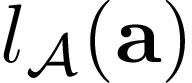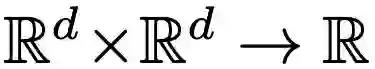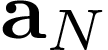We present a new class of structured reinforcement learning policy-architectures, Implicit Two-Tower (ITT) policies, where the actions are chosen based on the attention scores of their learnable latent representations with those of the input states. By explicitly disentangling action from state processing in the policy stack, we achieve two main goals: substantial computational gains and better performance. Our architectures are compatible with both: discrete and continuous action spaces. By conducting tests on 15 environments from OpenAI Gym and DeepMind Control Suite, we show that ITT-architectures are particularly suited for blackbox/evolutionary optimization and the corresponding policy training algorithms outperform their vanilla unstructured implicit counterparts as well as commonly used explicit policies. We complement our analysis by showing how techniques such as hashing and lazy tower updates, critically relying on the two-tower structure of ITTs, can be applied to obtain additional computational improvements.
翻译:我们提出了一类新型结构化强化学习策略架构——隐式双塔(ITT)策略,该策略根据动作与输入状态的潜在可学习表征之间的注意力分数来选择动作。通过在策略堆栈中显式解耦动作与状态处理,我们实现了两个主要目标:显著的计算效率提升和更优的性能。我们的架构同时适用于离散和连续动作空间。通过在OpenAI Gym和DeepMind Control Suite的15个环境中的测试,我们证明ITT架构特别适用于黑盒/进化优化,且相应的策略训练算法优于其原始非结构化隐式对应模型以及常用的显式策略。我们通过展示哈希和惰性塔更新等技术(这些技术关键依赖于ITT的双塔结构)如何被用于获得额外的计算改进,进一步补充了分析。