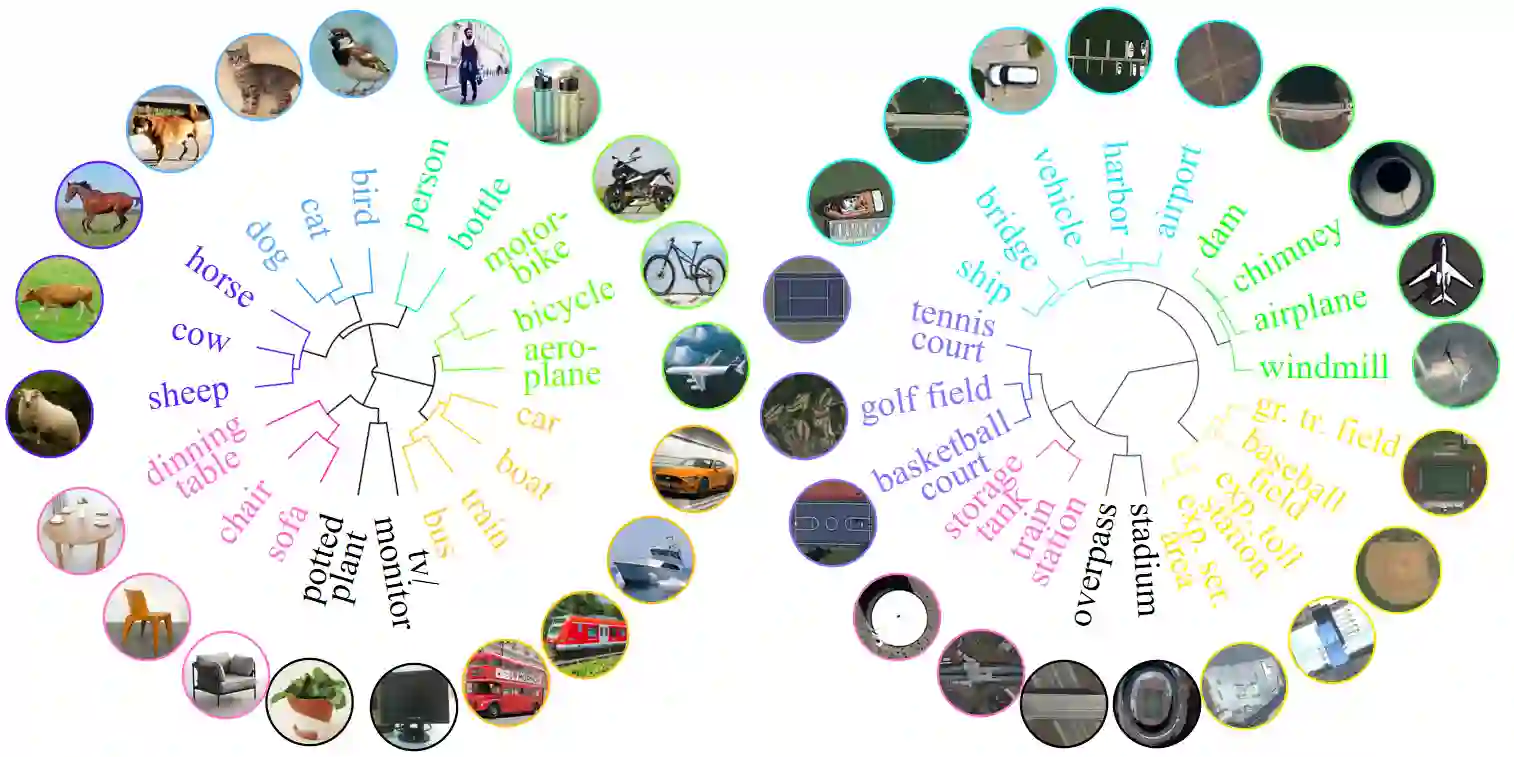
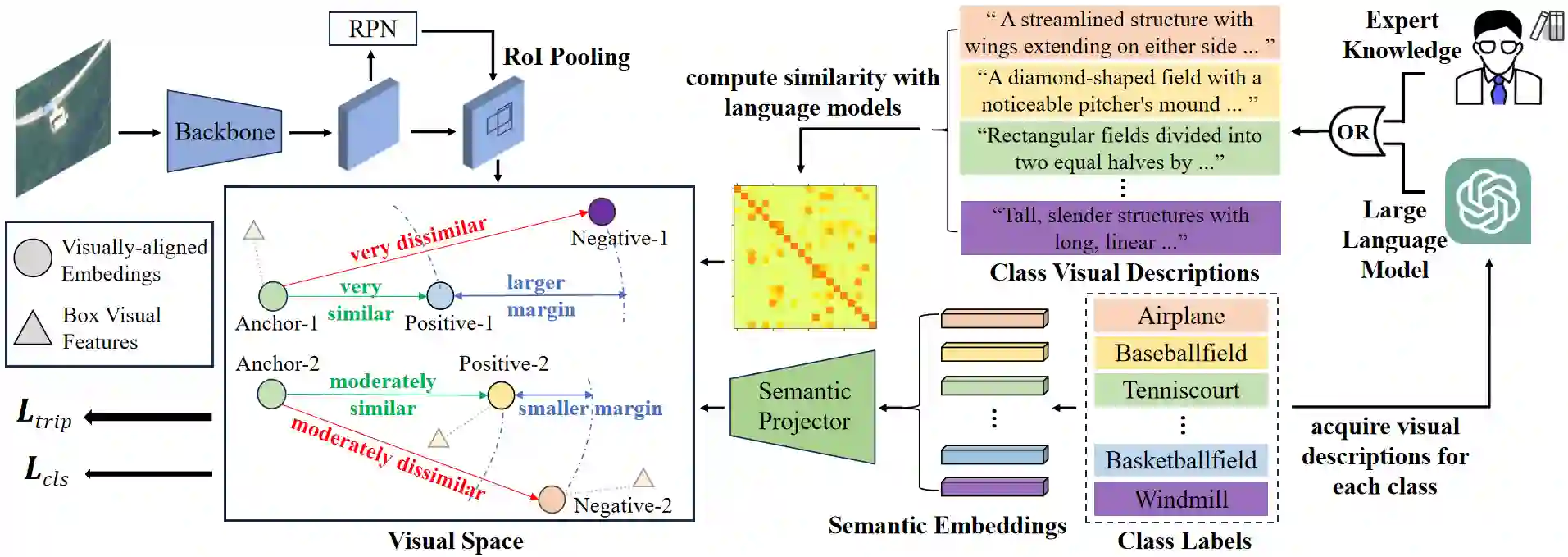
Existing object detection models are mainly trained on large-scale labeled datasets. However, annotating data for novel aerial object classes is expensive since it is time-consuming and may require expert knowledge. Thus, it is desirable to study label-efficient object detection methods on aerial images. In this work, we propose a zero-shot method for aerial object detection named visual Description Regularization, or DescReg. Concretely, we identify the weak semantic-visual correlation of the aerial objects and aim to address the challenge with prior descriptions of their visual appearance. Instead of directly encoding the descriptions into class embedding space which suffers from the representation gap problem, we propose to infuse the prior inter-class visual similarity conveyed in the descriptions into the embedding learning. The infusion process is accomplished with a newly designed similarity-aware triplet loss which incorporates structured regularization on the representation space. We conduct extensive experiments with three challenging aerial object detection datasets, including DIOR, xView, and DOTA. The results demonstrate that DescReg significantly outperforms the state-of-the-art ZSD methods with complex projection designs and generative frameworks, e.g., DescReg outperforms best reported ZSD method on DIOR by 4.5 mAP on unseen classes and 8.1 in HM. We further show the generalizability of DescReg by integrating it into generative ZSD methods as well as varying the detection architecture.
翻译:现有目标检测模型主要在大规模标注数据集上训练。然而,为新型航拍目标类别标注数据成本高昂,既耗时又需专业知识。因此,研究面向航拍图像的标签高效目标检测方法具有重要意义。本文提出一种名为“视觉描述正则化”(DescReg)的零样本航拍目标检测方法。具体而言,我们识别到航拍目标存在弱语义-视觉关联问题,并尝试利用其视觉外观的先验描述来应对该挑战。为避免直接编码描述到类嵌入空间所导致的表征鸿沟问题,我们提出将描述中蕴含的类别间先验视觉相似性注入嵌入学习过程。该注入通过新设计的相似感知三元组损失实现,该损失引入表征空间的结构化正则化。我们在DIOR、xView和DOTA三个具有挑战性的航拍目标检测数据集上进行大量实验。结果表明,DescReg显著优于采用复杂投影设计和生成式框架的最先进零样本检测方法,例如在DIOR数据集上,DescReg在未见类别上较最优报告方法提升4.5个mAP,在HM指标上提升8.1。此外,我们通过将DescReg集成到生成式零样本检测方法及不同检测架构中,进一步验证了其泛化能力。