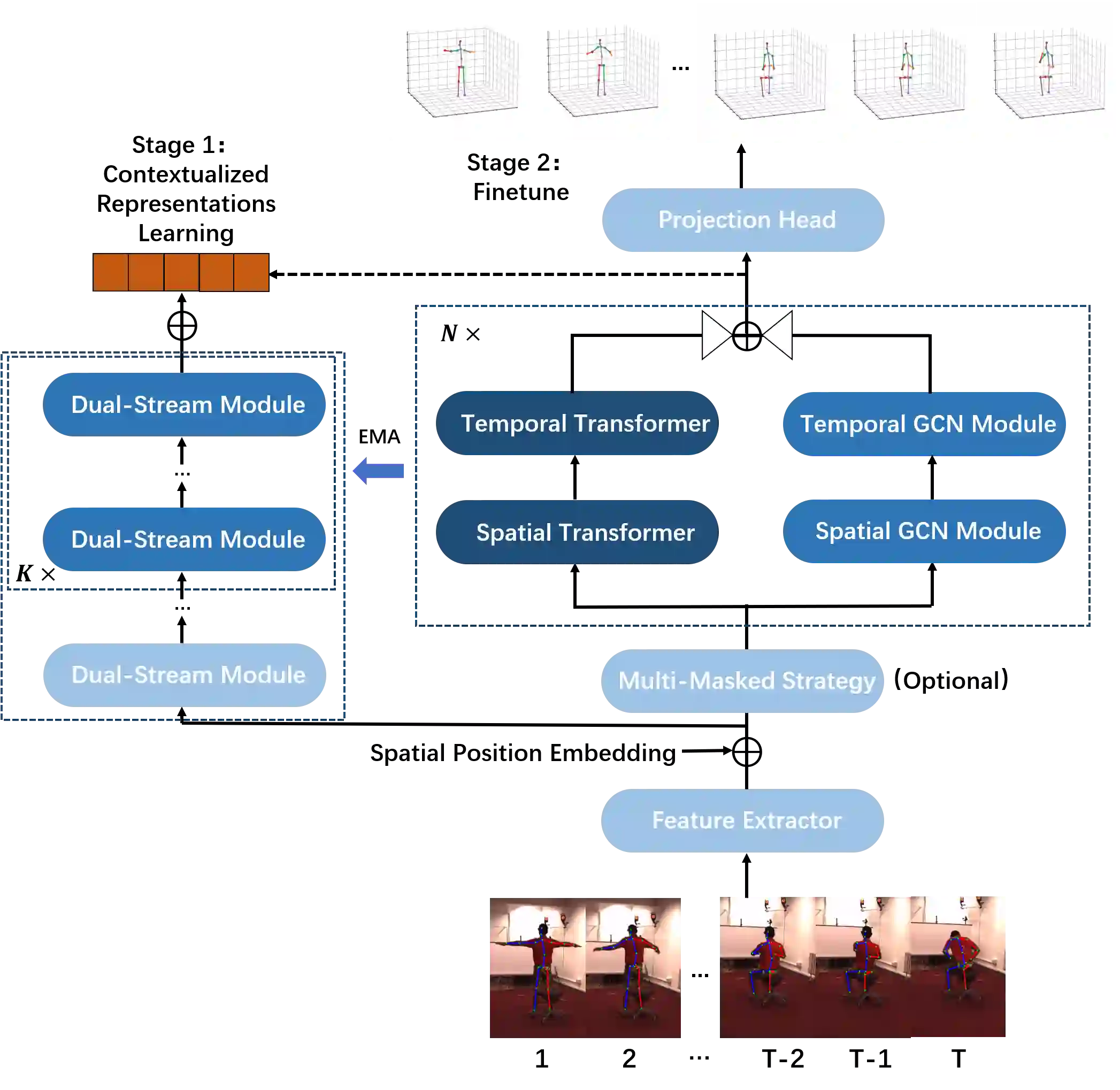
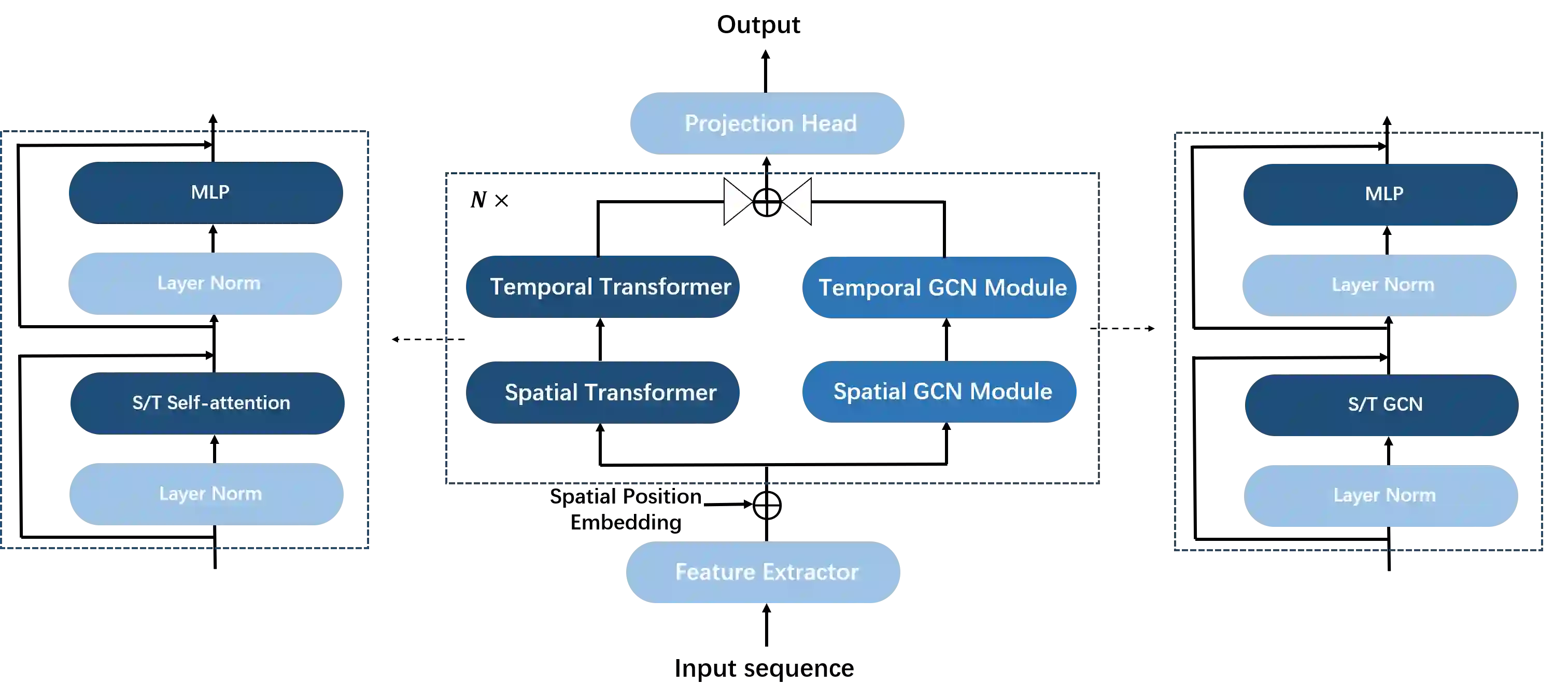
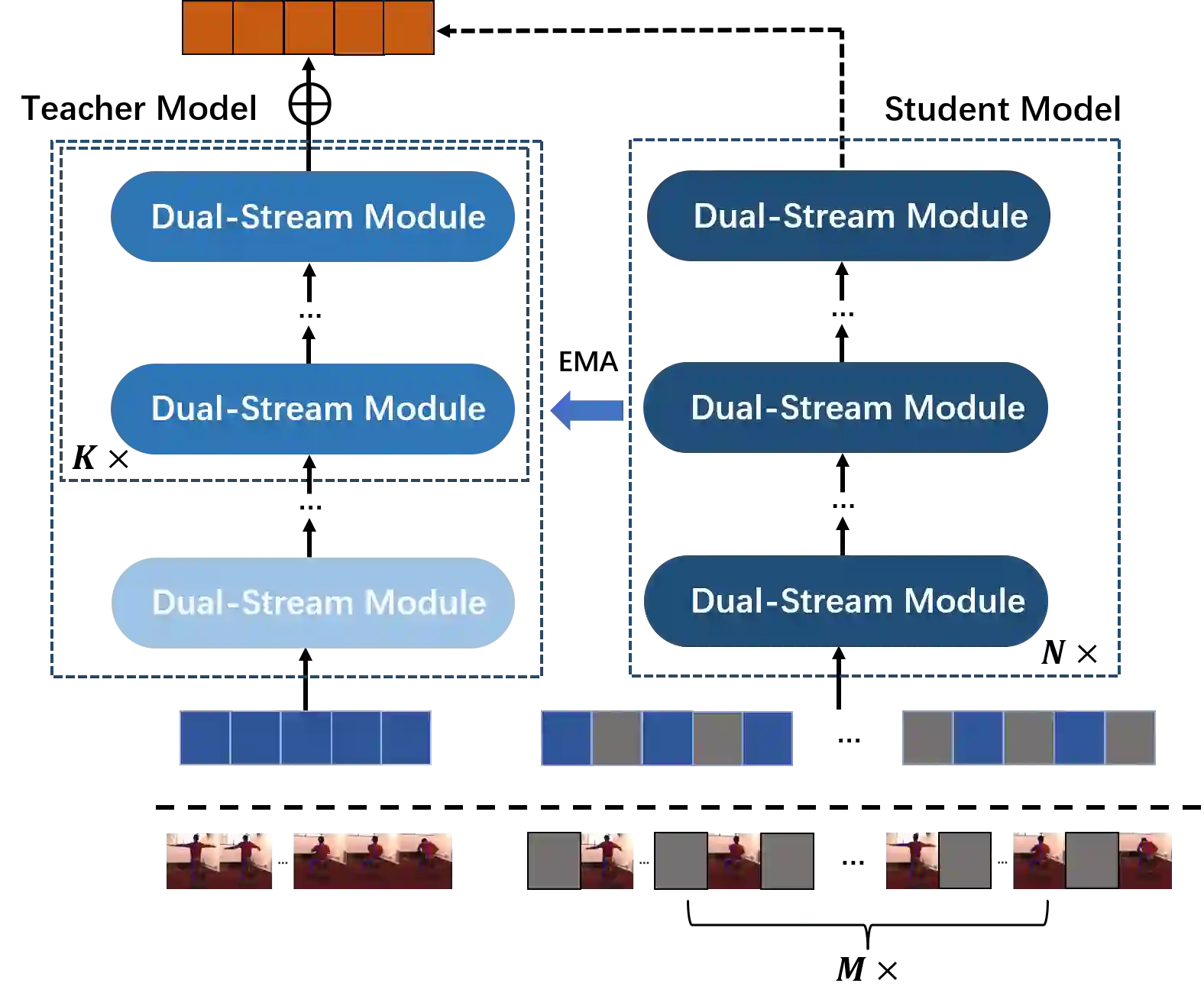
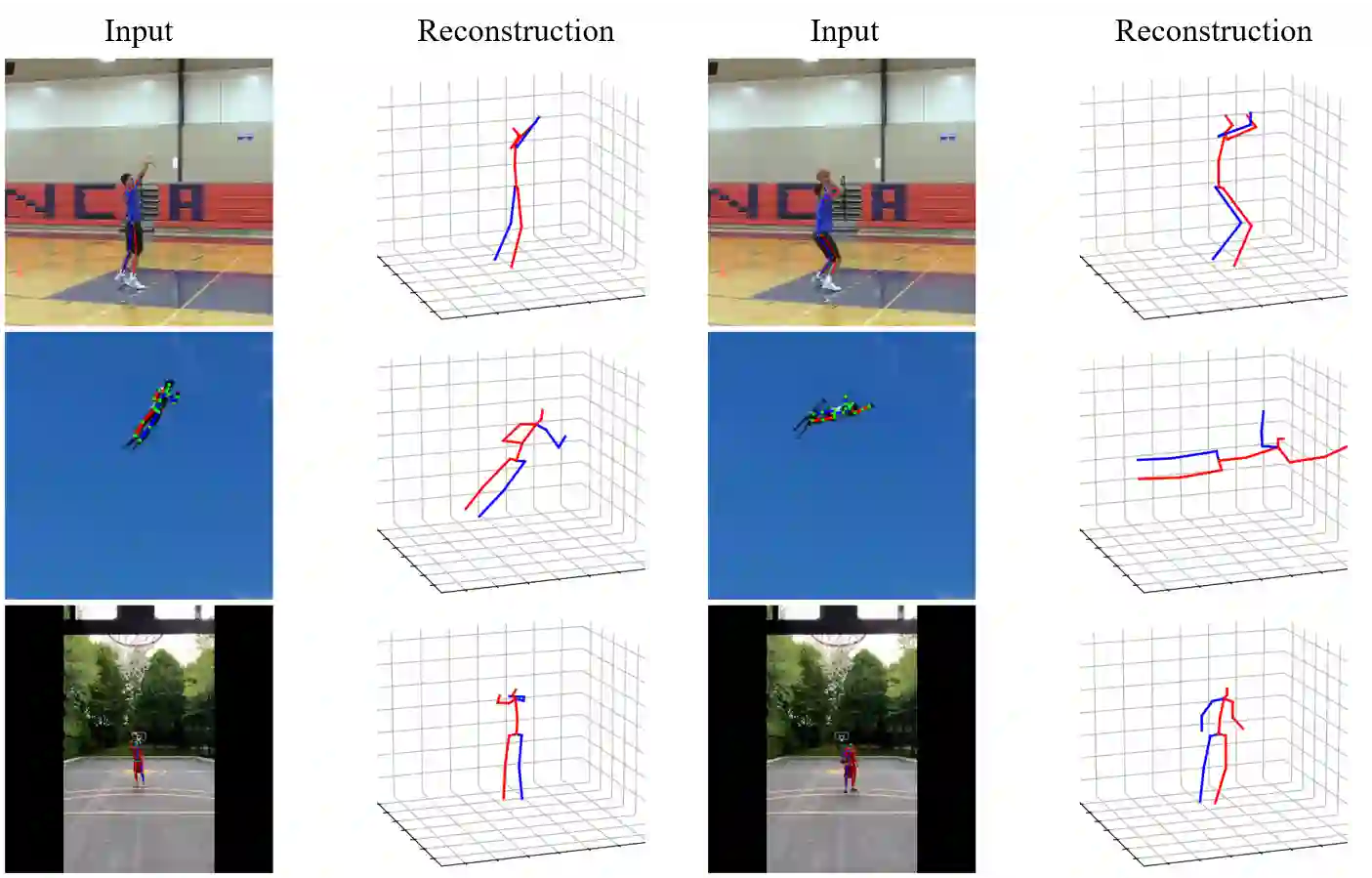
This paper introduces a novel approach to monocular 3D human pose estimation using contextualized representation learning with the Transformer-GCN dual-stream model. Monocular 3D human pose estimation is challenged by depth ambiguity, limited 3D-labeled training data, imbalanced modeling, and restricted model generalization. To address these limitations, our work introduces a groundbreaking motion pre-training method based on contextualized representation learning. Specifically, our method involves masking 2D pose features and utilizing a Transformer-GCN dual-stream model to learn high-dimensional representations through a self-distillation setup. By focusing on contextualized representation learning and spatial-temporal modeling, our approach enhances the model's ability to understand spatial-temporal relationships between postures, resulting in superior generalization. Furthermore, leveraging the Transformer-GCN dual-stream model, our approach effectively balances global and local interactions in video pose estimation. The model adaptively integrates information from both the Transformer and GCN streams, where the GCN stream effectively learns local relationships between adjacent key points and frames, while the Transformer stream captures comprehensive global spatial and temporal features. Our model achieves state-of-the-art performance on two benchmark datasets, with an MPJPE of 38.0mm and P-MPJPE of 31.9mm on Human3.6M, and an MPJPE of 15.9mm on MPI-INF-3DHP. Furthermore, visual experiments on public datasets and in-the-wild videos demonstrate the robustness and generalization capabilities of our approach.
翻译:本文提出了一种基于上下文表征学习的Transformer-GCN双流模型用于单目三维人体姿态估计的新方法。单目三维人体姿态估计面临深度歧义性、三维标注训练数据有限、建模不平衡以及模型泛化能力受限等挑战。为克服这些局限,本研究引入了一种基于上下文表征学习的突破性运动预训练方法。具体而言,该方法通过掩码二维姿态特征,并利用Transformer-GCN双流模型在自蒸馏框架下学习高维表征。通过聚焦于上下文表征学习与时空建模,本方法增强了模型理解姿态间时空关系的能力,从而实现了卓越的泛化性能。此外,借助Transformer-GCN双流模型,本方法有效平衡了视频姿态估计中全局与局部的交互作用。该模型自适应地整合Transformer流与GCN流的信息:GCN流有效学习相邻关键点与帧间的局部关系,而Transformer流则捕捉全面的全局时空特征。我们的模型在两个基准数据集上取得了最先进的性能:在Human3.6M数据集上MPJPE达到38.0毫米、P-MPJPE达到31.9毫米,在MPI-INF-3DHP数据集上MPJPE达到15.9毫米。此外,在公开数据集和真实场景视频上的可视化实验验证了本方法的鲁棒性与泛化能力。