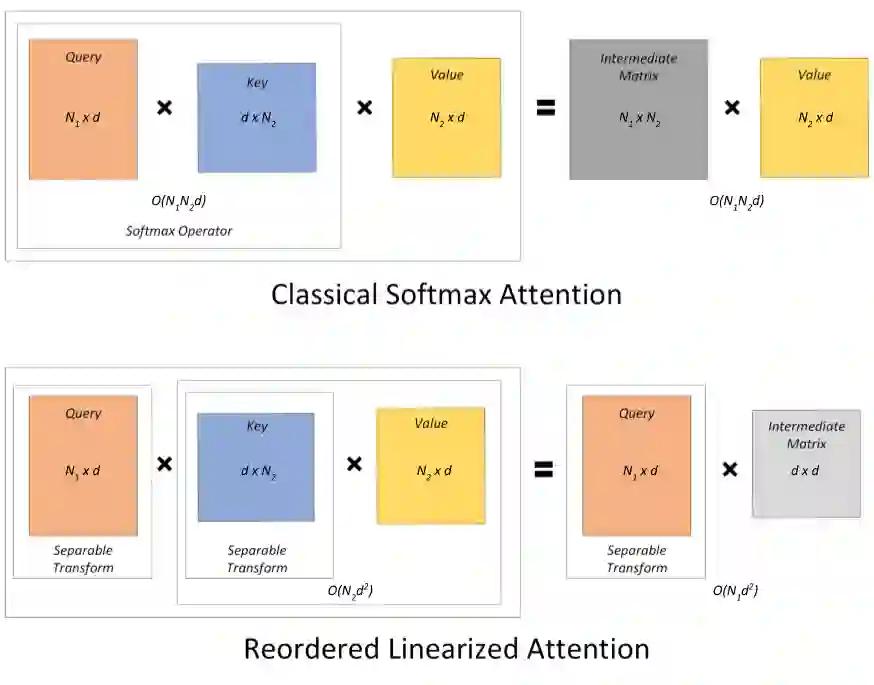
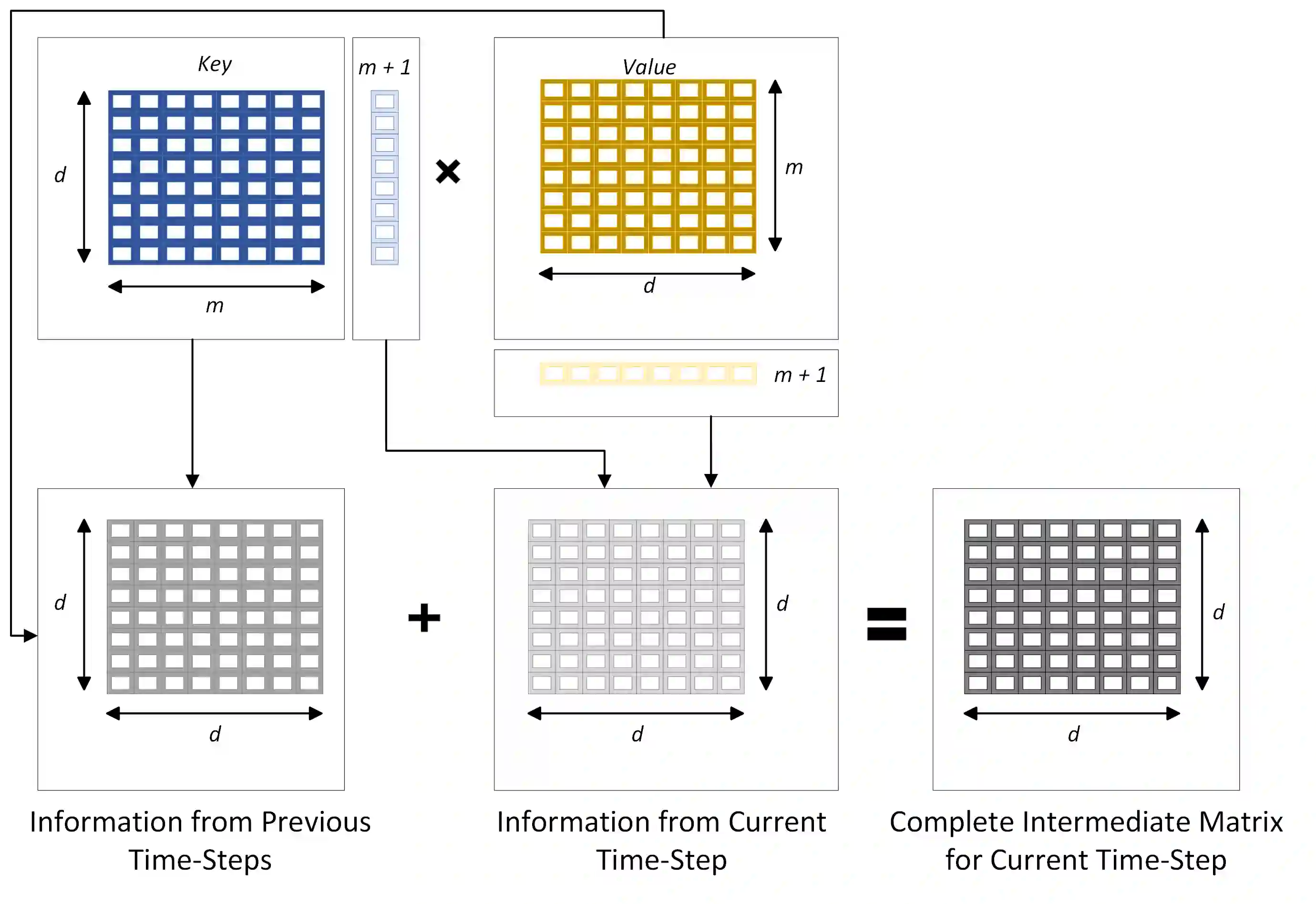
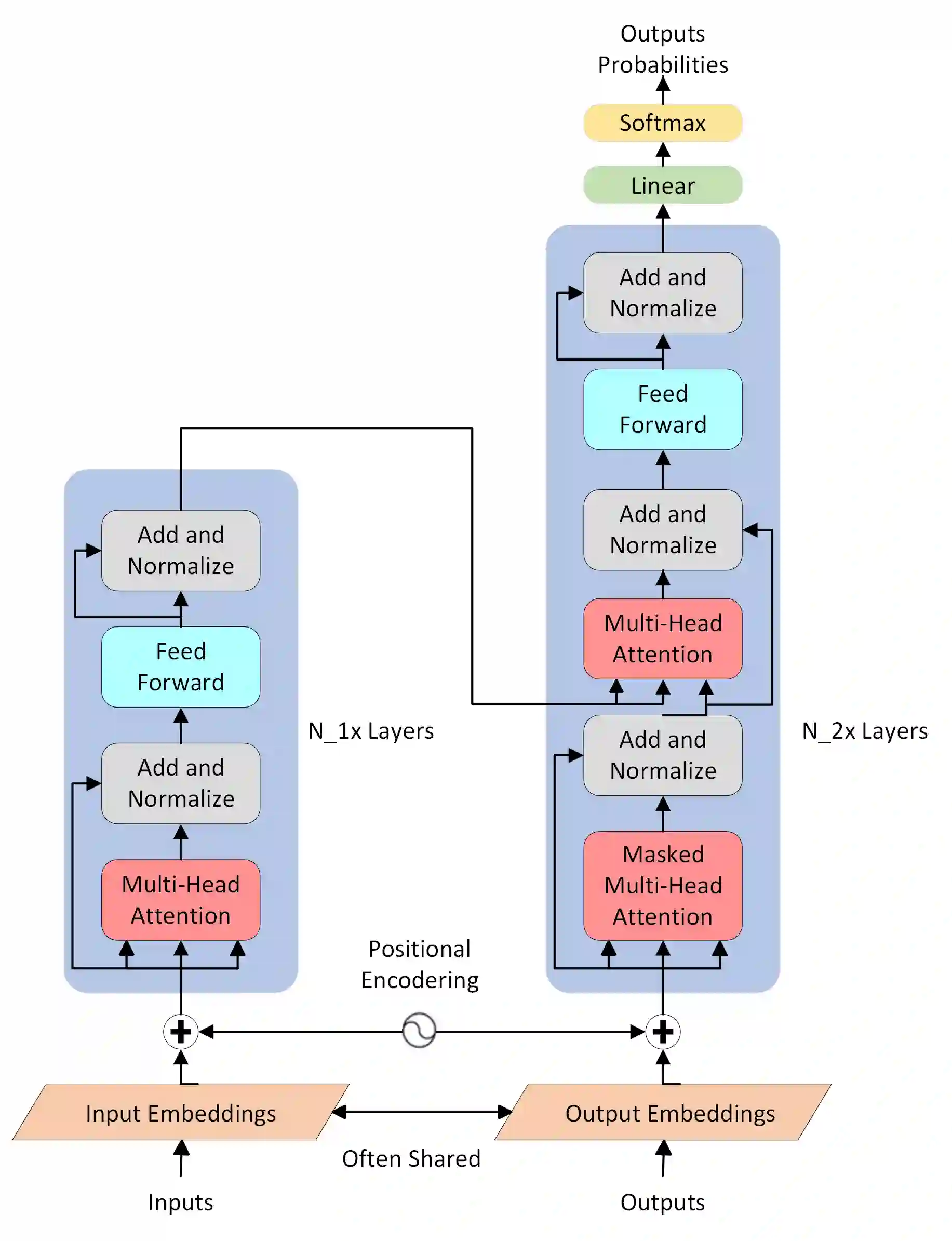
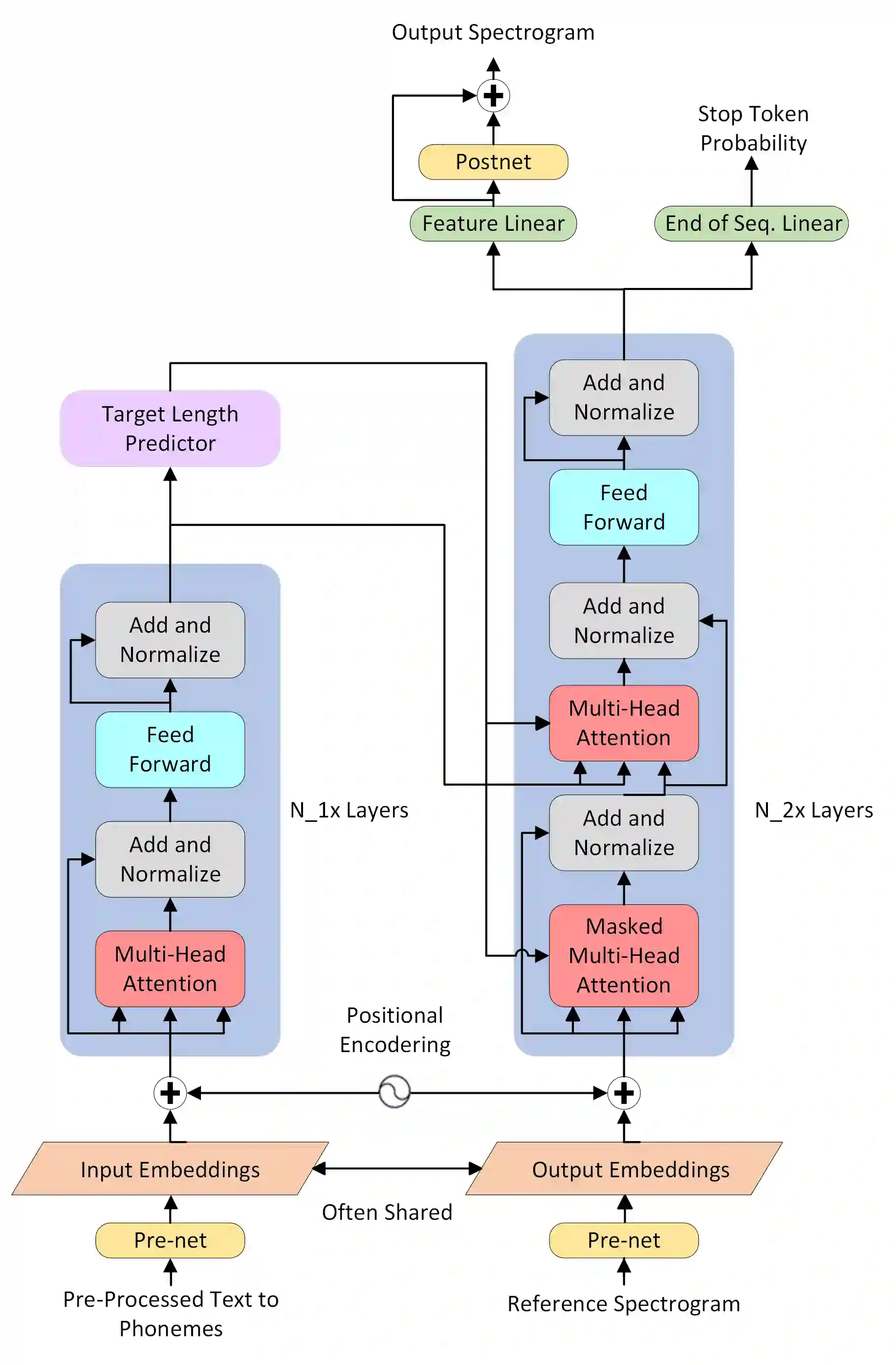
Various natural language processing (NLP) tasks necessitate models that are efficient and small based on their ultimate application at the edge or in other resource-constrained environments. While prior research has reduced the size of these models, increasing computational efficiency without considerable performance impacts remains difficult, especially for autoregressive tasks. This paper proposes \textit{modular linearized attention (MLA)}, which combines multiple efficient attention mechanisms, including cosFormer \cite{zhen2022cosformer}, to maximize inference quality while achieving notable speedups. We validate this approach on several autoregressive NLP tasks, including speech-to-text neural machine translation (S2T NMT), speech-to-text simultaneous translation (SimulST), and autoregressive text-to-spectrogram, noting efficiency gains on TTS and competitive performance for NMT and SimulST during training and inference.
翻译:诸多自然语言处理(NLP)任务要求模型在边缘计算或其他资源受限环境中具备高效性与小巧性。尽管先前的研究已缩小模型规模,但在不显著影响性能的前提下提升计算效率仍具挑战,尤其对于自回归任务。本文提出\textit{模块化线性注意力(MLA)},该机制融合cosFormer \cite{zhen2022cosformer}等多种高效注意力机制,在实现显著加速的同时最大化推理质量。我们在多项自回归NLP任务上验证了该方法,包括语音到文本神经机器翻译(S2T NMT)、语音到文本同声传译(SimulST)以及自回归文本到频谱图生成,结果显示在TTS上取得效率提升,且在NMT与SimulST的训练与推理阶段均保持具有竞争力的性能。