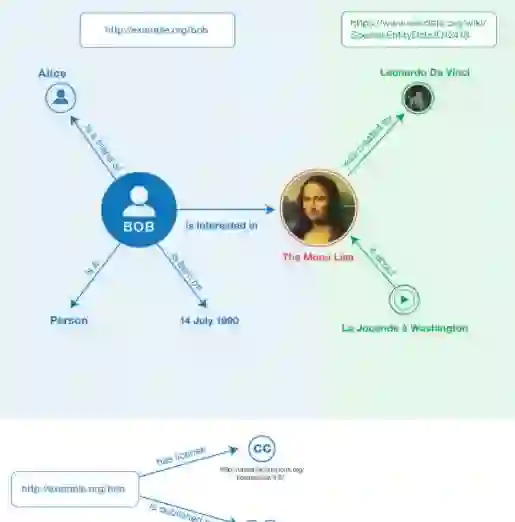
Measuring similarity between RDF graphs is essential for various applications, including knowledge discovery, semantic web analysis, and recommender systems. However, traditional similarity measures often treat all properties equally, potentially overlooking the varying importance of different properties in different contexts. Consequently, exploring weighted property approaches for RDF graph similarity measure presents an intriguing avenue for investigation. Therefore, in this paper, we propose a weighted property approach for RDF graph similarity measure to address this limitation. Our approach incorporates the relative importance of properties into the similarity calculation, enabling a more nuanced and context-aware measures of similarity. We evaluate our approach through a comprehensive experimental study on an RDF graph dataset in the vehicle domain. Our results demonstrate that the proposed approach achieves promising accuracy and effectively reflects the perceived similarity between RDF graphs.
翻译:RDF图之间的相似度度量对于知识发现、语义网分析及推荐系统等多种应用至关重要。然而,传统相似度度量方法往往将所有属性视为同等重要,可能忽略不同属性在不同上下文中的重要性差异。因此,探索面向RDF图相似度度量的加权属性方法提供了一个富有前景的研究方向。本文针对这一局限性,提出了一种面向RDF图相似度度量的加权属性方法。该方法将属性的相对重要性融入相似度计算中,能够实现更精细且更具上下文感知的相似度度量。通过在车辆领域的RDF图数据集上开展全面的实验研究,结果表明所提方法实现了良好的准确度,并有效反映了RDF图之间的感知相似性。