态和行动表示以提高保真度。此外,纳入时间依赖性以建模随时间推移的序列决策,将能更好地反映现实世界的作战行动。最后,利用机密或作战数据进行验证,以及在训练过程中纳入人在回路的反馈,可增强模型的相关性和可靠性。
总之,本研究证明,基于深度Q网络的决策支持工具在对抗性和不确定环境中优化网络资金决策方面具有显著前景。通过从模拟交互中学习,深度Q网络优于神经网络基线,并展现出与作战相关的适应性。指挥官可利用此类工具,为在不同条件下平衡攻防优先级的资源分配提供信息支持。未来工作应侧重于改进模型校准、扩展表示能力,并依据作战数据进行验证,以增强其实用性。
