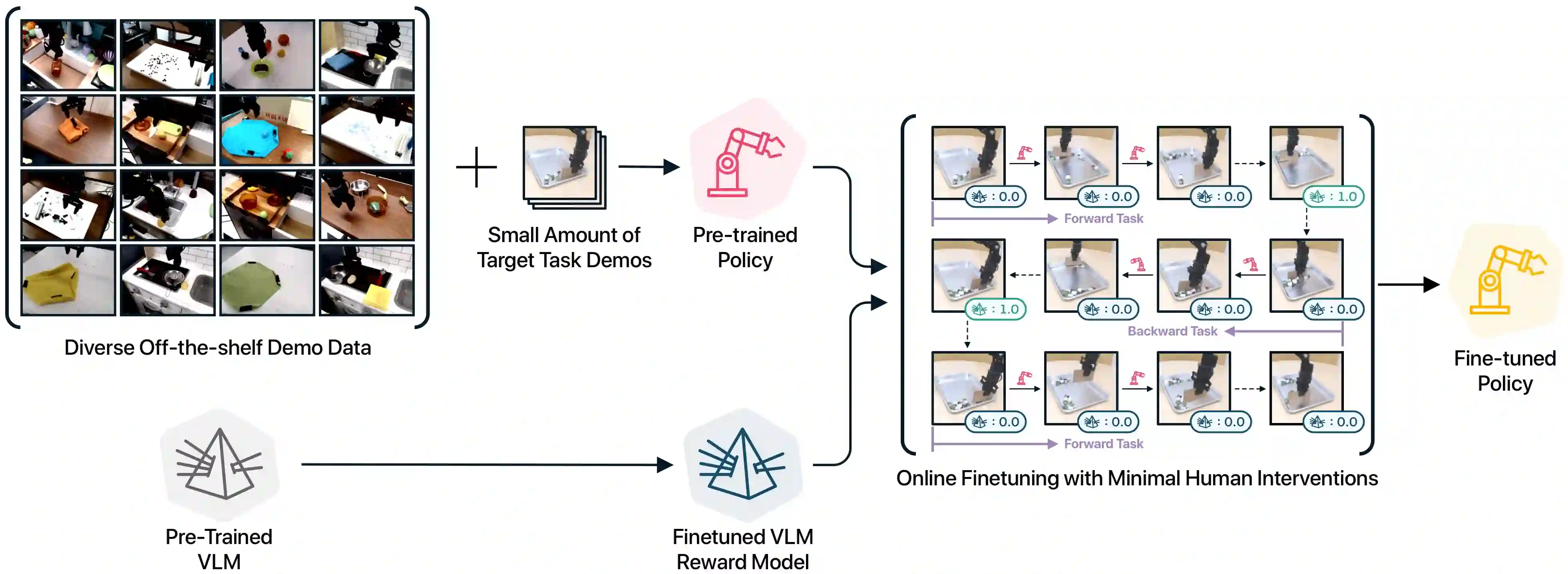
The pre-train and fine-tune paradigm in machine learning has had dramatic success in a wide range of domains because the use of existing data or pre-trained models on the internet enables quick and easy learning of new tasks. We aim to enable this paradigm in robotic reinforcement learning, allowing a robot to learn a new task with little human effort by leveraging data and models from the Internet. However, reinforcement learning often requires significant human effort in the form of manual reward specification or environment resets, even if the policy is pre-trained. We introduce RoboFuME, a reset-free fine-tuning system that pre-trains a multi-task manipulation policy from diverse datasets of prior experiences and self-improves online to learn a target task with minimal human intervention. Our insights are to utilize calibrated offline reinforcement learning techniques to ensure efficient online fine-tuning of a pre-trained policy in the presence of distribution shifts and leverage pre-trained vision language models (VLMs) to build a robust reward classifier for autonomously providing reward signals during the online fine-tuning process. In a diverse set of five real robot manipulation tasks, we show that our method can incorporate data from an existing robot dataset collected at a different institution and improve on a target task within as little as 3 hours of autonomous real-world experience. We also demonstrate in simulation experiments that our method outperforms prior works that use different RL algorithms or different approaches for predicting rewards. Project website: https://robofume.github.io
翻译:在机器学习中,预训练与微调范式已在多个领域取得显著成功,其核心在于利用互联网上的现有数据或预训练模型,实现新任务的快速轻松学习。我们旨在将这一范式应用于机器人强化学习,使机器人能够借助互联网数据和模型,以极少的人工干预学习新任务。然而,即便策略已预训练,强化学习通常仍需大量人工投入,例如手动设计奖励函数或重置环境。为此,我们提出 RoboFuME 系统——一种无需重置的微调系统,它通过多样化的先验经验数据集预训练多任务操作策略,并在线自我改进,从而以最小人工干预学习目标任务。我们的核心思路是:采用校准后的离线强化学习技术,确保预训练策略在分布偏移存在的情况下实现高效的在线微调;同时利用预训练的视觉语言模型(VLM)构建鲁棒的奖励分类器,在在线微调过程中自主提供奖励信号。在五个不同的真实机器人操作任务中,我们证明该方法能整合来自不同机构现有机器人数据集的数据,并在仅需3小时自主真实世界经验后提升目标任务性能。仿真实验进一步表明,我们的方法优于采用不同强化学习算法或不同奖励预测方式的先前工作。项目网站:https://robofume.github.io