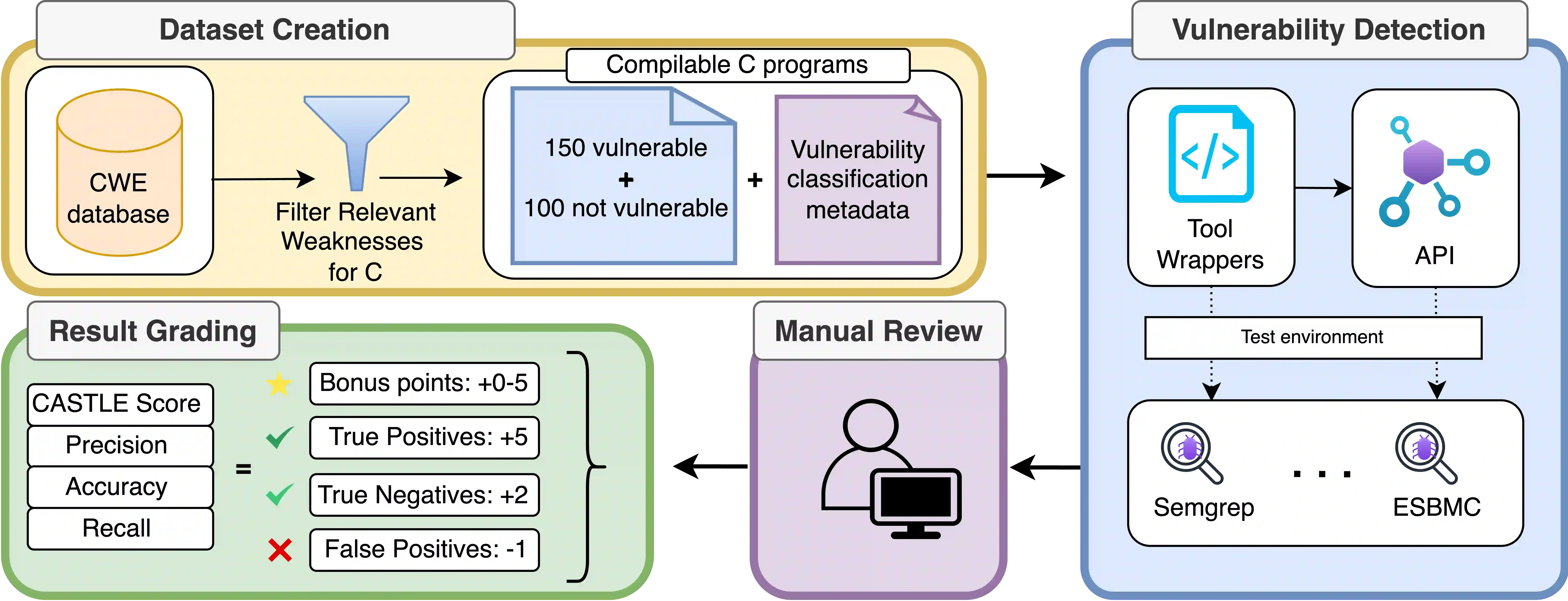
Identifying vulnerabilities in source code is crucial, especially in critical software components. Existing methods such as static analysis, dynamic analysis, formal verification, and recently Large Language Models are widely used to detect security flaws. This paper introduces CASTLE (CWE Automated Security Testing and Low-Level Evaluation), a benchmarking framework for evaluating the vulnerability detection capabilities of different methods. We assess 13 static analysis tools, 10 LLMs, and 2 formal verification tools using a hand-crafted dataset of 250 micro-benchmark programs covering 25 common CWEs. We propose the CASTLE Score, a novel evaluation metric to ensure fair comparison. Our results reveal key differences: ESBMC (a formal verification tool) minimizes false positives but struggles with vulnerabilities beyond model checking, such as weak cryptography or SQL injection. Static analyzers suffer from high false positives, increasing manual validation efforts for developers. LLMs perform exceptionally well in the CASTLE dataset when identifying vulnerabilities in small code snippets. However, their accuracy declines, and hallucinations increase as the code size grows. These results suggest that LLMs could play a pivotal role in future security solutions, particularly within code completion frameworks, where they can provide real-time guidance to prevent vulnerabilities. The dataset is accessible at https://github.com/CASTLE-Benchmark.
翻译:识别源代码中的漏洞至关重要,尤其在关键软件组件中。现有方法如静态分析、动态分析、形式化验证以及近期兴起的大型语言模型被广泛用于检测安全缺陷。本文提出CASTLE(CWE自动化安全测试与底层评估),这是一个用于评估不同方法漏洞检测能力的基准测试框架。我们使用包含25种常见CWE、由250个微基准程序组成的手工构建数据集,评估了13种静态分析工具、10种大型语言模型和2种形式化验证工具。我们提出了CASTLE分数这一新颖评估指标以确保公平比较。研究结果揭示了关键差异:ESBMC(一种形式化验证工具)能最小化误报,但在处理超出模型检查范围的漏洞(如弱加密或SQL注入)时存在困难。静态分析工具误报率高,增加了开发人员手动验证的工作量。大型语言模型在识别小规模代码片段中的漏洞时,在CASTLE数据集上表现优异。然而,随着代码规模增大,其准确率下降且幻觉现象增加。这些结果表明,大型语言模型可能在未来的安全解决方案中发挥关键作用,特别是在代码补全框架中,它们能够提供实时指导以预防漏洞。数据集可通过 https://github.com/CASTLE-Benchmark 访问。