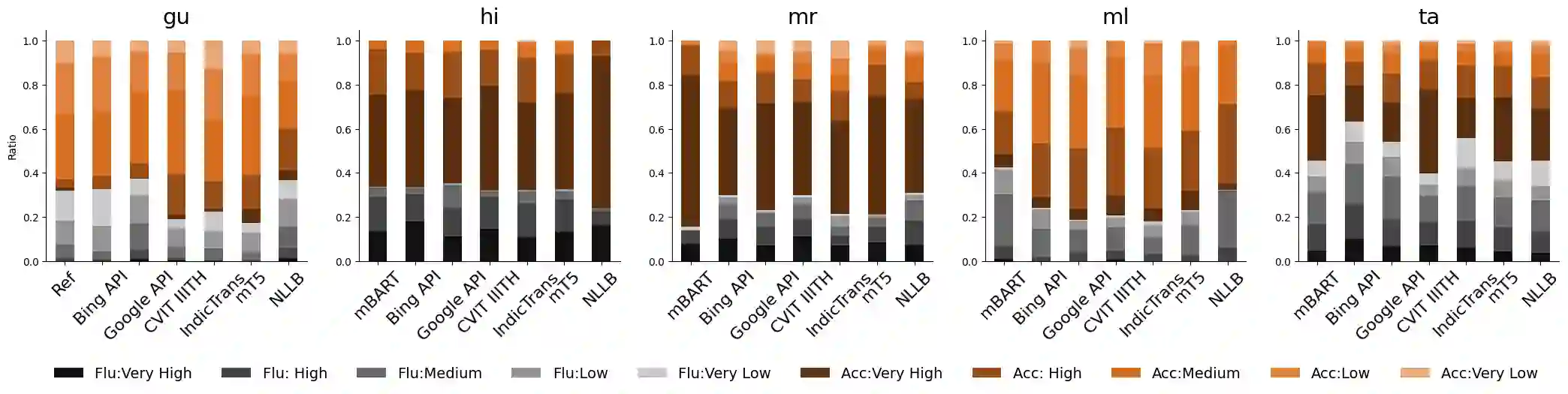
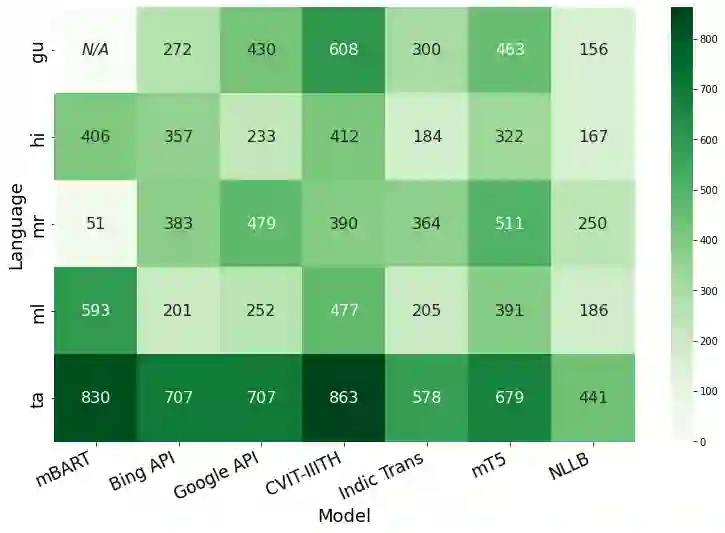
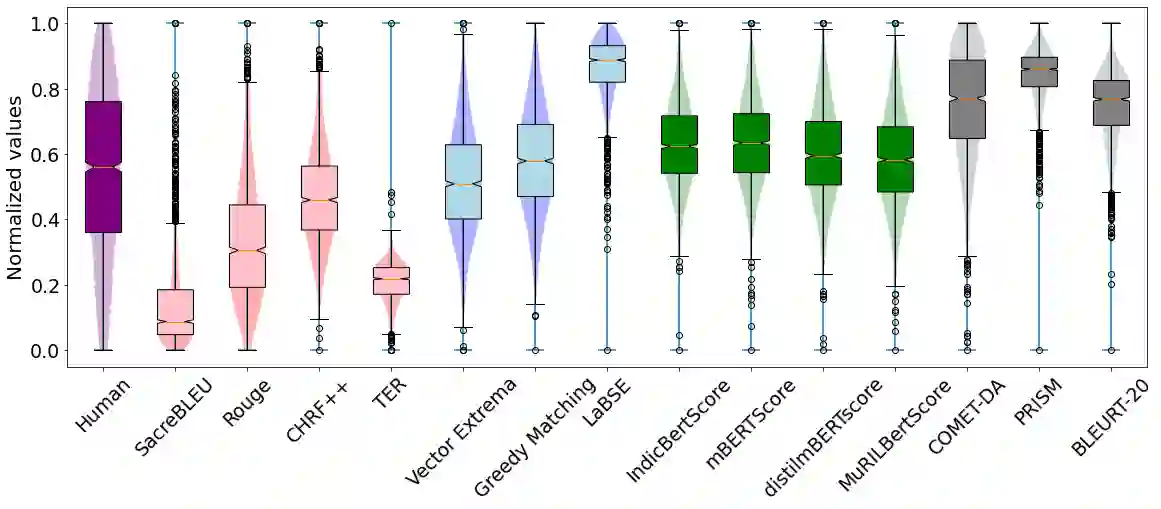
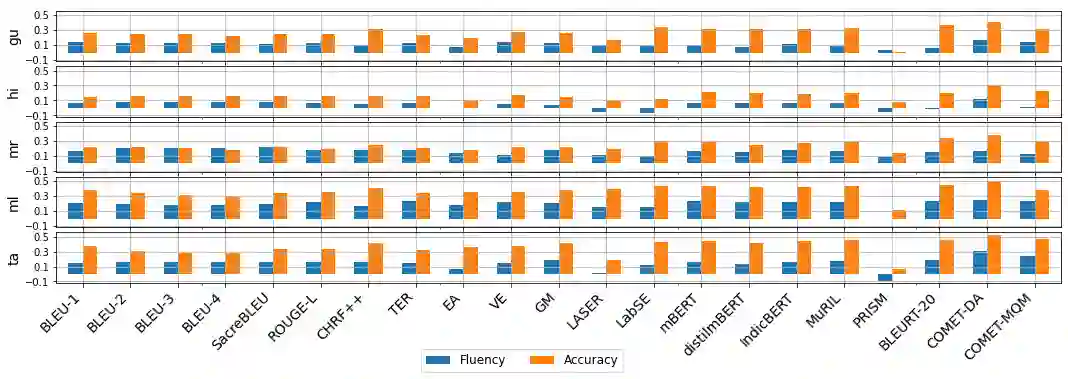
The rapid growth of machine translation (MT) systems has necessitated comprehensive studies to meta-evaluate evaluation metrics being used, which enables a better selection of metrics that best reflect MT quality. Unfortunately, most of the research focuses on high-resource languages, mainly English, the observations for which may not always apply to other languages. Indian languages, having over a billion speakers, are linguistically different from English, and to date, there has not been a systematic study of evaluating MT systems from English into Indian languages. In this paper, we fill this gap by creating an MQM dataset consisting of 7000 fine-grained annotations, spanning 5 Indian languages and 7 MT systems, and use it to establish correlations between annotator scores and scores obtained using existing automatic metrics. Our results show that pre-trained metrics, such as COMET, have the highest correlations with annotator scores. Additionally, we find that the metrics do not adequately capture fluency-based errors in Indian languages, and there is a need to develop metrics focused on Indian languages. We hope that our dataset and analysis will help promote further research in this area.
翻译:机器翻译系统的快速发展促使人们开展全面研究,对所使用的评估指标进行元评估,从而更好地选择最能反映机器翻译质量的指标。然而,多数研究聚焦于高资源语言(主要是英语),其观察结果未必适用于其他语言。拥有超过十亿使用人口的印度语言在语言学上与英语存在差异,且迄今为止,尚未有系统研究对从英语到印度语言的机器翻译系统进行评估。本文通过构建一个包含7000条细粒度标注的MQM数据集(覆盖5种印度语言和7个机器翻译系统)填补了这一空白,并利用该数据集建立标注者得分与现有自动评估指标得分之间的相关性。结果表明,预训练指标(如COMET)与标注者得分的相关性最高。此外,我们发现这些指标未能充分捕捉印度语言中基于流畅性的错误,因此需要开发专注于印度语言的评估指标。我们期望本数据集及分析能推动该领域的进一步研究。