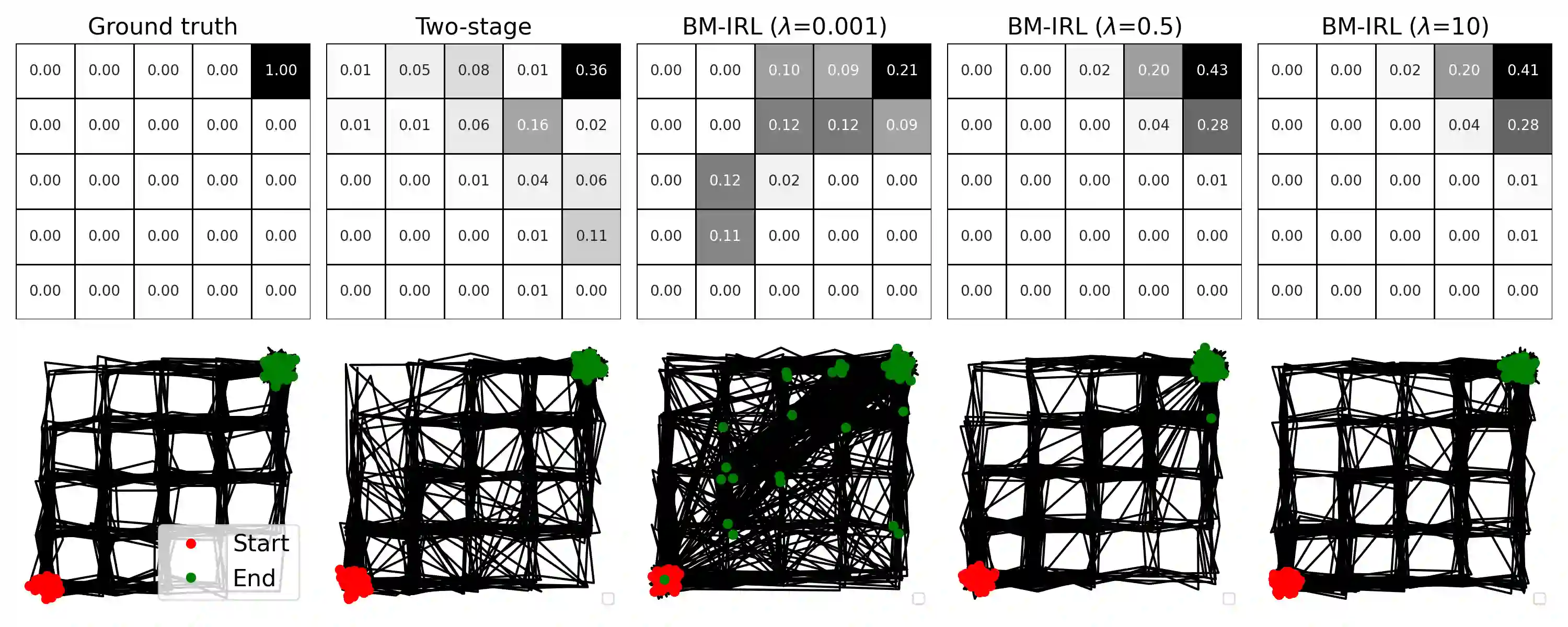
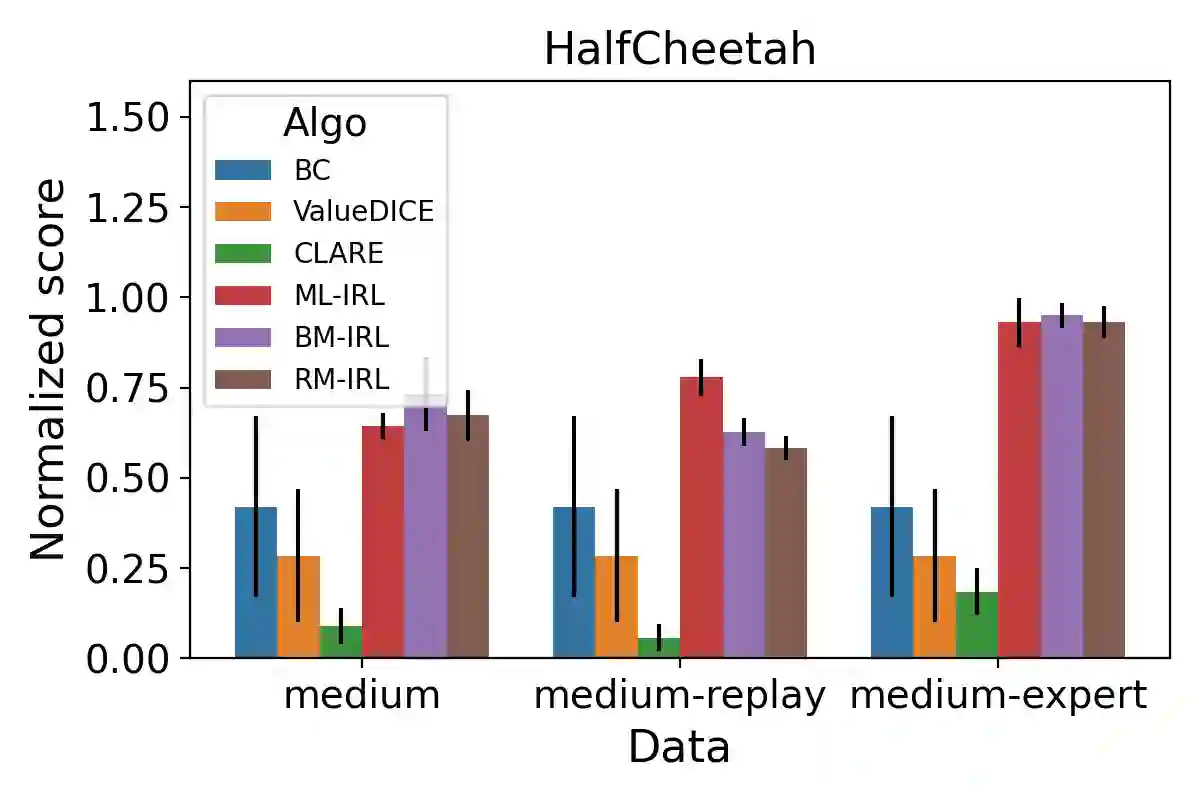
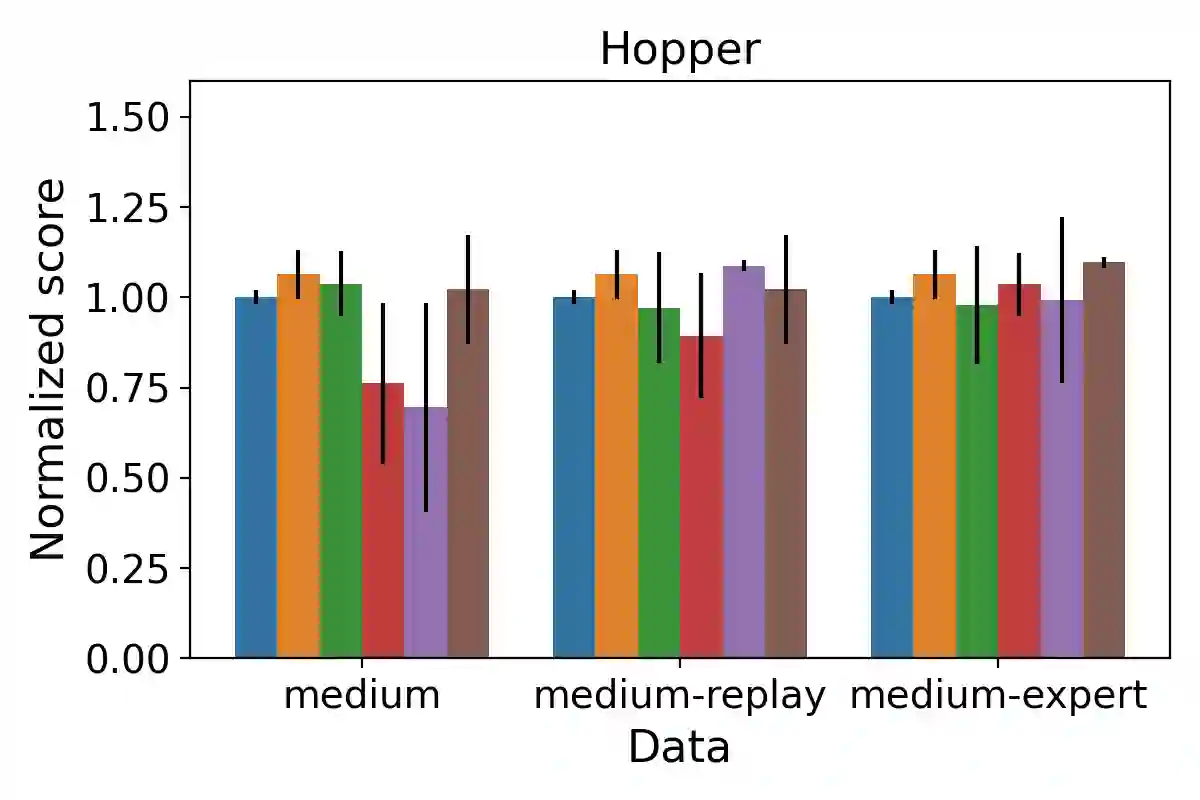
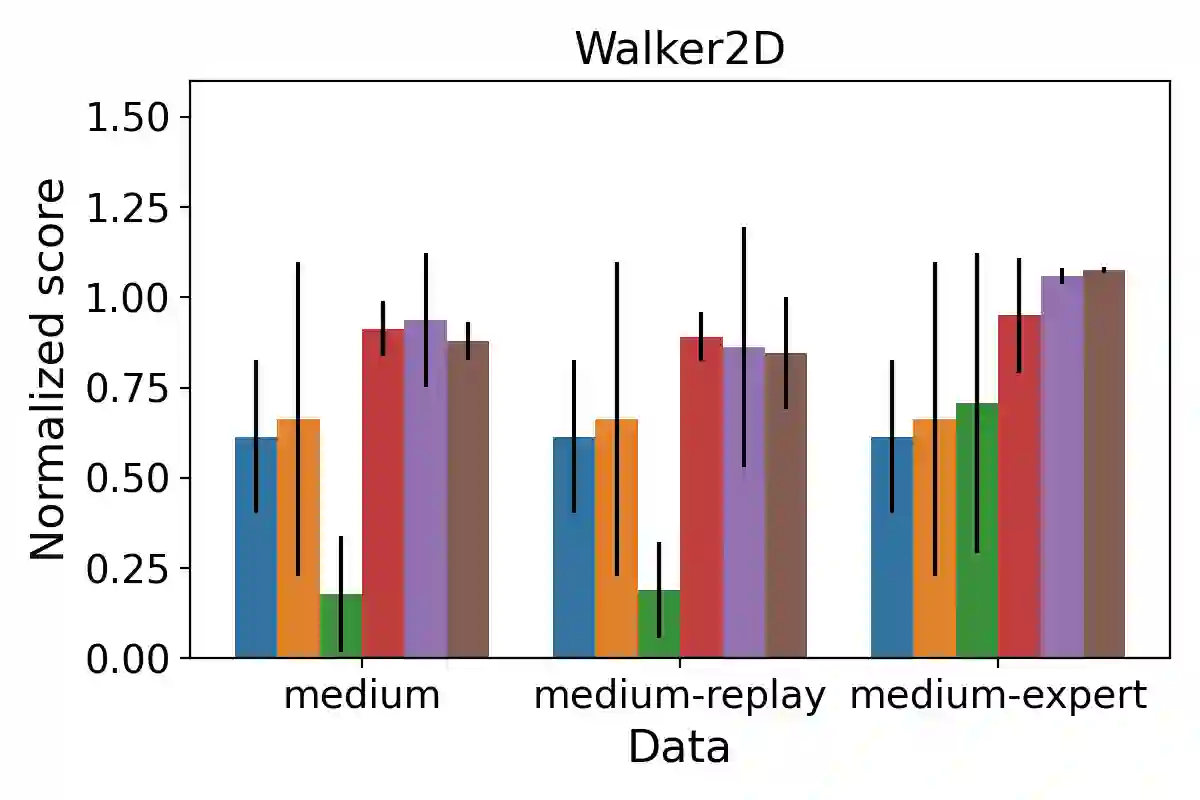
We consider a Bayesian approach to offline model-based inverse reinforcement learning (IRL). The proposed framework differs from existing offline model-based IRL approaches by performing simultaneous estimation of the expert's reward function and subjective model of environment dynamics. We make use of a class of prior distributions which parameterizes how accurate the expert's model of the environment is to develop efficient algorithms to estimate the expert's reward and subjective dynamics in high-dimensional settings. Our analysis reveals a novel insight that the estimated policy exhibits robust performance when the expert is believed (a priori) to have a highly accurate model of the environment. We verify this observation in the MuJoCo environments and show that our algorithms outperform state-of-the-art offline IRL algorithms.
翻译:我们提出一种基于贝叶斯的离线模型逆强化学习方法。与现有离线模型逆强化学习方法不同,该框架通过同时估计专家的奖励函数及其对环境的动力学主观模型,实现了方法创新。通过采用一类能参数化专家环境模型精度的先验分布,我们开发出适用于高维场景的高效算法,用于估计专家的奖励函数与主观动力学。分析揭示了全新见解:当先验认定专家对环境模型具有高度准确性时,所估计策略展现出鲁棒性能。我们在MuJoCo环境中验证了这一结论,并证明本文算法优于现有最先进离线逆强化学习方法。