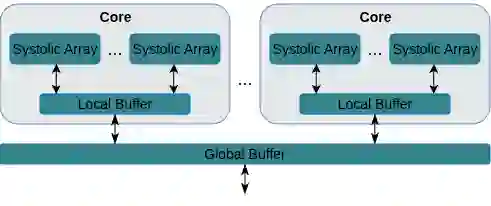
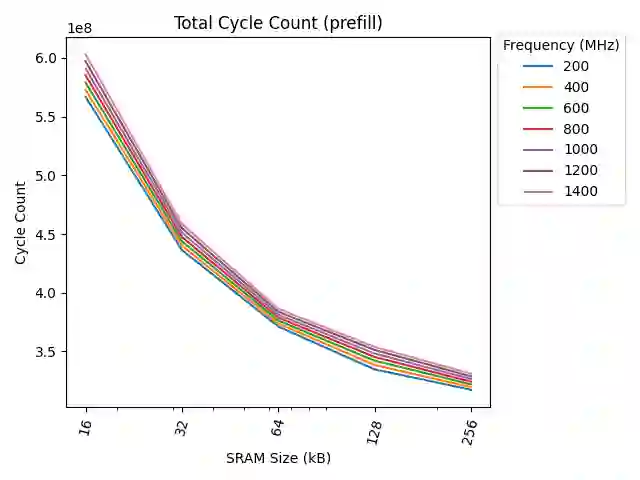
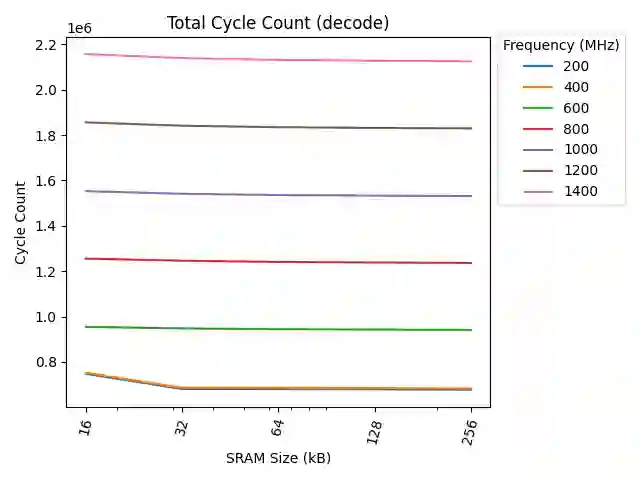
Energy consumption dictates the cost and environmental impact of deploying Large Language Models. This paper investigates the impact of on-chip SRAM size and operating frequency on the energy efficiency and performance of LLM inference, focusing on the distinct behaviors of the compute-bound prefill and memory-bound decode phases. Our simulation methodology combines OpenRAM for energy modeling, LLMCompass for latency simulation, and ScaleSIM for systolic array operational intensity. Our findings show that total energy use is predominantly determined by SRAM size in both phases, with larger buffers significantly increasing static energy due to leakage, which is not offset by corresponding latency benefits. We quantitatively explore the memory-bandwidth bottleneck, demonstrating that while high operating frequencies reduce prefill latency, their positive impact on memory-bound decode latency is capped by the external memory bandwidth. Counter-intuitively, high compute frequency can reduce total energy by reducing execution time and consequently decreasing static energy consumption more than the resulting dynamic power increase. We identify an optimal hardware configuration for the simulated workload: high operating frequencies (1200MHz-1400MHz) and a small local buffer size of 32KB to 64KB. This combination achieves the best energy-delay product, balancing low latency with high energy efficiency. Furthermore, we demonstrate how memory bandwidth acts as a performance ceiling, and that increasing compute frequency only yields performance gains up to the point where the workload becomes memory-bound. This analysis provides concrete architectural insights for designing energy-efficient LLM accelerators, especially for datacenters aiming to minimize their energy overhead.
翻译:大型语言模型的部署成本与环境影响主要由能耗决定。本文研究了片上SRAM尺寸与工作频率对LLM推理能效与性能的影响,重点关注计算受限的预填充阶段与内存受限的解码阶段的差异化行为。我们的仿真方法整合了OpenRAM用于能耗建模、LLMCompass用于延迟仿真以及ScaleSIM用于脉动阵列运算强度分析。研究结果表明:两个阶段的总能耗主要取决于SRAM尺寸,更大的缓冲区会因漏电显著增加静态能耗,且相应的延迟收益无法抵消此消耗。我们定量探究了内存带宽瓶颈,证明虽然高工作频率能降低预填充延迟,但其对内存受限的解码延迟的积极影响受限于外部内存带宽。反直觉的是,高计算频率可通过缩短执行时间来降低总能耗,因为由此减少的静态能耗超过了动态功耗的增加。我们针对模拟工作负载确定了最优硬件配置:高工作频率(1200MHz-1400MHz)配合32KB至64KB的小型本地缓冲区。该组合实现了最佳的能耗延迟乘积,在低延迟与高能效间取得平衡。此外,我们论证了内存带宽如何构成性能上限,并指出提高计算频率仅在负载达到内存受限状态前能产生性能增益。本分析为设计高能效LLM加速器(特别是旨在最小化能耗开销的数据中心场景)提供了具体的架构设计洞见。