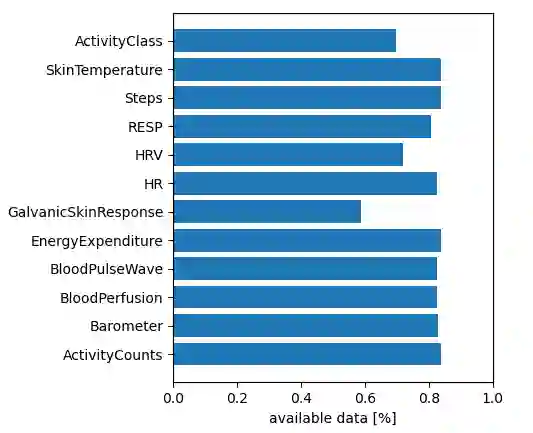
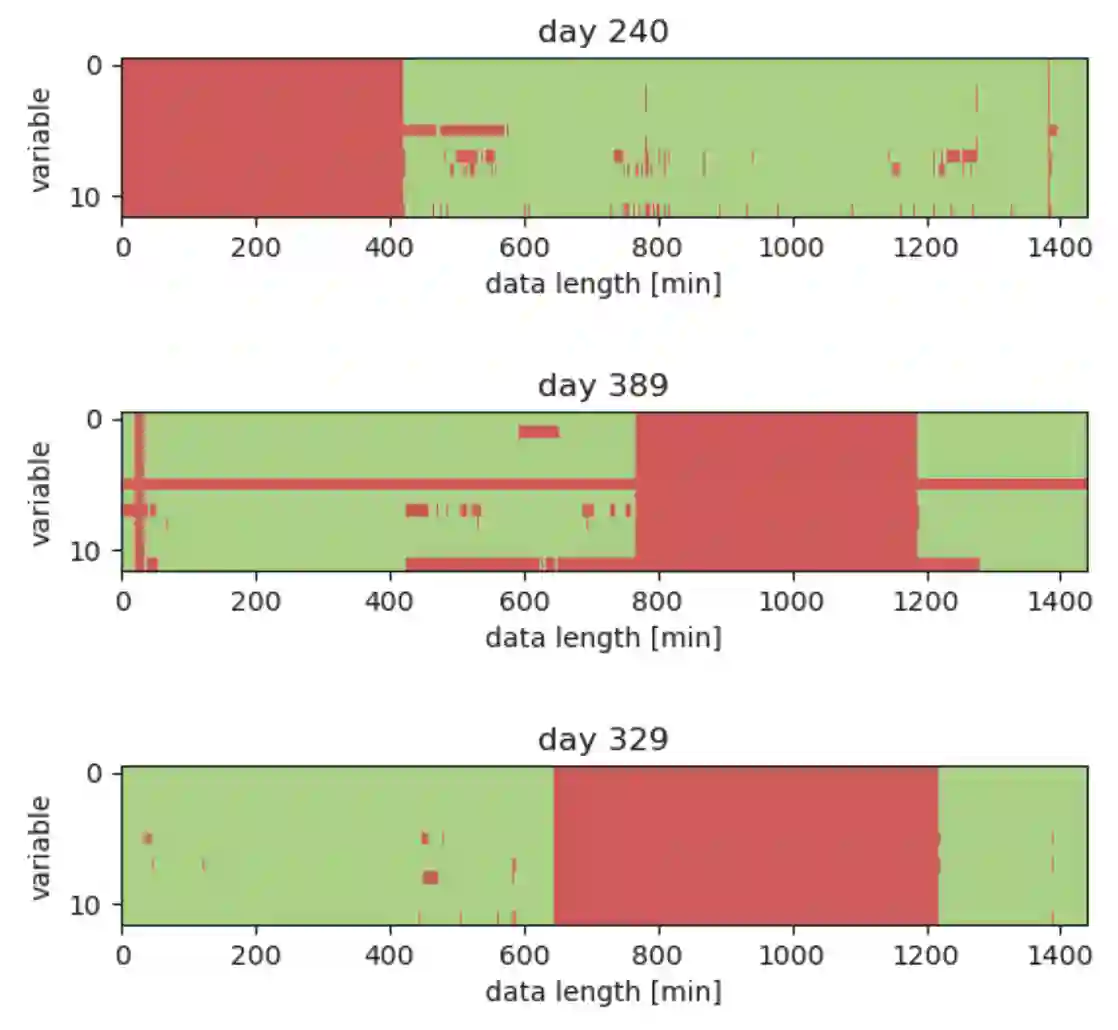
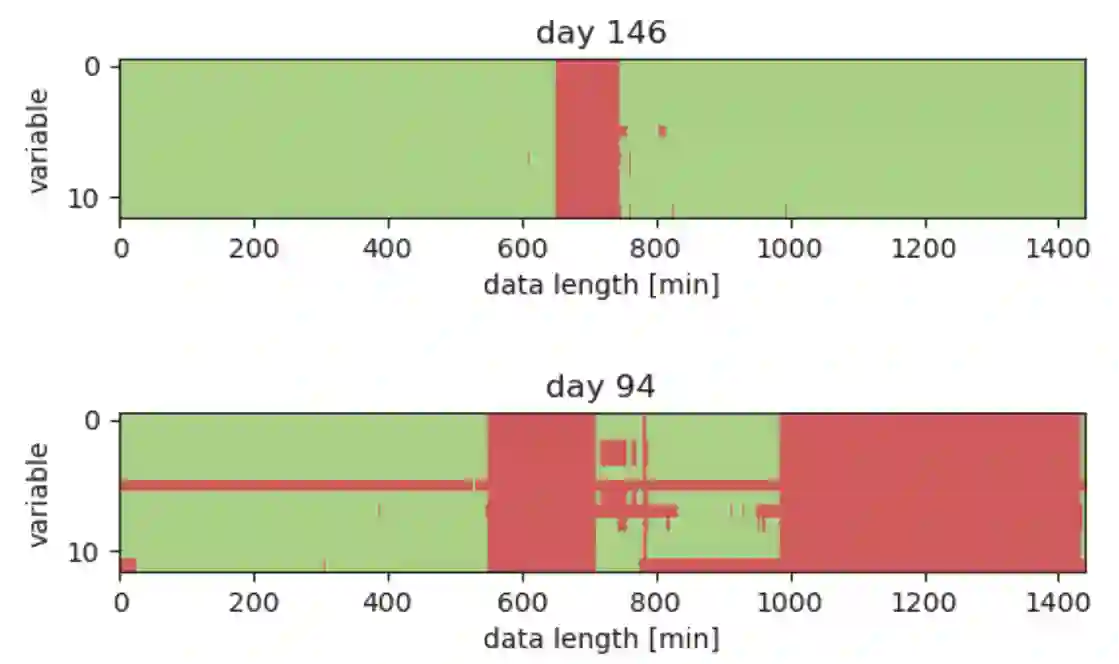
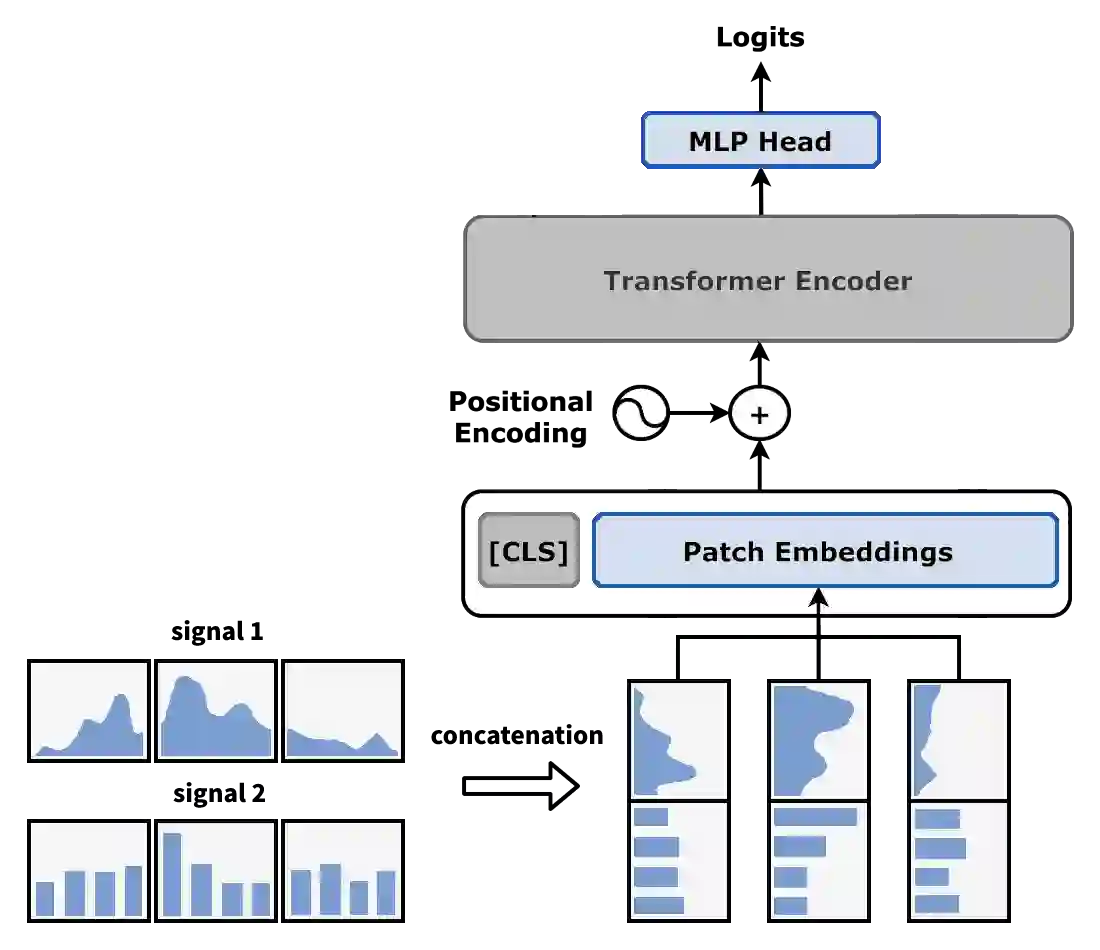
Wearable devices continuously collect sensor data and use it to infer an individual's behavior, such as sleep, physical activity, and emotions. Despite the significant interest and advancements in this field, modeling multimodal sensor data in real-world environments is still challenging due to low data quality and limited data annotations. In this work, we investigate representation learning for imputing missing wearable data and compare it with state-of-the-art statistical approaches. We investigate the performance of the transformer model on 10 physiological and behavioral signals with different masking ratios. Our results show that transformers outperform baselines for missing data imputation of signals that change more frequently, but not for monotonic signals. We further investigate the impact of imputation strategies and masking rations on downstream classification tasks. Our study provides insights for the design and development of masking-based self-supervised learning tasks and advocates the adoption of hybrid-based imputation strategies to address the challenge of missing data in wearable devices.
翻译:可穿戴设备持续采集传感器数据,并用于推断个体的睡眠、身体活动及情绪等行为状态。尽管该领域已取得显著进展与广泛关注,但由于数据质量低下和标注样本有限,在真实环境中对多模态传感器数据进行建模仍存在挑战。本研究探索了面向缺失可穿戴数据插补的表征学习方法,并将其与当前最优的统计学方法进行对比。我们采用Transformer模型对10种生理与行为信号在不同掩码比例下的表现进行验证。结果表明:对于变化频率较高的信号,Transformer在缺失数据插补任务中优于基线方法,但在单调信号场景中表现欠佳。我们进一步探究了插补策略与掩码比例对下游分类任务的影响。本研究为基于掩码的自监督学习任务设计开发提供了见解,并倡导采用混合式插补策略来解决可穿戴设备中的缺失数据问题。