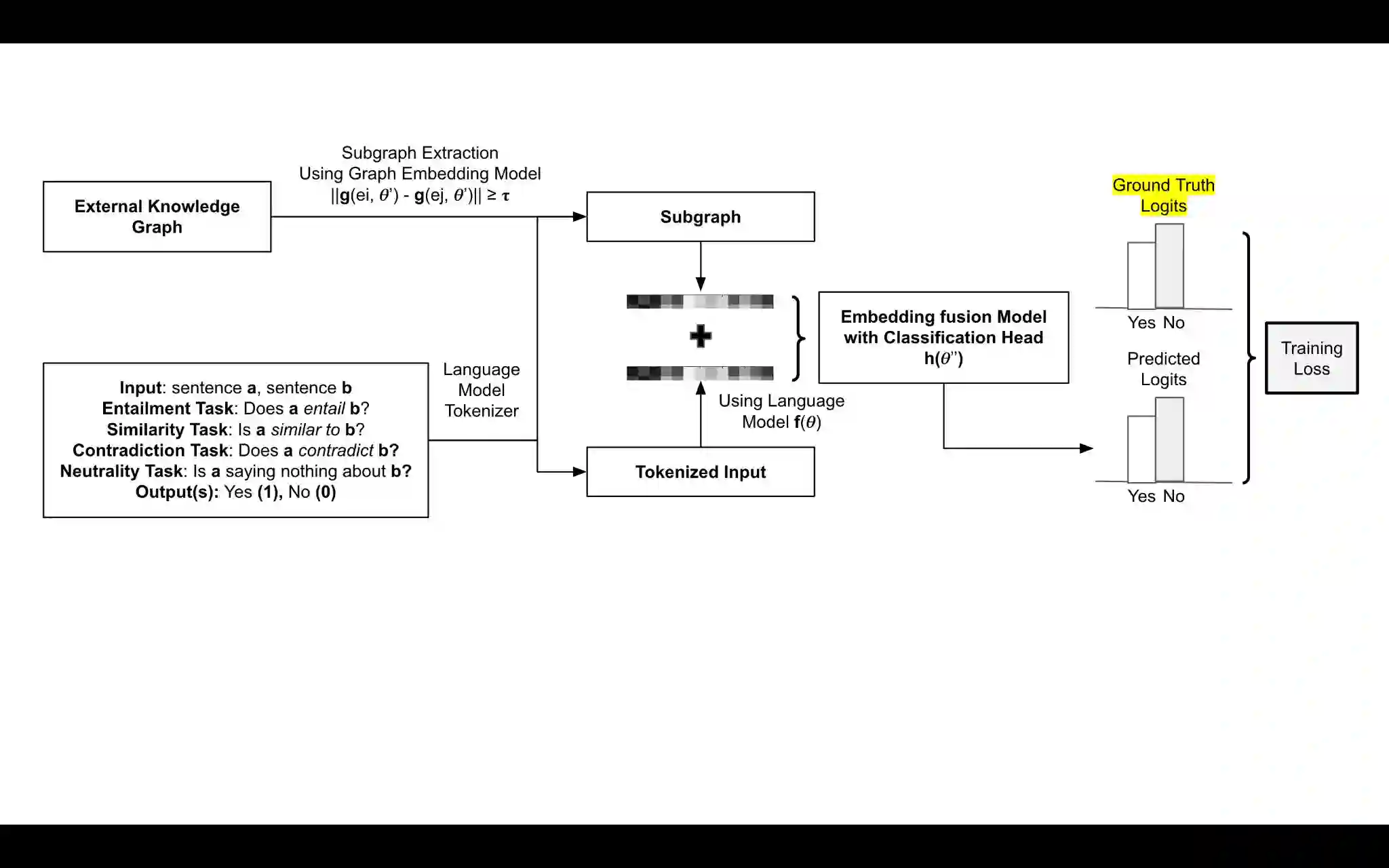
Natural language understanding (NLU) using neural network pipelines often requires additional context that is not solely present in the input data. Through Prior research, it has been evident that NLU benchmarks are susceptible to manipulation by neural models, wherein these models exploit statistical artifacts within the encoded external knowledge to artificially inflate performance metrics for downstream tasks. Our proposed approach, known as the Recap, Deliberate, and Respond (RDR) paradigm, addresses this issue by incorporating three distinct objectives within the neural network pipeline. Firstly, the Recap objective involves paraphrasing the input text using a paraphrasing model in order to summarize and encapsulate its essence. Secondly, the Deliberation objective entails encoding external graph information related to entities mentioned in the input text, utilizing a graph embedding model. Finally, the Respond objective employs a classification head model that utilizes representations from the Recap and Deliberation modules to generate the final prediction. By cascading these three models and minimizing a combined loss, we mitigate the potential for gaming the benchmark and establish a robust method for capturing the underlying semantic patterns, thus enabling accurate predictions. To evaluate the effectiveness of the RDR method, we conduct tests on multiple GLUE benchmark tasks. Our results demonstrate improved performance compared to competitive baselines, with an enhancement of up to 2\% on standard metrics. Furthermore, we analyze the observed evidence for semantic understanding exhibited by RDR models, emphasizing their ability to avoid gaming the benchmark and instead accurately capture the true underlying semantic patterns.
翻译:基于神经网络流水线的自然语言理解通常需要输入数据中不直接存在的额外上下文。先前研究表明,NLU基准测试易受神经模型操控——这些模型利用编码外部知识中的统计伪影,人为提升下游任务的性能指标。我们提出的"回顾、深思与回应"范式通过引入三个不同目标来解决该问题。首先,"回顾"目标通过释义模型对输入文本进行重述,以概括并凝练其核心要义。其次,"深思"目标利用图嵌入模型对输入文本中提及实体相关的外部图结构信息进行编码。最后,"回应"目标采用分类头模型,基于"回顾"与"深思"模块生成的表征进行最终预测。通过串联这三个模型并最小化联合损失函数,我们有效抑制了基准测试操纵风险,构建了稳健的潜在语义模式捕获方法,从而实现精准预测。为评估RDR方法有效性,我们针对多个GLUE基准任务展开测试。结果表明,相较于竞争基线模型,本方法在标准指标上实现最高2%的性能提升。此外,我们分析了RDR模型表现出的语义理解证据,强调其避免基准测试操纵、准确捕获真实潜在语义模式的能力。