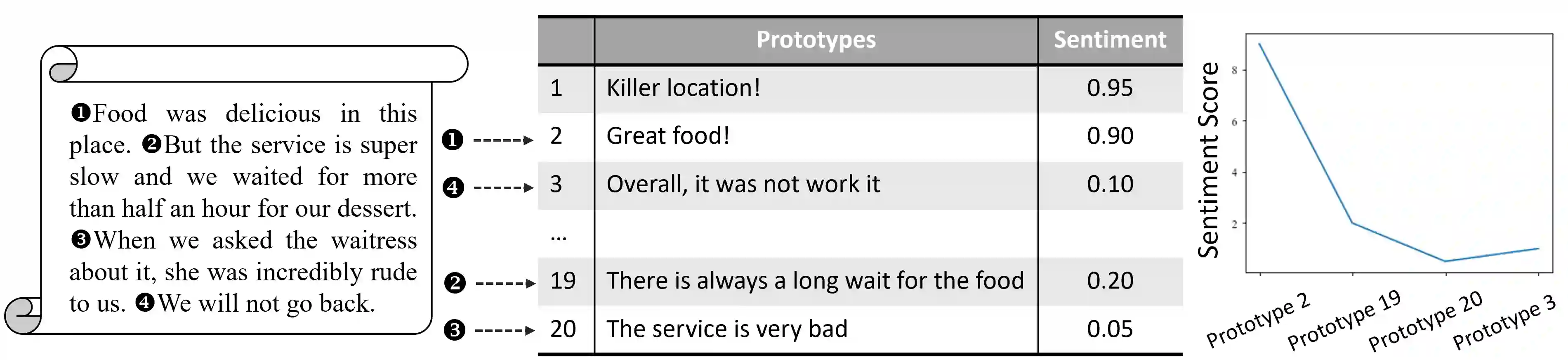
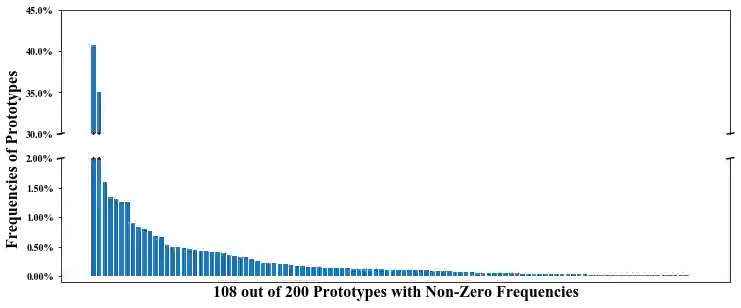
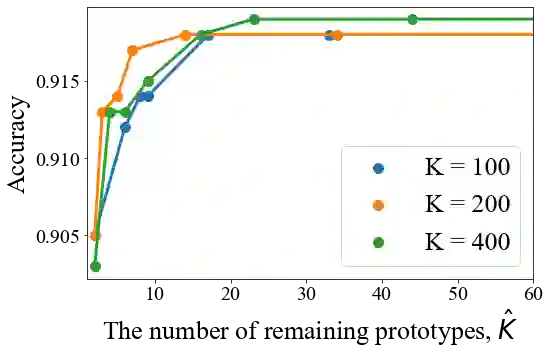
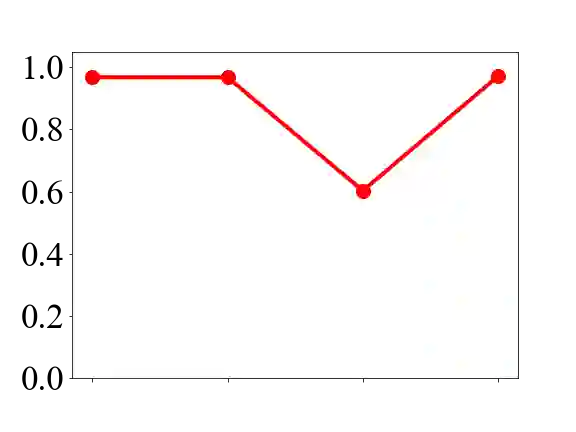
We propose a novel interpretable deep neural network for text classification, called ProtoryNet, based on a new concept of prototype trajectories. Motivated by the prototype theory in modern linguistics, ProtoryNet makes a prediction by finding the most similar prototype for each sentence in a text sequence and feeding an RNN backbone with the proximity of each sentence to the corresponding active prototype. The RNN backbone then captures the temporal pattern of the prototypes, which we refer to as prototype trajectories. Prototype trajectories enable intuitive and fine-grained interpretation of the reasoning process of the RNN model, in resemblance to how humans analyze texts. We also design a prototype pruning procedure to reduce the total number of prototypes used by the model for better interpretability. Experiments on multiple public data sets show that ProtoryNet is more accurate than the baseline prototype-based deep neural net and reduces the performance gap compared to state-of-the-art black-box models. In addition, after prototype pruning, the resulting ProtoryNet models only need less than or around 20 prototypes for all datasets, which significantly benefits interpretability. Furthermore, we report a survey result indicating that human users find ProtoryNet more intuitive and easier to understand than other prototype-based methods.
翻译:我们提出了一种新颖的可解释深度神经网络用于文本分类,称为ProtoryNet,其基于原型轨迹这一新概念。受现代语言学中原型理论的启发,ProtoryNet通过为文本序列中的每个句子找到最相似的原型,并将每个句子与对应激活原型的接近度输入到RNN主干网络中进行预测。RNN主干网络进而捕捉原型的时间模式,我们将其称为原型轨迹。原型轨迹能够直观且细粒度地解释RNN模型的推理过程,类似于人类分析文本的方式。我们还设计了一种原型剪枝程序,以减少模型使用的原型总数,从而提高可解释性。在多个公共数据集上的实验表明,ProtoryNet比基于原型的基线深度神经网络更准确,并缩小了与最先进黑箱模型的性能差距。此外,经过原型剪枝后,生成的ProtoryNet模型在所有数据集上仅需要少于或约20个原型,这显著提升了可解释性。进一步地,我们报告了一项调查结果,表明人工用户认为ProtoryNet比其他基于原型的方法更直观、更易于理解。