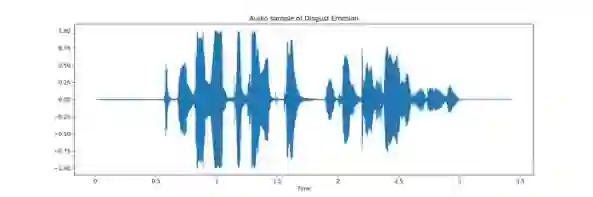
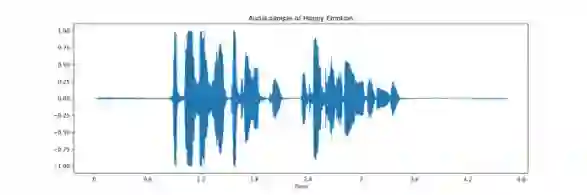
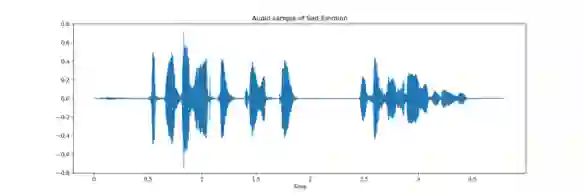
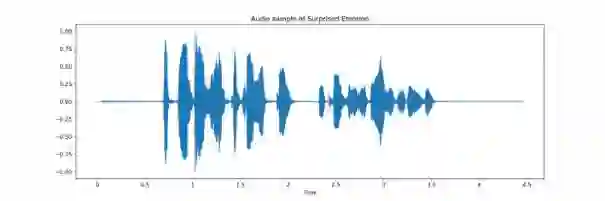
In the field of audio and speech analysis, the ability to identify emotions from acoustic signals is essential. Human-computer interaction (HCI) and behavioural analysis are only a few of the many areas where the capacity to distinguish emotions from speech signals has an extensive range of applications. Here, we are introducing BanSpEmo, a corpus of emotional speech that only consists of audio recordings and has been created specifically for the Bangla language. This corpus contains 792 audio recordings over a duration of more than 1 hour and 23 minutes. 22 native speakers took part in the recording of two sets of sentences that represent the six desired emotions. The data set consists of 12 Bangla sentences which are uttered in 6 emotions as Disgust, Happy, Sad, Surprised, Anger, and Fear. This corpus is not also gender balanced. Ten individuals who either have experience in related field or have acting experience took part in the assessment of this corpus. It has a balanced number of audio recordings in each emotion class. BanSpEmo can be considered as a useful resource to promote emotion and speech recognition research and related applications in the Bangla language. The dataset can be found here: https://data.mendeley.com/datasets/rdwn4bs5ky and might be employed for academic research.
翻译:在音频与语音分析领域,从声学信号中识别情感的能力至关重要。人机交互(HCI)及行为分析等众多领域均广泛应用从语音信号中区分情感的能力。本文介绍BanSpEmo——一个专门为孟加拉语构建的情感语音语料库,仅包含音频录音。该语料库包含792段音频,总时长超过1小时23分钟。22位母语者参与录制了两组代表六种目标情感的语句。数据集包含12句孟加拉语语句,以六种情感(厌恶、快乐、悲伤、惊讶、愤怒、恐惧)进行表达。该语料库未实现性别平衡。十位具备相关领域经验或表演经历的人士参与了该语料库的评估。每个情感类别的音频数量保持均衡。BanSpEmo可视为推动孟加拉语情感与语音识别研究及其应用的重要资源。数据集可通过以下链接获取:https://data.mendeley.com/datasets/rdwn4bs5ky,并可用于学术研究。