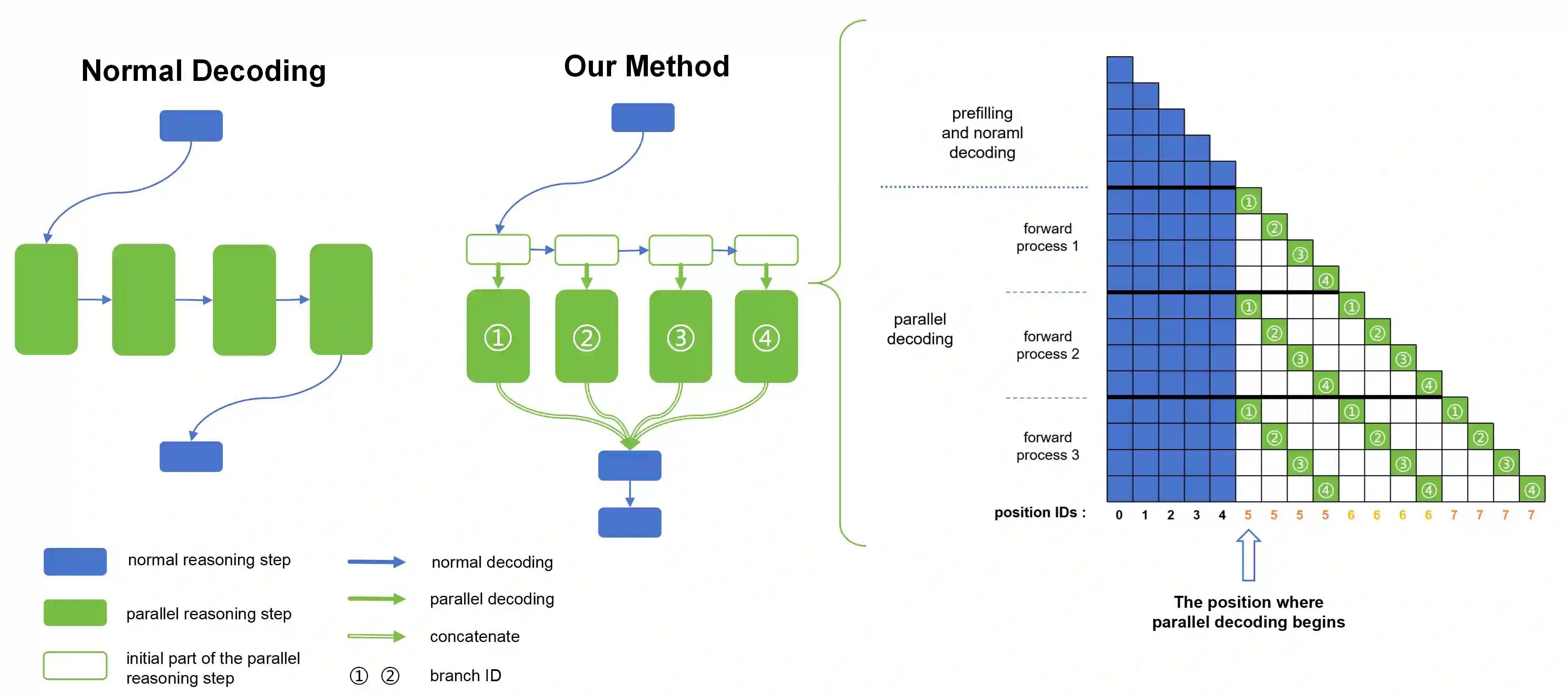
Recent advances in reasoning models have demonstrated significant improvements in accuracy, particularly for complex tasks such as mathematical reasoning, by employing detailed and comprehensive reasoning processes. However, generating these lengthy reasoning sequences is computationally expensive and time-consuming. To address this inefficiency, we leverage the inherent parallelizability of certain tasks to accelerate the reasoning process. Specifically, when multiple parallel reasoning branches exist, we decode multiple tokens per step using a specialized attention mask, processing them within a single sequence, avoiding additional memory usage. Experimental results show that our method achieves over 100% speedup in decoding time while maintaining the answer quality.
翻译:近期推理模型通过采用详尽全面的推理过程,在准确性方面取得了显著提升,尤其在数学推理等复杂任务上表现突出。然而,生成这些冗长的推理序列计算成本高昂且耗时。为解决这一效率瓶颈,我们利用特定任务固有的可并行性来加速推理过程。具体而言,当存在多个并行推理分支时,我们通过专用注意力掩码在单步内解码多个标记,并将其处理于同一序列中,从而避免额外的内存开销。实验结果表明,该方法在保持答案质量的同时,实现了超过100%的解码时间加速。