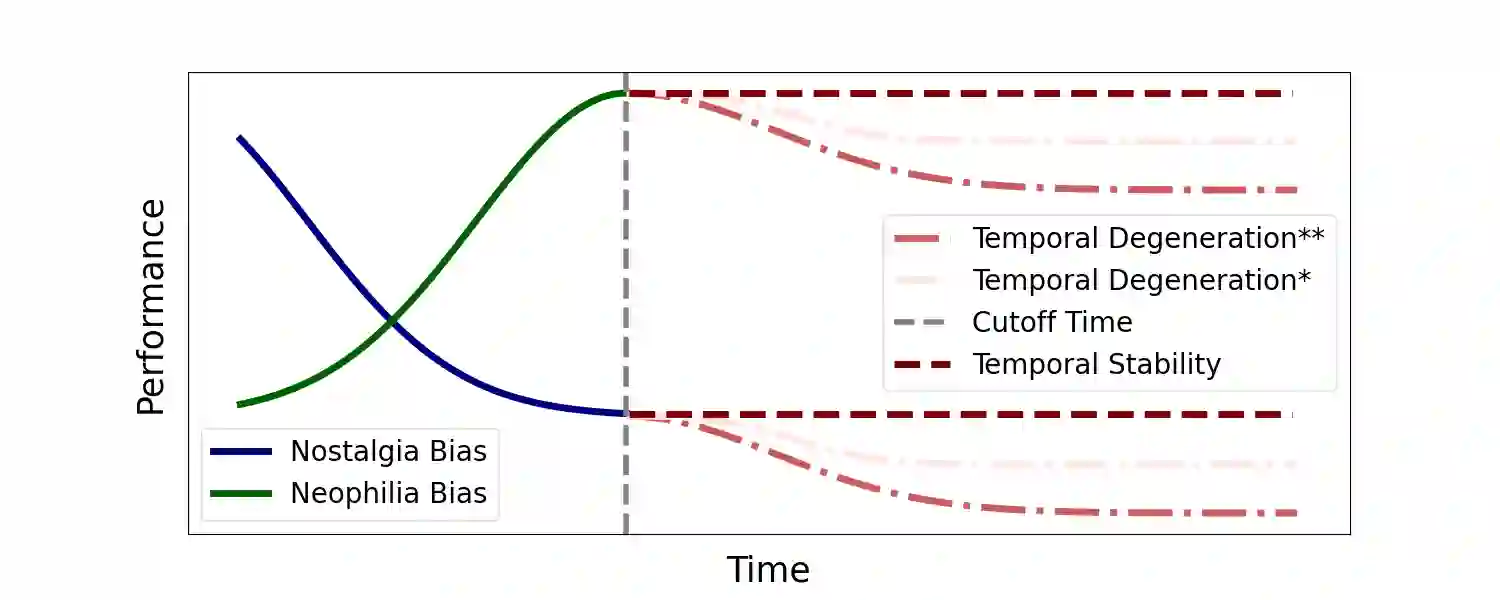
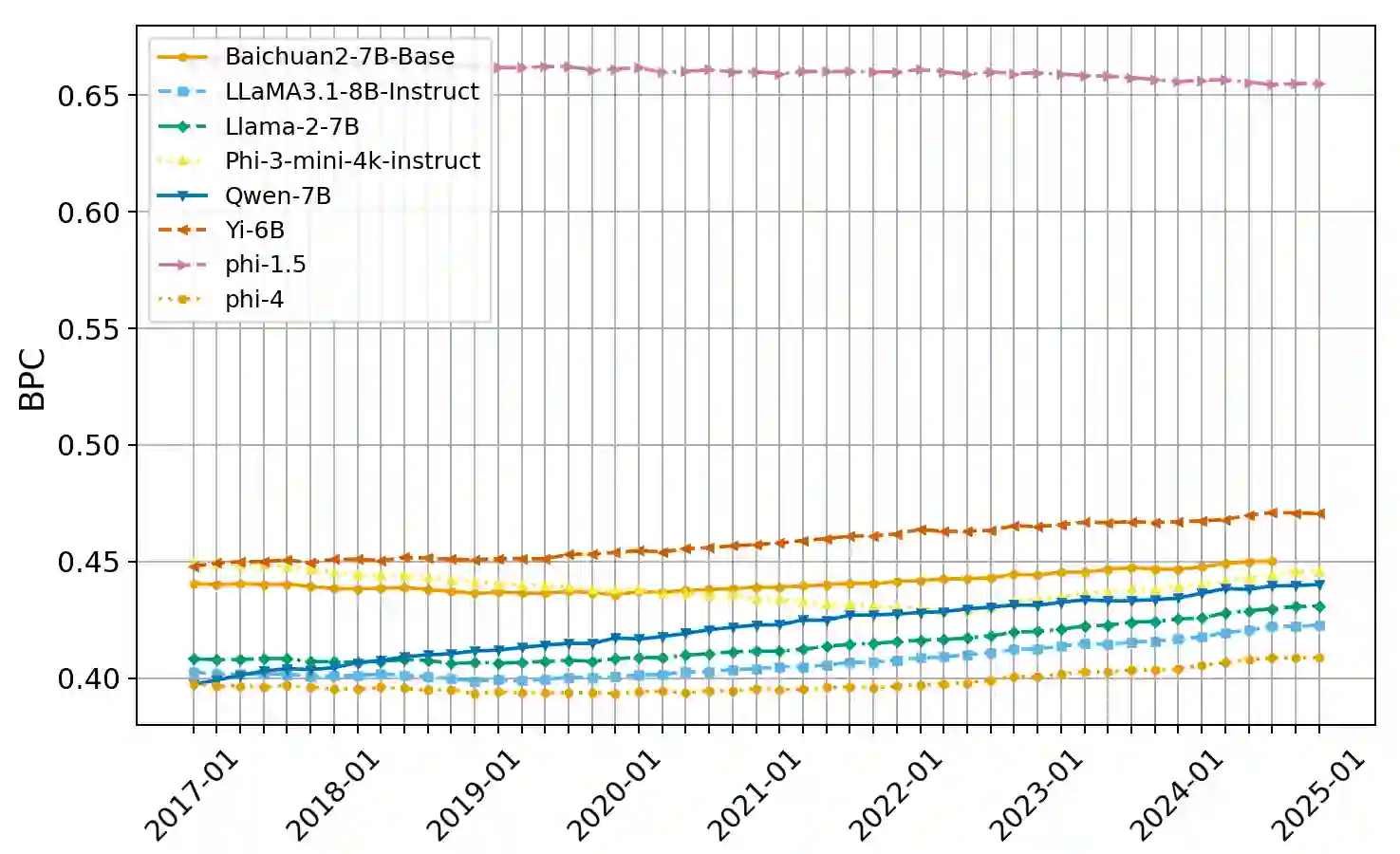
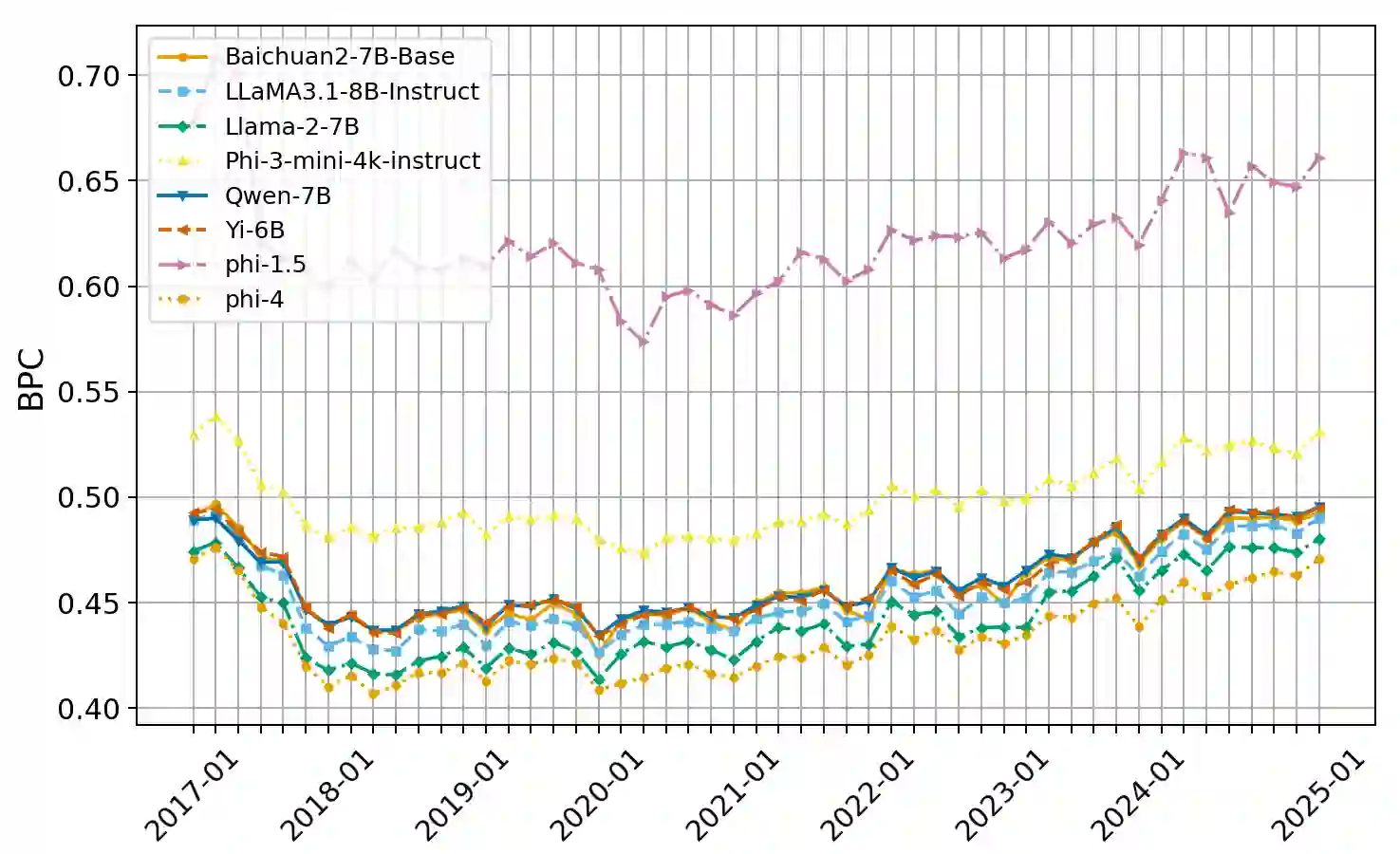
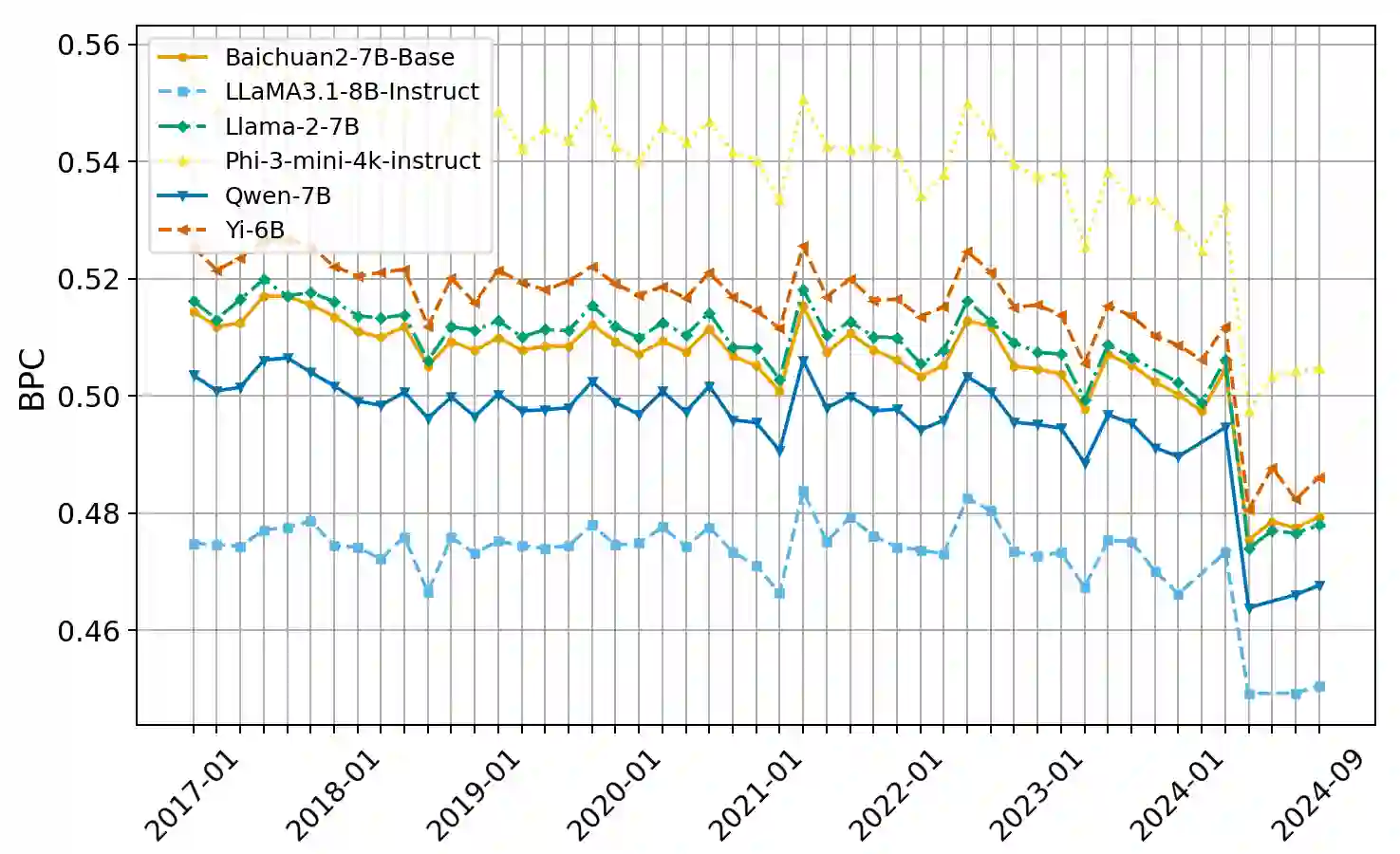
The rapid advancement of Large Language Models (LLMs) has led to the development of benchmarks that consider temporal dynamics, however, there remains a gap in understanding how well these models can generalize across temporal contexts due to the inherent dynamic nature of language and information. This paper introduces the concept of temporal generalization in LLMs, including bias in past and future generalizations. Then we introduce FreshBench, a new evaluation framework that employs fresh text and event prediction for assessing LLMs' temporal adaptability, ensuring the evaluation process free from data leakage and subjective bias. The experiment shows significant temporal biases and a decline in performance over time. Our findings reveal that powerful models, while initially superior, tend to decline more rapidly in future generalization. Additionally, powerful open-source models demonstrate better long-term adaptability compared to their closed-source counterparts. Our code is available at https://github.com/FreedomIntelligence/FreshBench.
翻译:大型语言模型(LLMs)的快速发展催生了考虑时间动态性的评测基准,然而,由于语言与信息固有的动态特性,对于这些模型在时间语境中的泛化能力仍缺乏深入理解。本文提出了LLMs时间泛化的概念体系,涵盖过去与未来泛化中的偏差问题。进而我们提出FreshBench——一个通过新鲜文本与事件预测来评估LLMs时间适应性的新型评测框架,该框架确保评估过程免受数据泄露和主观偏差的影响。实验结果表明模型存在显著的时间偏差,且性能随时间推移而下降。研究发现:尽管强大模型在初始阶段表现优异,但其在未来泛化中的性能衰退更为迅速。此外,与闭源模型相比,强大的开源模型展现出更优的长期适应性。相关代码已发布于https://github.com/FreedomIntelligence/FreshBench。