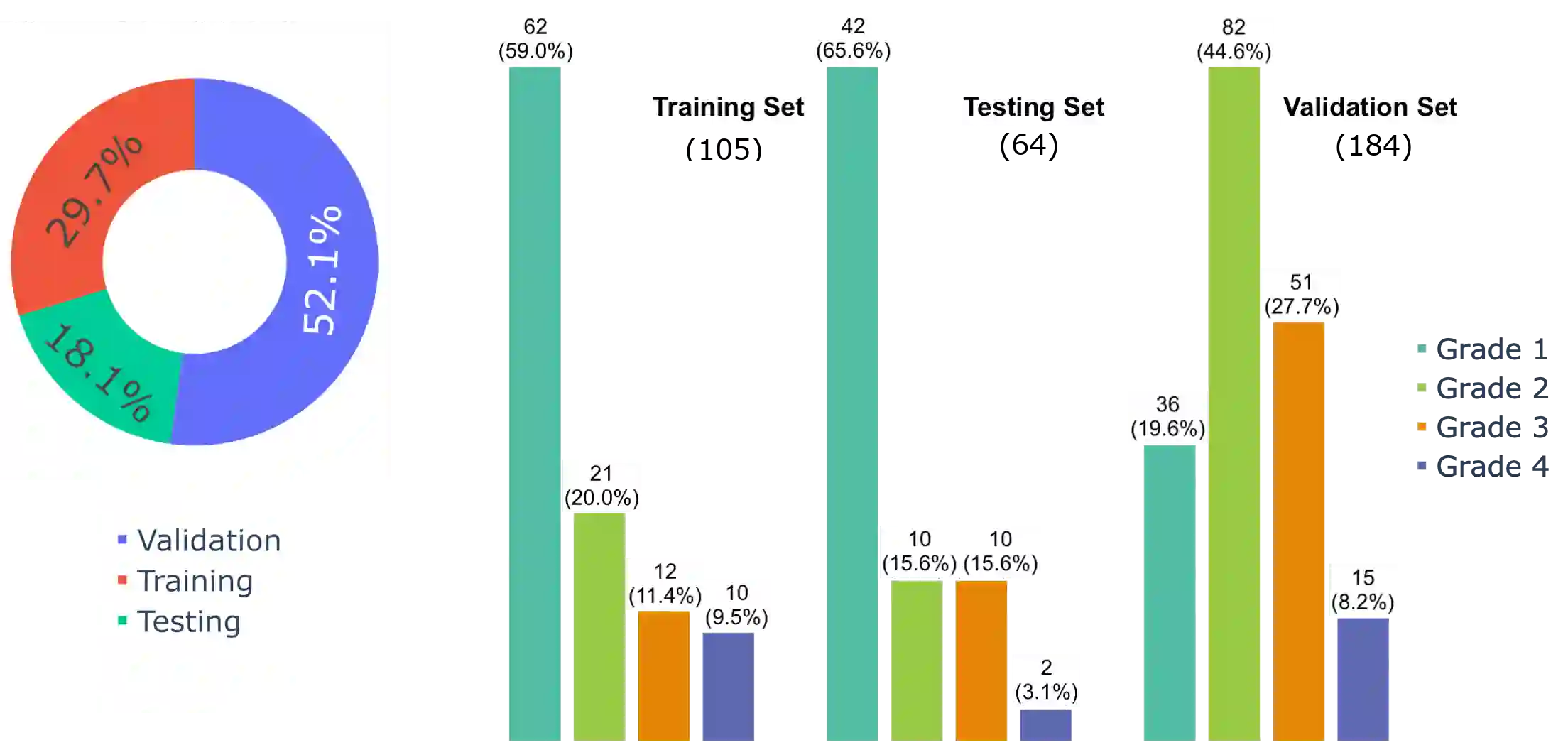
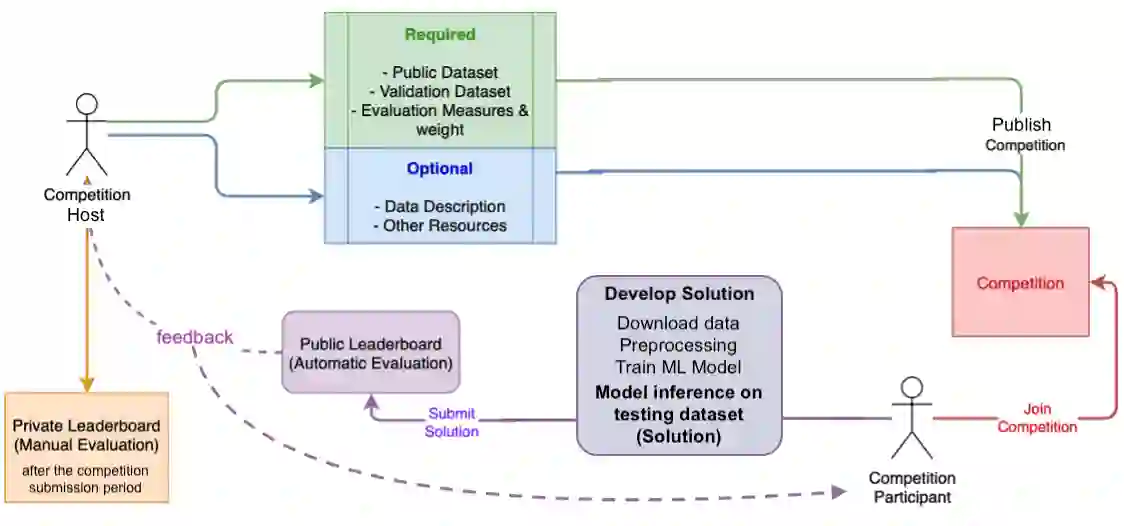
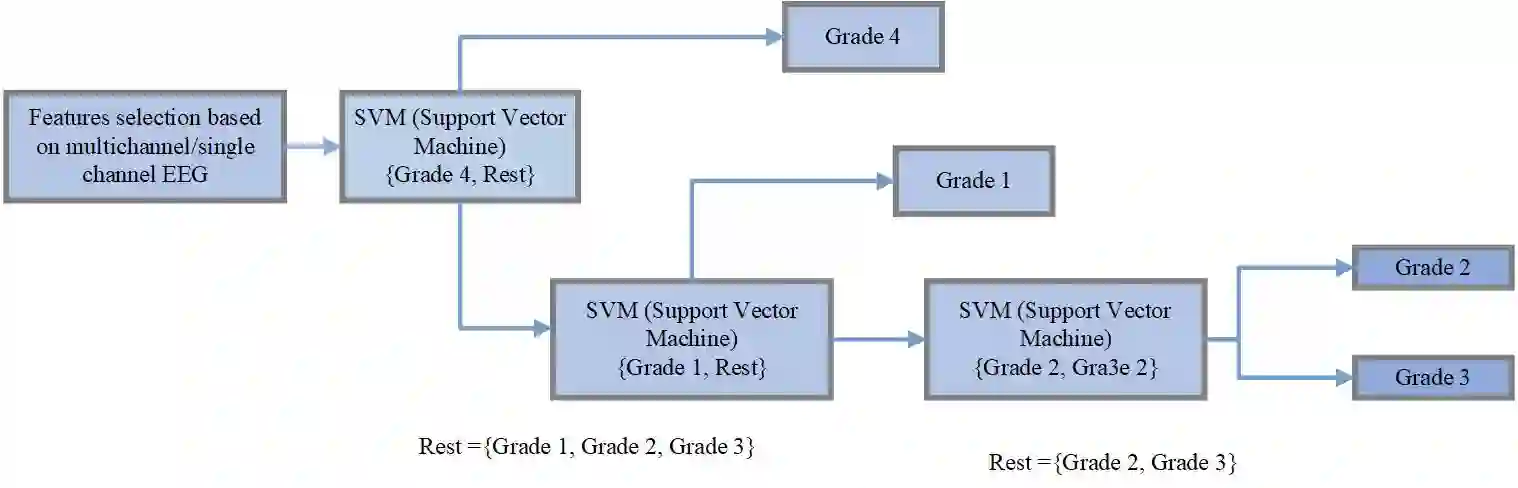
Machine learning (ML) has the potential to support and improve expert performance in monitoring the brain function of at-risk newborns. Developing accurate and reliable ML models depends on access to high-quality, annotated data, a resource in short supply. ML competitions address this need by providing researchers access to expertly annotated datasets, fostering shared learning through direct model comparisons, and leveraging the benefits of crowdsourcing diverse expertise. We compiled a retrospective dataset containing 353 hours of EEG from 102 individual newborns from a multi-centre study. The data was fully anonymised and divided into training, testing, and held-out validation datasets. EEGs were graded for the severity of abnormal background patterns. Next, we created a web-based competition platform and hosted a machine learning competition to develop ML models for classifying the severity of EEG background patterns in newborns. After the competition closed, the top 4 performing models were evaluated offline on a separate held-out validation dataset. Although a feature-based model ranked first on the testing dataset, deep learning models generalised better on the validation sets. All methods had a significant decline in validation performance compared to the testing performance. This highlights the challenges for model generalisation on unseen data, emphasising the need for held-out validation datasets in ML studies with neonatal EEG. The study underscores the importance of training ML models on large and diverse datasets to ensure robust generalisation. The competition's outcome demonstrates the potential for open-access data and collaborative ML development to foster a collaborative research environment and expedite the development of clinical decision-support tools for neonatal neuromonitoring.
翻译:机器学习(ML)在支持和提升专家对高危新生儿脑功能监测的表现方面具有潜力。开发准确可靠的机器学习模型依赖于高质量、带标注的数据,而此类资源目前较为稀缺。机器学习竞赛通过为研究人员提供专家标注的数据集、促进基于直接模型比较的共享学习,并利用众包多样化专业知识的优势,来满足这一需求。我们整理了一个回顾性数据集,包含来自多中心研究的102名新生儿共计353小时的脑电图数据。数据已完全匿名化,并划分为训练集、测试集和保留验证集。脑电图根据异常背景模式的严重程度进行了分级。随后,我们创建了一个基于网络的竞赛平台,并举办了一场机器学习竞赛,旨在开发用于分类新生儿脑电图背景模式严重程度的机器学习模型。竞赛结束后,排名前四的模型在一个独立的保留验证集上进行了离线评估。尽管在测试数据集上基于特征的方法模型排名第一,但深度学习模型在验证集上表现出更好的泛化能力。所有方法在验证集上的性能相较于测试集均有显著下降。这凸显了模型在未见数据上泛化所面临的挑战,强调了在新生儿脑电图机器学习研究中设置保留验证集的必要性。本研究强调了在大型多样化数据集上训练机器学习模型以确保稳健泛化的重要性。竞赛结果展示了开放获取数据和协作式机器学习开发在促进合作研究环境、加速新生儿神经监测临床决策支持工具开发方面的潜力。