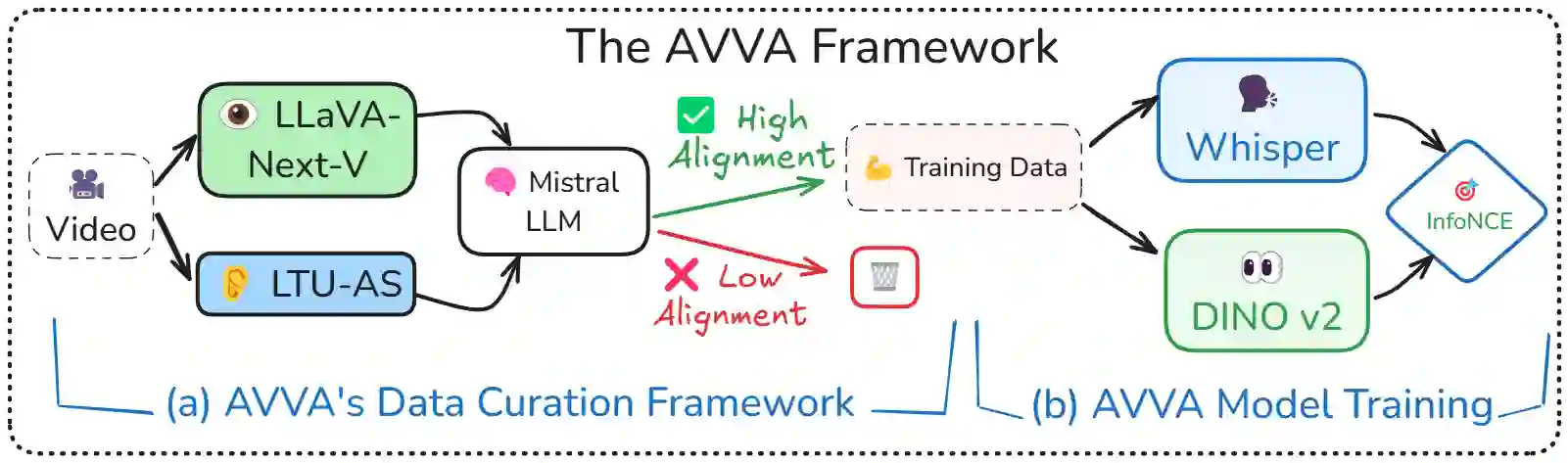
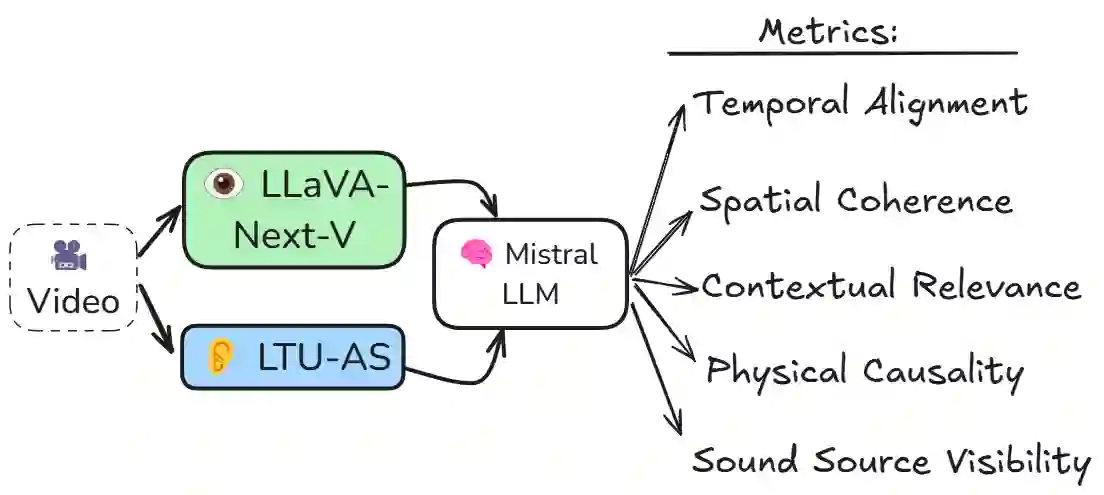
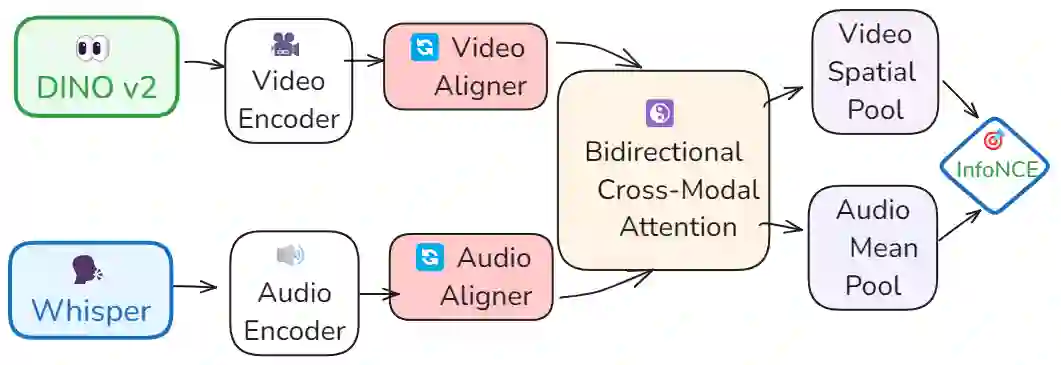
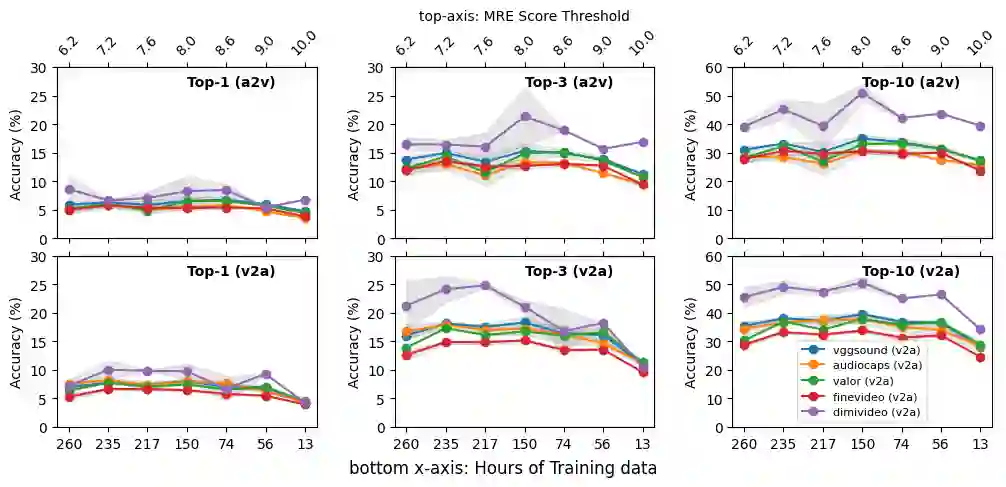
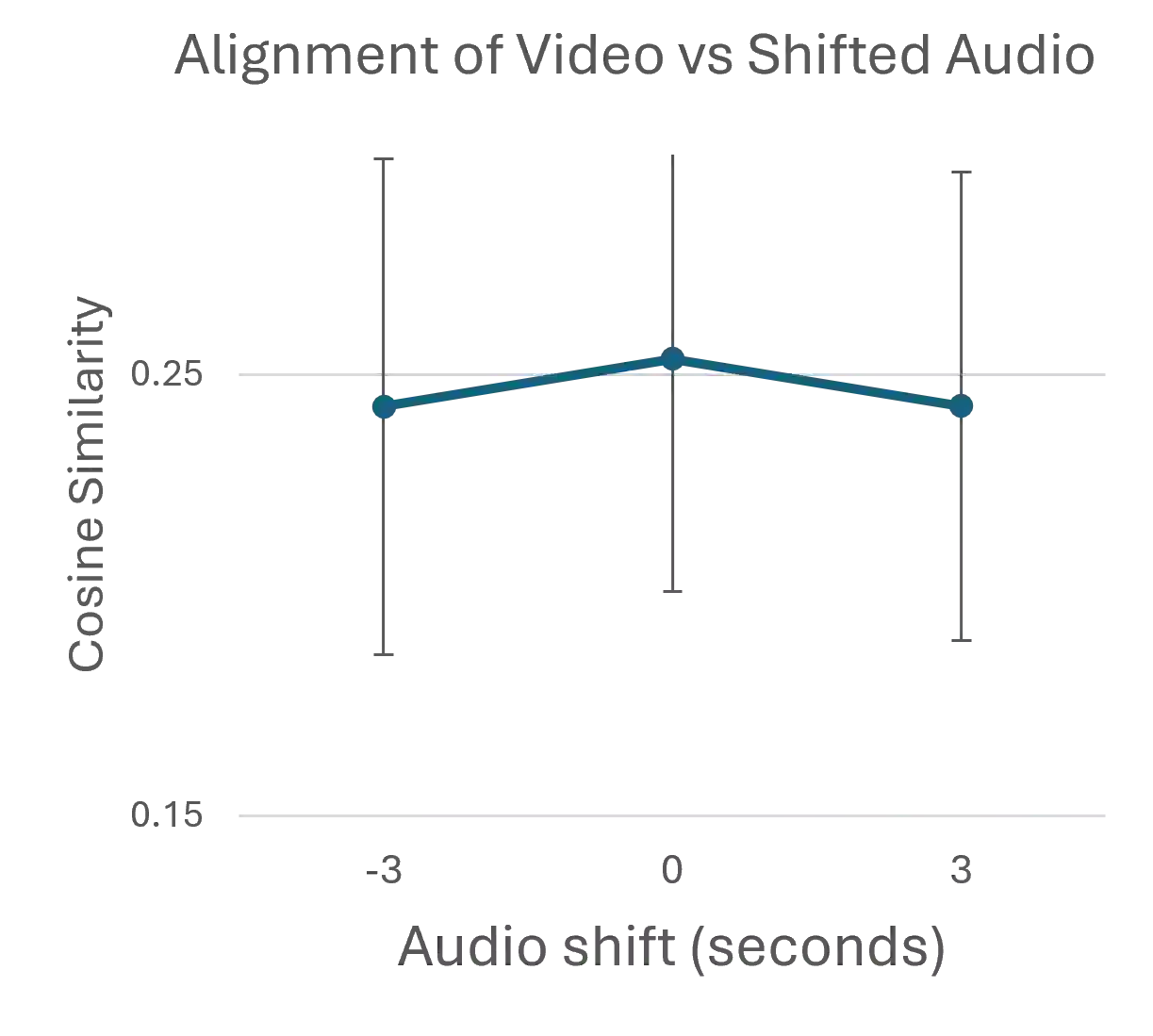
Integrating audio and visual data for training multimodal foundational models remains a challenge. The Audio-Video Vector Alignment (AVVA) framework addresses this by considering AV scene alignment beyond mere temporal synchronization, and leveraging Large Language Models (LLMs) for data curation. AVVA implements a scoring mechanism for selecting aligned training data segments. It integrates Whisper, a speech-based foundation model, for audio and DINOv2 for video analysis in a dual-encoder structure with contrastive learning on AV pairs. Evaluations on AudioCaps, VALOR, and VGGSound demonstrate the effectiveness of the proposed model architecture and data curation approach. AVVA achieves a significant improvement in top-k accuracies for video-to-audio retrieval on all datasets compared to DenseAV, while using only 192 hrs of curated training data. Furthermore, an ablation study indicates that the data curation process effectively trades data quality for data quantity, yielding increases in top-k retrieval accuracies on AudioCaps, VALOR, and VGGSound, compared to training on the full spectrum of uncurated data.
翻译:整合音频与视觉数据以训练多模态基础模型仍具挑战性。音频-视频向量对齐(AVVA)框架通过超越单纯时间同步的AV场景对齐,并利用大语言模型(LLM)进行数据筛选,以应对此挑战。AVVA采用评分机制选择对齐的训练数据片段,集成基于语音的基础模型Whisper进行音频分析,以及DINOv2进行视频分析,构建双编码器结构并在AV数据对上实施对比学习。在AudioCaps、VALOR和VGGSound数据集上的评估验证了所提模型架构与数据筛选方法的有效性。与DenseAV相比,AVVA在所有数据集上的视频到音频检索top-k准确率均显著提升,且仅使用192小时的筛选训练数据。此外,消融研究表明,数据筛选过程有效实现了数据质量对数据量的权衡,与使用全部未筛选数据训练相比,在AudioCaps、VALOR和VGGSound上的top-k检索准确率均获得提升。