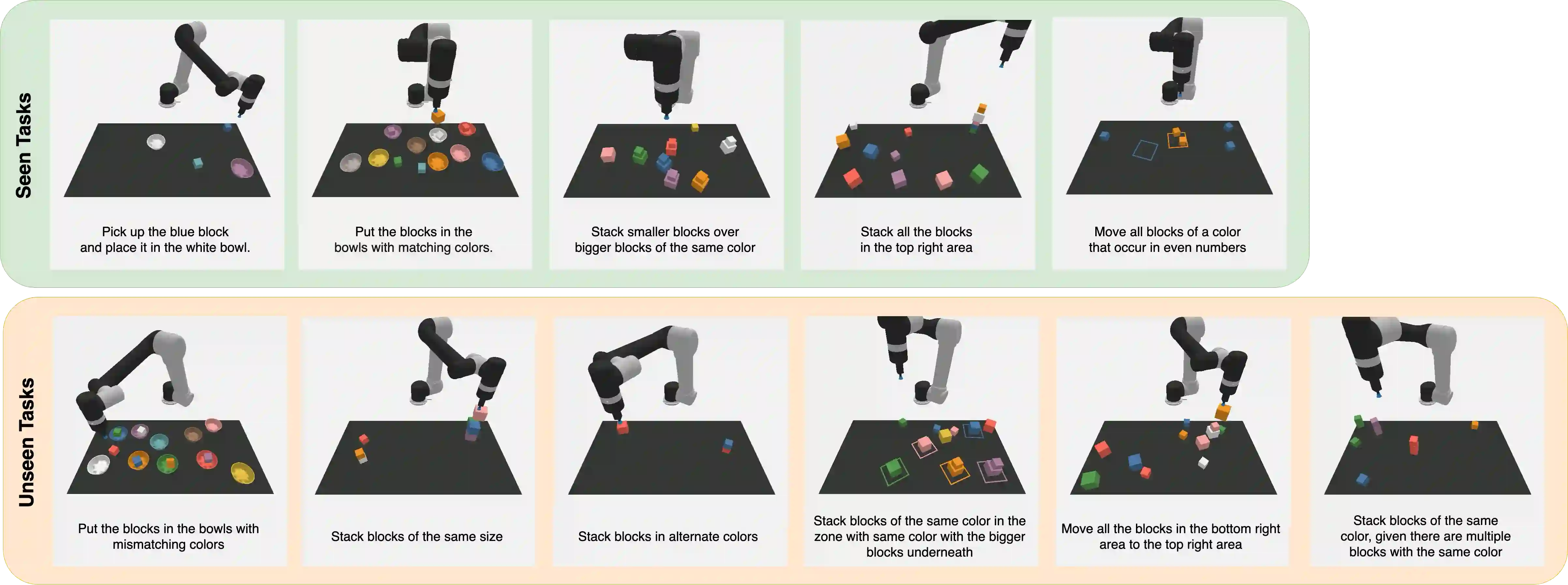
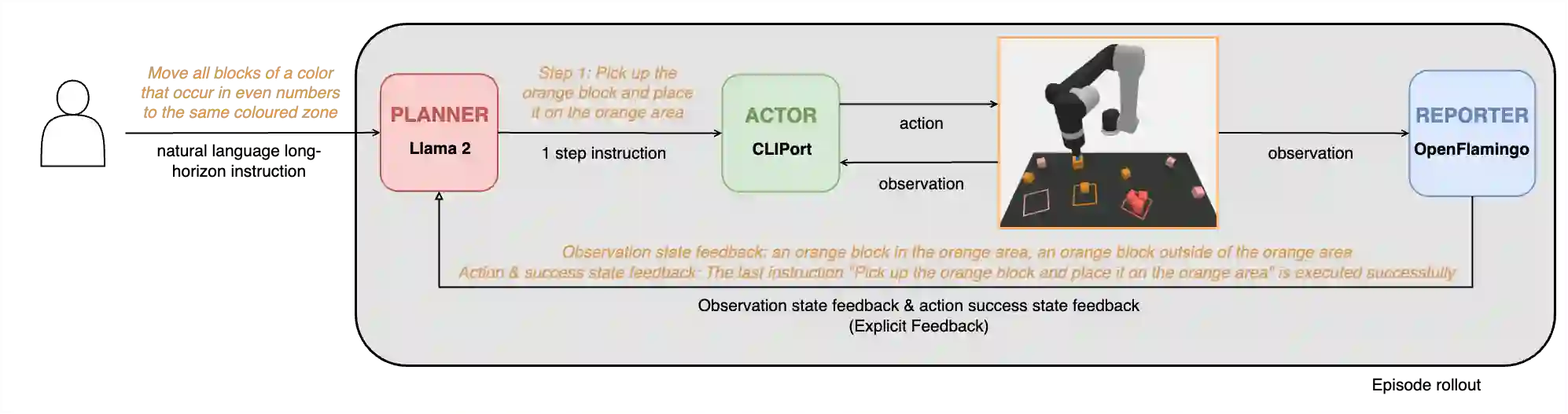
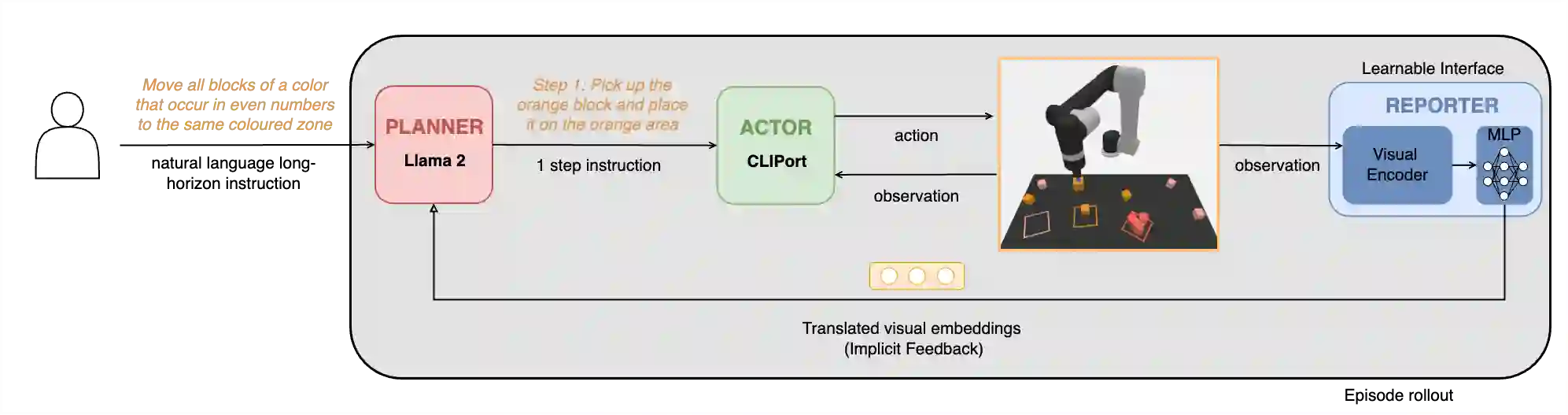
The convergence of embodied agents and large language models (LLMs) has brought significant advancements to embodied instruction following. Particularly, the strong reasoning capabilities of LLMs make it possible for robots to perform long-horizon tasks without expensive annotated demonstrations. However, public benchmarks for testing the long-horizon reasoning capabilities of language-conditioned robots in various scenarios are still missing. To fill this gap, this work focuses on the tabletop manipulation task and releases a simulation benchmark, \textit{LoHoRavens}, which covers various long-horizon reasoning aspects spanning color, size, space, arithmetics and reference. Furthermore, there is a key modality bridging problem for long-horizon manipulation tasks with LLMs: how to incorporate the observation feedback during robot execution for the LLM's closed-loop planning, which is however less studied by prior work. We investigate two methods of bridging the modality gap: caption generation and learnable interface for incorporating explicit and implicit observation feedback to the LLM, respectively. These methods serve as the two baselines for our proposed benchmark. Experiments show that both methods struggle to solve some tasks, indicating long-horizon manipulation tasks are still challenging for current popular models. We expect the proposed public benchmark and baselines can help the community develop better models for long-horizon tabletop manipulation tasks.
翻译:具身智能体与大语言模型的融合推动了具身指令跟随任务的重大进展。特别是大语言模型强大的推理能力,使得机器人无需昂贵的人工标注示范即可执行长时域任务。然而,目前仍缺乏用于测试语言条件机器人在不同场景下长时域推理能力的公开基准。为填补这一空白,本工作聚焦桌面操作任务,发布仿真基准《LoHoRavens》,涵盖颜色、大小、空间、算术和参照等多个维度的长时域推理问题。此外,在将大语言模型应用于长时域操作任务时存在一个关键模态桥接问题:如何在机器人执行过程中将观测反馈融入大语言模型的闭环规划?这一问题在以往研究中较少被涉及。我们研究了两种桥接模态差异的方法:分别通过生成描述和可学习接口向大语言模型注入显式和隐式观测反馈。这些方法作为我们提出基准的两个基线方案。实验表明,两种方法在某些任务上均存在困难,揭示出长时域操作任务对当前流行模型仍具挑战性。我们期望本文提出的公开基准与基线方案能够帮助社区为长时域桌面操作任务开发更优模型。