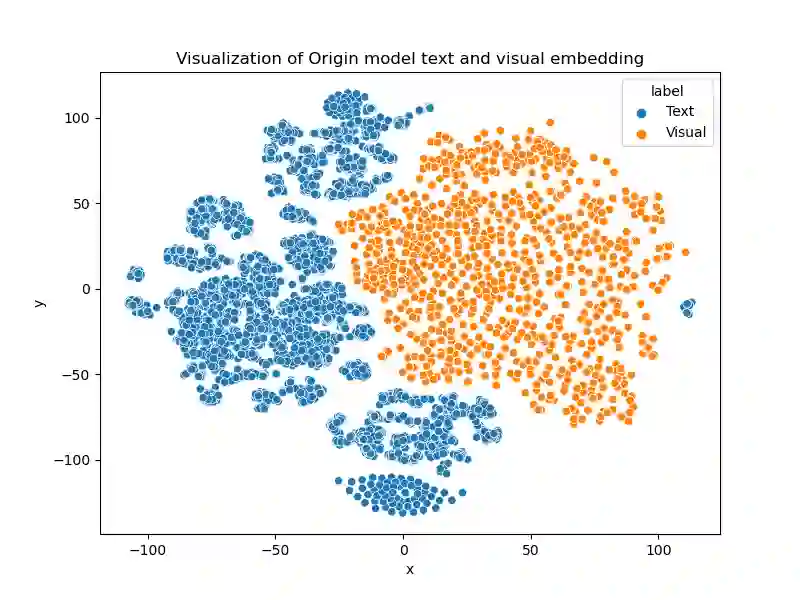
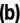Visual grounding aims to align visual information of specific regions of images with corresponding natural language expressions. Current visual grounding methods leverage pre-trained visual and language backbones separately to obtain visual features and linguistic features. Although these two types of features are then fused via delicately designed networks, the heterogeneity of the features makes them inapplicable for multi-modal reasoning. This problem arises from the domain gap between the single-modal pre-training backbone used in current visual grounding methods, which can hardly be overcome by the traditional end-to-end training method. To alleviate this, our work proposes an Empowering pre-trained model for Visual Grounding (EpmVG) framework, which distills a multimodal pre-trained model to guide the visual grounding task. EpmVG is based on a novel cross-modal distillation mechanism, which can effectively introduce the consistency information of images and texts in the pre-trained model, to reduce the domain gap existing in the backbone networks, thereby improving the performance of the model in the visual grounding task. Extensive experiments are carried out on five conventionally used datasets, and results demonstrate that our method achieves better performance than state-of-the-art methods.
翻译:视觉定位旨在将图像特定区域的视觉信息与对应的自然语言表述对齐。当前视觉定位方法分别利用预训练的视觉和语言主干网络提取视觉特征与语言特征。尽管这两类特征通过精心设计的网络进行融合,但特征的异质性使其难以适用于多模态推理。该问题源于现有视觉定位方法中单模态预训练主干网络存在的领域差距,而传统端到端训练方法难以克服这一差距。为缓解此问题,本文提出赋能预训练模型的视觉定位(EpmVG)框架,通过蒸馏多模态预训练模型来引导视觉定位任务。EpmVG基于新颖的跨模态蒸馏机制,能够有效引入预训练模型中图像与文本的一致性信息,减少主干网络存在的领域差距,从而提升模型在视觉定位任务中的性能。我们在五个常用数据集上进行了大量实验,结果表明该方法优于现有最先进方法。