
机器人检测对于打击虚假信息、维护社交媒体在线互动的真实性至关重要。然而,机器人在模仿真实账户和规避检测方面的复杂程度不断提升,使得检测系统与建模技术之间的博弈持续升级。本文提出一种基于结构信息原理的对抗性框架SIAMD,用于对机器人行为进行建模并实现主动检测。该框架首先将用户账户与社交消息之间的多关系交互组织为统一的异质结构,引入结构熵量化历史活动中固有的不确定性。通过最小化高维熵,揭示账户社区内的分层结构,为机器人账户的行为建模提供活动判定和账户选择依据。针对每个建模机器人及其选定账户,SIAMD提取历史消息和用户描述构建提示词,并结合大语言模型生成相关消息内容。通过在原始异质网络中嵌入合成消息节点并建立多关系交互,SIAMD实现网络结构与内容的协同演化,从而以对抗方式增强基于图的主动检测能力。在多个真实世界数据集上的大量对比实验表明,SIAMD在有效性、泛化性、鲁棒性和可解释性方面显著且持续优于当前最先进的社交机器人检测基线模型。

论文标题: Proactive Bot Detection Based on Structural Information Principles 论文链接: https://ieeexplore.ieee.org/document/11311341 代码链接: https://github.com/SELGroup/SIAMD
一、对抗性检测架构
SIAMD架构包括四个主要阶段:社交网络分析、网络结构演化、网络内容演化和机器人检测优化,在上图中分别表示为阶段 I、阶段 II、阶段 III 和阶段 IV。 阶段 I:社交网络分析
- 提取用户账户和社交消息之间的各种类型的历史交互,构建异质网络。然后预训练一个图神经网络来区分机器人账户和人类账户,该网络将在后续演化阶段中用作黑箱检测器。
阶段 II:结构演化
- 利用异质交互中固有的结构信息,分析用户账户的网络影响力和行为相关性,并对多个机器人账户的未来行为进行建模。在这个阶段,我们为机器人账户定义了两个行为目标:(1)通过规避黑箱检测系统来最小化检测概率;(2)最大化其消息在账户间的传播,以扩大网络影响力。
阶段 III:内容演化
- 解析每个建模行为的机器人账户、交互类型和目标账户,构建提示词,并利用大语言模型生成与建模行为相关的消息内容。在异质网络中,将生成的消息作为新顶点添加,并根据交互类型将其与建模机器人和目标账户连接,从而更新网络结构和内容。
阶段 IV:检测优化
- 在更新后的异质网络上微调机器人检测器,以最大化其识别机器人账户的预测概率,以对抗方式对齐行为建模的目标。每次迭代优化后,优化后的模型将用作下一次迭代行为建模中的黑箱检测器,逐步提高主动检测性能。
二、SIAMD 框架设计
SIAMD 框架包括四个主要模块:社交网络分析、网络结构演化、网络内容演化和对抗性机器人检测。
A. 社交网络分析
为保留社交消息和用户账户之间历史交互中嵌入的原始信息,我们将这些社交元素组织为统一的异质图。该结构整合了各种类型的顶点(代表账户和消息)和边(表示不同类型的交互),用来准确反映社交交互的复杂性。通过将这些顶点类型之间的典型关系序列定义为元路径实例,在多关系图结构中建模账户之间的多类型关系。此外,对账户描述和消息内容进行嵌入,以获得能够捕获账户和消息的基本语义和结构特征的表示。
上图中的社交网络表示为从社交消息 M 和用户账户 U 之间的历史交互中提取的异质图 Gₕ 。边集 Eₕ 捕获用户参与的常见交互,包括发布、转发、提及、回复和关注。对于每条消息 m∈M ,使用预训练的文本嵌入模型将原始消息文本转换为密集向量表示 xₘ∈Xₘ。对于每个账户 u∈U,分别从用户描述中提取其分类特征和数值特征,并将它们连接成综合特征表示 xᵤ∈Xᵤ。 为保留社交元素之间存在的异质信息,将网络 Gₕ 映射到表示账户顶点的非负加权多关系图 Gₘ=(U, Xᵤ, {Eᵂᵣ}ᵣ∈R, W)。如果消息顶点通过 Gₕ 中的不同交互与账户 uᵢ 和 uⱼ 相关联,则在 Gₘ 中建立相应的多关系边以反映这些交互。将元路径定义为 Gₕ 中顶点类型和边类型的特定序列,从而构建关系集 R={f, m, rt, rp}。每种关系下的不同边集定义如下:
其中 、、、、 分别表示异质网络 Gₕ 中关注、发布、提及、转发和回复关系的邻接矩阵。对于每条边 eᵣᵢⱼ∈Eᵂᵣ ,分配一个归一化值作为其权重,计算如下:
B. 多关系结构熵
将同质结构信息原理分别应用于每种用户关系,然后求和得到的不确定性,隐含地将这些关系视为独立的。这种独立性假设使得该方法无法建模不同社交关系类型之间的联合效应和相互依赖关系。为解决这个问题,我们在多关系加权账户图上定义了一种随机游走,其中转移概率由所有可用的关系类型共同决定。这种构造产生了一个关于用户的单一马尔可夫链,具有独特的平稳分布,从中我们推导出多关系结构熵的一维度量。然后提出一种优化算法,通过在编码树上应用精心设计的算子来最小化这种熵,使模型能够利用关系之间的交互,同时保持紧凑的结构表示。
**1. 转移概率量化
对于多关系账户图 Gₘ ,首先应用调整算法以确保每个单关系子图 Gᵣₘ 内的强连通性。具体而言,对于每种关系类型 r∈R ,确保任意一对账户之间在关系 r 下存在有向路径。为实现这一点,提取每个单关系子图 Gᵣₘ(算法 1 的第 4 行),计算其强连通分量 Cᵣ(算法 1 的第 5 行),然后在这些分量之间添加具有小权重的有向边,形成有向环(算法 1 的第 6-10 行)。这保证了调整后的每个 Gᵣₘ 都是强连通的。
将调整后的图 G'ₘ 的邻接张量表示为 ,其中每个元素 Aᵢⱼᵣₘ表示账户 uᵢ∈U 到 uⱼ∈U 在关系 r∈R 下的非负权重有向边。在 G'ₘ 上进行单步随机游走时,通过关系 r 从 uᵢ 移动到 uⱼ 的概率分解如下:
其中 p (uⱼ|r, uᵢ) 表示给定当前账户 uᵢ和关系 r 时转移到 uⱼ的概率,p (r|uᵢ) 是在 uᵢ处选择关系 r 的概率,p (uᵢ) 是位于账户 uᵢ的先验概率。 定理 1:给定 中账户间随机游走的转移矩阵 (P),平稳分布 存在且唯一。该分布等同于矩阵 (P) 的最大特征值 1 对应的单一特征向量。
**2. 多关系熵定义
对于不可约同质图 ,一维结构熵 可以用顶点 V 上的平稳分布 表示为:
其中 是顶点 的平稳概率。 类似地, 的一维多关系结构熵使用账户 上的平稳分布 定义如下:
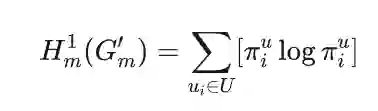
其中 是账户 在分布 中的平稳概率。 基于捕获 中关系动态的转移张量 和 ,调整公式 4 中的项 和 。这种调整允许我们考虑更新后的关系动态,从而重新定义分配的熵 为:
因此,重新定义 的 维多关系结构熵如下:
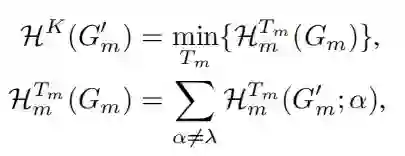
其中 遍历 的所有最大高度为 的编码树。
**3. 多关系熵优化
为最小化高维多关系结构熵 ,采用 deDoc 算法中的合并 和组合 算子,迭代优化账户图 的编码树 ,如下图所示。
引入项 以方便计算优化过程中多关系熵 的变化,定义如下:
其中 和 表示节点 和 对应的账户子集, 表示连接子集 和 中账户的多关系边的加权和。 当在兄弟节点 和 之间执行合并操作时,创建一个新的树节点 来替换 和 。具体而言, 和 的父节点被分配为 的父节点, 和 的子节点被映射到 的子节点。相关的熵变化 计算如下:
其中 表示通过合并节点 和 创建的新节点。 相反,当在兄弟节点 和 之间执行组合操作时,生成一个新的树节点 作为 和 的父节点,但 和 都不会被删除。具体而言, 和 的父节点被重新分配给 ,而 的父节点成为 和 的原始父节点。相关的熵变化 计算如下:
其中 表示通过组合节点 和 创建的新节点。
C. 网络结构演化
本小节将网络结构的演化分解为两个关键任务:社交活动判定和目标账户选择。然后采用多智能体强化学习模拟每个账户社区内的未来交互,从而更准确、高效地建模机器人行为。默认情况下,在由树 的根节点的子节点 表示的每个社区 中,随机采样 个机器人账户作为建模机器人账户,表示为 。
**1. 社交活动判定
活动判定问题被表述为马尔可夫决策过程(MDP),用元组 表示,其中 是状态空间, 是动作空间, 是奖励函数, 是转移函数, 是折扣因子。 在账户社区 U_λᵢ 内,高层策略 πₕ: Sₕ×Aₕ→[0,1] 负责确定每个建模机器人 bⱼ 应参与哪种类型的交互 r∈R。在每个时间步 t,高层状态 sₜʰ∈Sₕ 表示所有目标机器人执行的历史交互的快照。为减轻随时间增长的计算和空间开销,定义条件分布对历史活动序列进行编码,该分布表示每个机器人 bⱼ 选择特定交互类型 r∈R 的概率。然后使用该分布构建高层状态 sₜʰ∈R^k|R|。给定高层状态 sₜʰ ,策略 πₕ 选择动作 aₜʰ∈Aₕ,表示为二进制张量 。该张量确定每个目标机器人 bⱼ在时间步 t 的交互类型 rⱼᵗ。 相关奖励 旨在反映黑箱机器人检测器 对所有建模机器人的机器人检测结果的预测概率变化。奖励计算如下:
其中 和 是异质网络 的更新特征表示,反映了网络结构和内容演化引起的最新变化。 为建模规避机器人检测的行为目标,优化高层策略 以最大化长期期望折扣奖励。这涉及为建模机器人选择适当的交互类型,以降低机器人检测器 的预测概率。优化目标形式化如下:
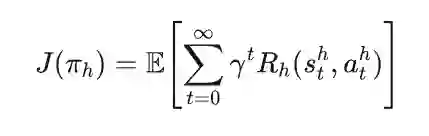
- 目标账户选择 目标账户选择问题被建模为多智能体 MDP,用元组 表示,其中 是建模机器人(智能体)集合, 是状态空间, 是动作空间, 是奖励函数。转移函数 和折扣因子与高层 相同。 在账户社区 内,低层策略 确定建模机器人 通过高层策略 选择的交互类型 与哪个人类或机器人账户连接。当策略 选择目标账户时,考虑每个用户账户的两个主要因素:
网络影响力:网络影响力越大的用户账户被选中的概率越高。 * 行为相关性:与机器人 行为相关性越大的用户账户被选中的可能性越高。
为量化这些因素,为每个账户 定义两个关键指标: 和 。这些指标基于多关系熵,量化 的网络影响力及其与 的行为相关性。计算如下:
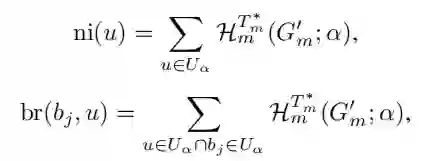
其中 表示确定账户 在随机交互中的参与程度所需的比特数,反映其网络影响力。另一方面, 表示 和 在随机交互中的参与模式之间的共享比特数,表明账户 与机器人 的行为相关性。 通过将这些指标融入社区 U_λᵢv诱导的子图的结构嵌入中,构建时间步 t 的低层状态 sₜˡ∈Sₗ。对于每个账户 u∈U_λᵢ,状态 sₜˡ∈R^|U_λᵢ|(d+2) 包括影响力指标 ni (u)、相关性指标 br (bⱼ, u)(每个大小为 1)以及使用无监督编码方法 node2vec 获得的大小为 d 的顶点嵌入。基于此低层状态 sₜˡ,建模机器人 bⱼ的策略 选择目标账户 以建立新的类型 r 的交互,表示为大小为 的独热动作 。 低层奖励 定义为所有建模机器人的影响力指标之和,给出如下:
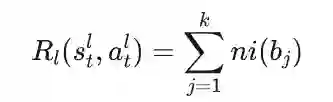
其中 表示建模机器人 的网络影响力。 为建模最大化所有建模机器人总影响力的行为目标,优化多智能体低层策略 (\pi_l),优化目标形式化如下:
D. 网络内容演化 利用演化后的网络结构,识别建模机器人、目标账户和交互类型,构建相关且上下文适当的提示词。然后使用这些提示词由大型语言模型(LLMs)生成消息内容。在异质社交网络中,引入带有生成内容的新消息顶点,并建立建模机器人与其目标账户之间的交互,从而模拟网络在结构和内容上的动态演化。 我们将用户元数据、历史内容和社交结构整合到基于提示词的方法中,使 LLMs 能够生成上下文准确且相关的预测。如图 6 所示,该过程包括三个阶段:背景表示、任务表述和通过上下文学习生成内容。
为了让 LLMs 充分理解账户档案和交互,受先前在自然语言输入中利用结构化数据的工作的启发,从三个维度表示背景知识: * 元数据:将账户的分类信息(包括关注者数量、关注数量和账户描述)重新表述为自然语言序列。 * 内容:使用用户嵌入和基于相似度的文本检索技术,从每个机器人中识别出与目标账户的嵌入向量余弦相似度最高的三条推文。 * 结构:将每个账户的关注和被关注关系编码为自然语言列表,因为研究表明基于图的表示在社交网络任务中具有实用性。
预测任务表述简洁,最大限度地减少不必要的重复,并有效利用背景知识为生成模型创建清晰且有针对性的指令。例如,任务可能被表述为:“任务:根据账户 [发送者] 和账户 [接收者] 过去的交互和上下文信息,生成账户 [发送者] 最有可能发送给账户 [接收者] 的 [交互类型] 类型消息。”
三、实验结果
为评估 SIAMD 框架的检测性能,使用来自 Bot Repository 的四个知名机器人数据集Cresci-15、Cresci-17、TwiBot-20 和 TwiBot-22进行对比实验。 将 SIAMD 的检测性能与三类最先进的基线进行比较:基于特征的方法(包括 BotHunter 和 SGBot)、基于内容的方法(包括 BGSRD 和 RoBERTa)以及基于图的方法(如 GraphHist 、SATAR 、Botometer 、SimpleHGN 、BotRGCN 和 RGT)。
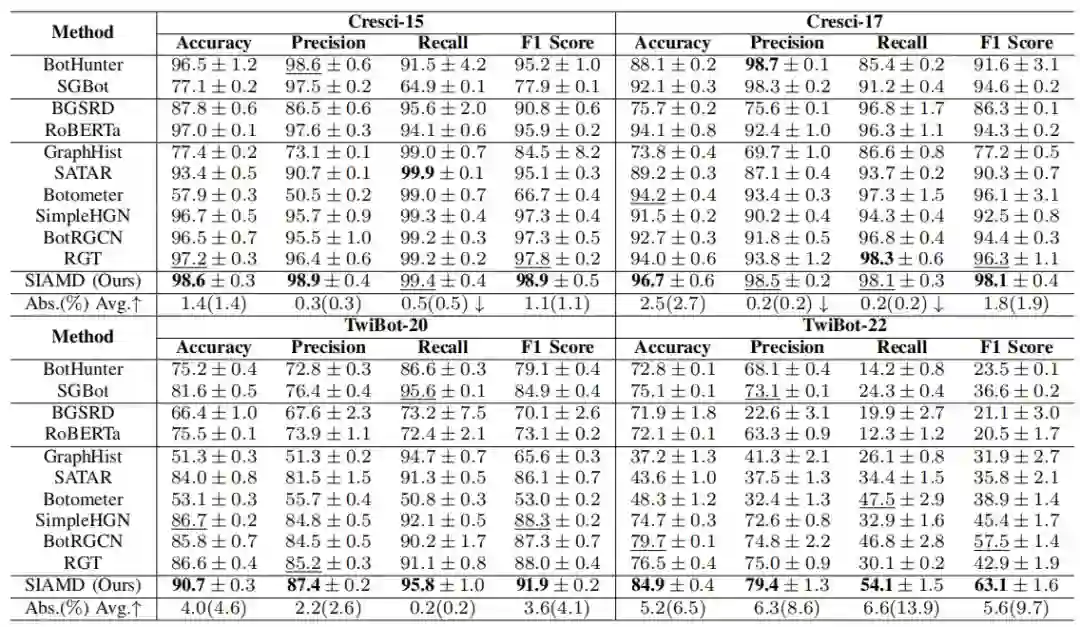
3.1 泛化能力
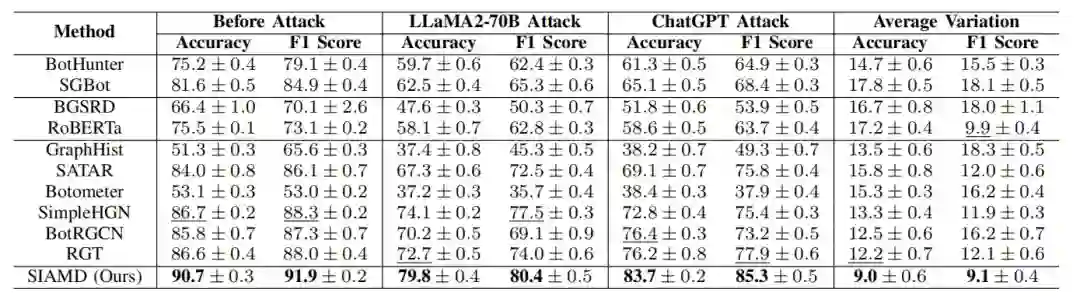
在 TwiBot-20 中经过 LLM 操纵的机器人账户上,评估了 SIAMD 框架和所有基线方法的准确率和 F1 分数检测性能,结果如上表所示。与先前工作中的观察结果一致,使用 LLaMA2-70B 模型进行的对抗性操纵导致基于特征、基于内容和基于图的检测器的性能下降更大。与其他基线模型相比,SIAMD 在两种攻击场景中始终实现最高的检测准确率和 F1 分数,同时表现出最小的性能下降。SIAMD 框架中的对抗性检测机制主动模拟网络结构和内容中潜在的干扰场景,从而增强了其检测鲁棒性。
3.2 可解释性
为了验证 SIAMD 的可解释性,从 TwiBot-22 网络中提取一个子社区,对三个机器人账户的行为进行建模(用不同颜色表示),并可视化它们在不同时间步的子社区内的结构关系,如下图所示。为清晰起见,仅可视化子社区内账户之间的有向交互,省略了特定的交互类型。还通过在各自的子图中采用不同的颜色和更粗的边来突出显示三个机器人账户的建模行为。
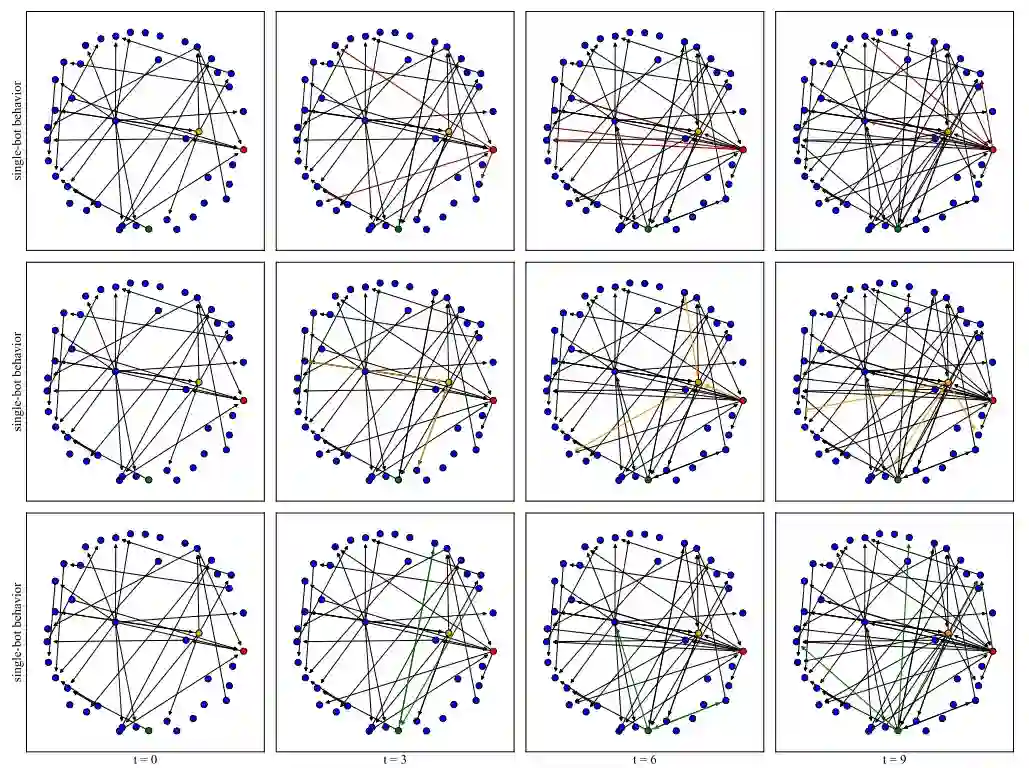
红色机器人主要关注或转发原始子社区内的其他账户,很少表达自己的观点。因此,检测算法将其分类为人类账户。它经常回复和提及其他账户,特别是网络中影响力较低的账户。黄色机器人账户更有可能在子社区内表达自己的观点以影响公众舆论,导致其被分类为机器人账户。在原始社区中,绿色机器人参与的社交交互较少,表现出的行为模式也较少,导致其被分类为人类账户。这类账户主要模仿人类账户的行为,通过与他人的双向交互传播公众舆论。 此外,观察到三个机器人账户在选择交互目标账户时存在重叠。这是由于这些账户之间建模的协作关系,选择相同的交互目标可以提高舆论操纵的效果。
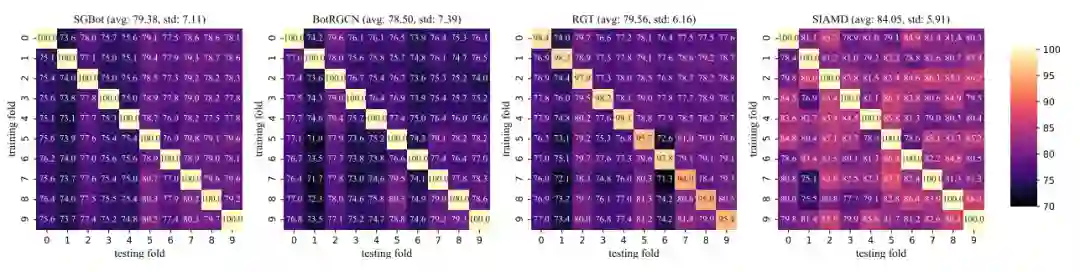
3.3 敏感性分析
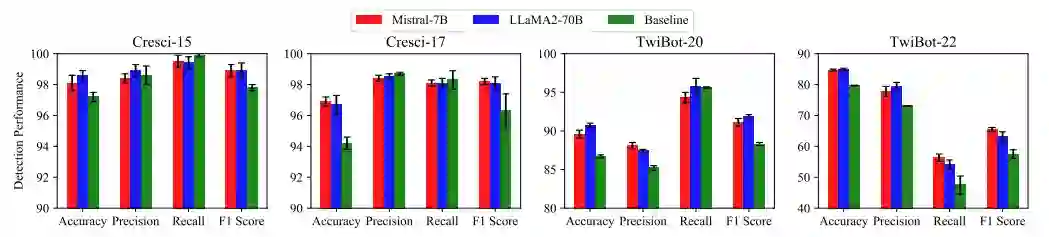
如上图所示,无论使用哪种模型,SIAMD 框架在所有数据集上始终表现出优越的检测性能,特别是在准确率和 F1 分数方面。尽管两个 SIAMD 变体在不同数据集上的性能有所不同,但它们相对于基线算法的优势仍然相当。这表明我们框架的有效性不依赖于任何特定的大语言模型。
3.4 消融实验
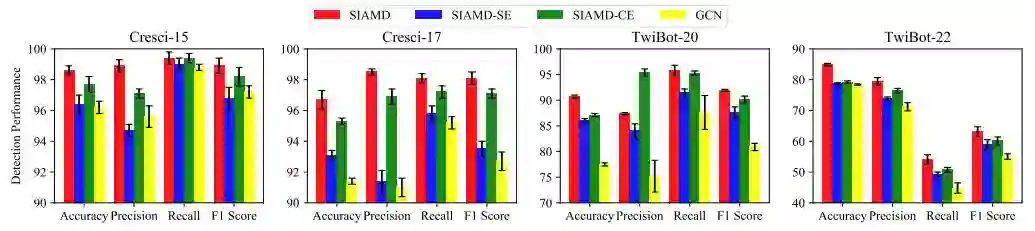
在所有数据集上,完整的 SIAMD 的检测性能优于其两个变体,而这两个变体又优于底层检测算法 GCN。这突出了对抗性架构和网络演化在提高检测性能方面的性能优势。此外,与 SIAMD-SE 相比,SIAMD-CE 变体表现出明显更好的性能,强调了基于结构信息原理的行为建模在框架中的关键作用。