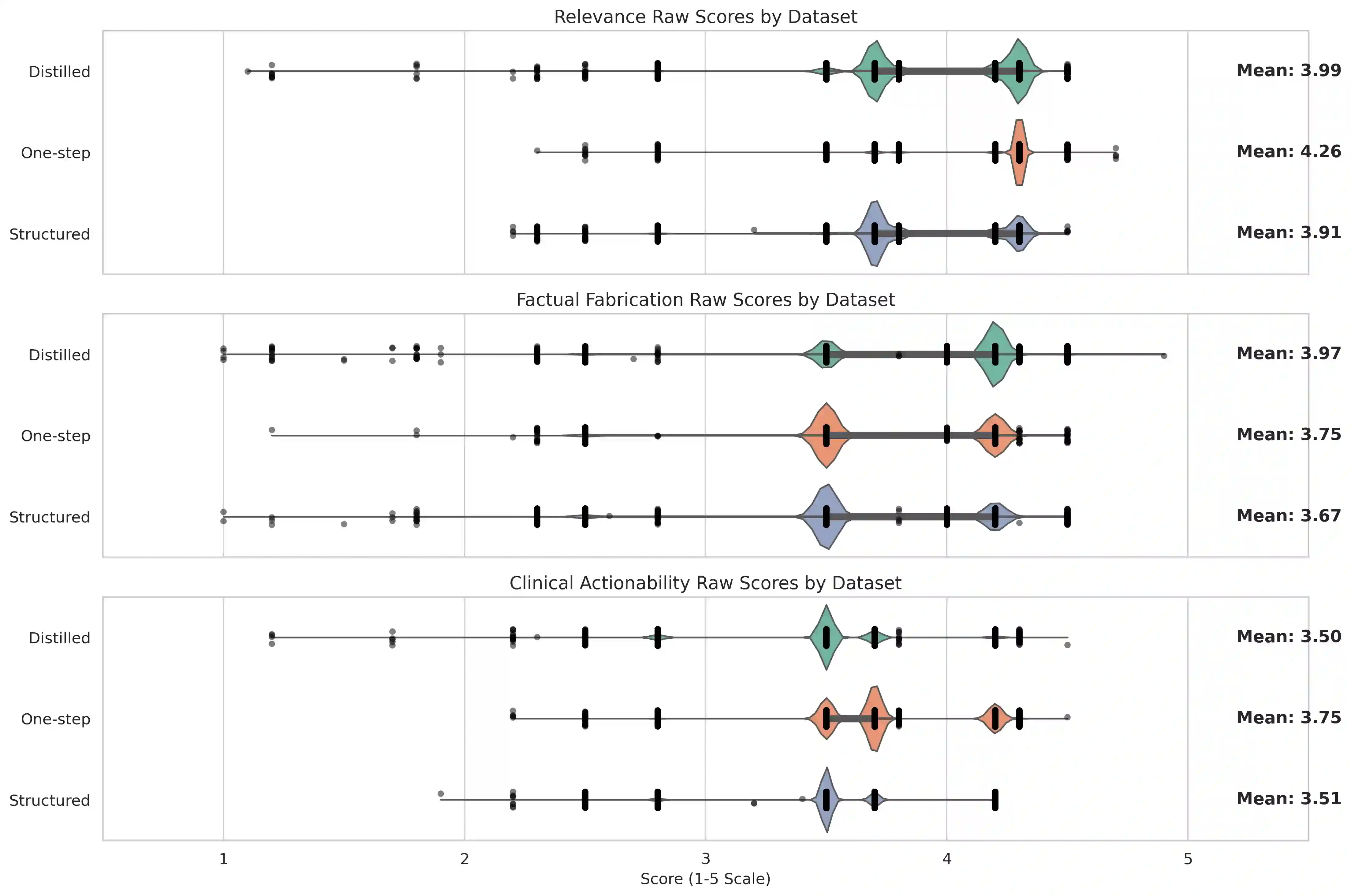
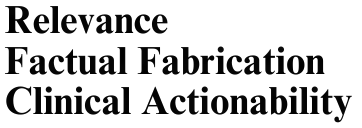Large language models (LLMs) are increasingly used to generate summaries from clinical notes. However, their ability to preserve essential diagnostic information remains underexplored, which could lead to serious risks for patient care. This study introduces DistillNote, an evaluation framework for LLM summaries that targets their functional utility by applying the generated summary downstream in a complex clinical prediction task, explicitly quantifying how much prediction signal is retained. We generated over 192,000 LLM summaries from MIMIC-IV clinical notes with increasing compression rates: standard, section-wise, and distilled section-wise. Heart failure diagnosis was chosen as the prediction task, as it requires integrating a wide range of clinical signals. LLMs were fine-tuned on both the original notes and their summaries, and their diagnostic performance was compared using the AUROC metric. We contrasted DistillNote's results with evaluations from LLM-as-judge and clinicians, assessing consistency across different evaluation methods. Summaries generated by LLMs maintained a strong level of heart failure diagnostic signal despite substantial compression. Models trained on the most condensed summaries (about 20 times smaller) achieved an AUROC of 0.92, compared to 0.94 with the original note baseline (97 percent retention). Functional evaluation provided a new lens for medical summary assessment, emphasizing clinical utility as a key dimension of quality. DistillNote introduces a new scalable, task-based method for assessing the functional utility of LLM-generated clinical summaries. Our results detail compression-to-performance tradeoffs from LLM clinical summarization for the first time. The framework is designed to be adaptable to other prediction tasks and clinical domains, aiding data-driven decisions about deploying LLM summarizers in real-world healthcare settings.
翻译:大型语言模型(LLM)越来越多地用于从临床笔记生成摘要。然而,其保留关键诊断信息的能力仍未得到充分探索,这可能对患者护理造成严重风险。本研究提出了DistillNote,一个针对LLM摘要功能性效用的评估框架,通过将生成的摘要应用于复杂的临床预测任务中,明确量化保留了多少预测信号。我们从MIMIC-IV临床笔记中生成了超过192,000份LLM摘要,并逐步提高压缩率:标准摘要、分节摘要和精馏分节摘要。选择心力衰竭诊断作为预测任务,因其需要整合广泛的临床信号。我们在原始笔记及其摘要上对LLM进行微调,并使用AUROC指标比较其诊断性能。我们将DistillNote的结果与LLM作为评判者和临床医生的评估进行对比,评估不同评估方法之间的一致性。尽管压缩率大幅提高,LLM生成的摘要仍保持了较强的心力衰竭诊断信号。在最精简的摘要(约缩小20倍)上训练的模型达到了0.92的AUROC,而原始笔记基线为0.94(保留了97%的信号)。功能性评估为医学摘要评估提供了新视角,强调临床效用作为质量的关键维度。DistillNote引入了一种新的、可扩展的、基于任务的方法来评估LLM生成临床摘要的功能性效用。我们的结果首次详细阐述了LLM临床摘要化的压缩与性能权衡。该框架设计为可适应其他预测任务和临床领域,有助于在实际医疗环境中部署LLM摘要生成器时做出数据驱动的决策。