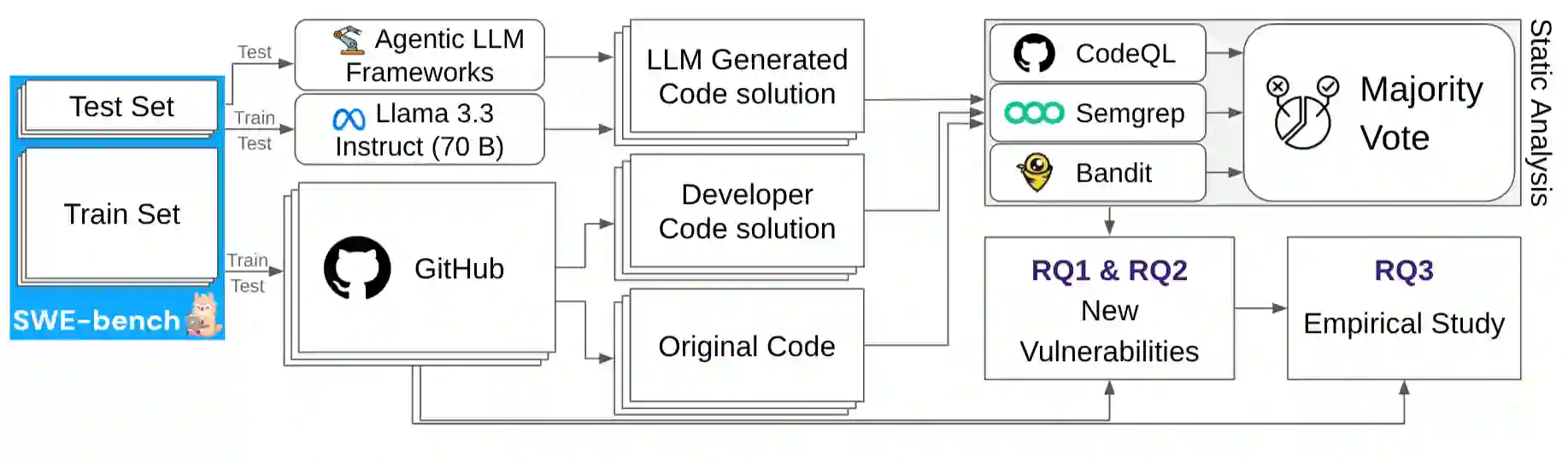
Large language models (LLMs) and their agentic frameworks are increasingly adopted to perform development tasks such as automated program repair (APR). While prior work has identified security risks in LLM-generated code, most have focused on synthetic, simplified, or isolated tasks that lack the complexity of real-world program repair. In this study, we present the first large-scale security analysis of LLM-generated patches using 20,000+ GitHub issues. We evaluate patches proposed by developers, a standalone LLM (Llama 3.3 Instruct-70B), and three top-performing agentic frameworks (OpenHands, AutoCodeRover, HoneyComb). Finally, we analyze a wide range of code, issue, and project-level factors to understand the conditions under which generating insecure patches is more likely. Our findings reveal that Llama introduces many new vulnerabilities, exhibiting unique patterns not found in developers' code. Agentic workflows also generate a number of vulnerabilities, particularly when given more autonomy. We find that vulnerabilities in LLM-generated patches are associated with distinctive code characteristics and are commonly observed in issues missing specific types of information. These results suggest that contextual factors play a critical role in the security of the generated patches and point toward the need for proactive risk assessment methods that account for both issue and code-level information.
翻译:大语言模型(LLM)及其智能体框架正日益广泛地应用于自动程序修复(APR)等开发任务。尽管先前研究已发现LLM生成代码中的安全风险,但大多聚焦于缺乏真实世界程序修复复杂性的合成、简化或孤立任务。本研究首次基于20,000多个GitHub问题对LLM生成的补丁进行大规模安全分析。我们评估了开发者提出的补丁、独立LLM(Llama 3.3 Instruct-70B)以及三种高性能智能体框架(OpenHands、AutoCodeRover、HoneyComb)生成的补丁。最后,我们通过分析代码、问题及项目层面的多维度因素,深入探究了生成不安全补丁的高发条件。研究发现:Llama会引入大量新漏洞,其模式特征在开发者代码中未曾出现;智能体工作流同样会产生诸多漏洞,在获得更高自主权时尤为明显。我们发现LLM生成补丁中的漏洞具有独特的代码特征,且常见于缺乏特定类型信息的问题中。这些结果表明上下文因素对生成补丁的安全性具有关键影响,并指向需要建立能同时考量问题层面与代码层信息的主动式风险评估方法。