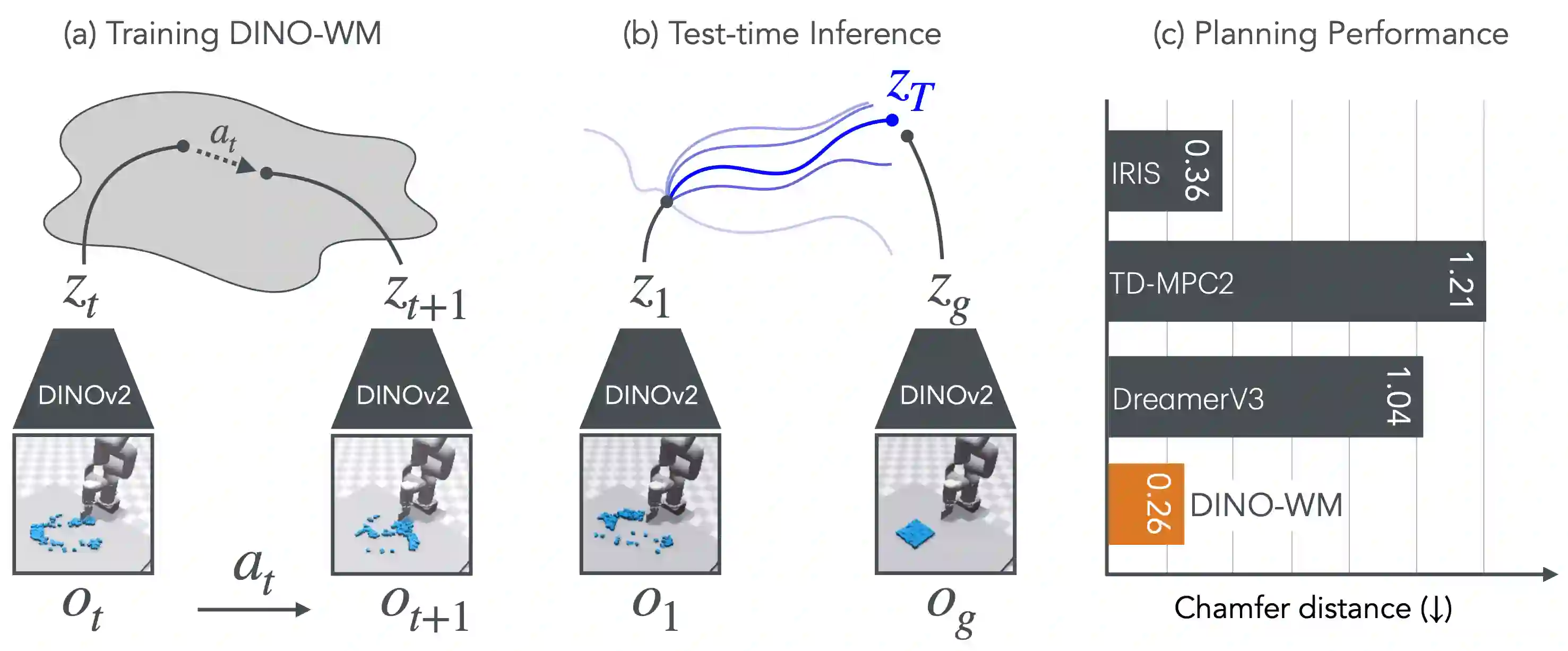
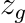The ability to predict future outcomes given control actions is fundamental for physical reasoning. However, such predictive models, often called world models, have proven challenging to learn and are typically developed for task-specific solutions with online policy learning. We argue that the true potential of world models lies in their ability to reason and plan across diverse problems using only passive data. Concretely, we require world models to have the following three properties: 1) be trainable on offline, pre-collected trajectories, 2) support test-time behavior optimization, and 3) facilitate task-agnostic reasoning. To realize this, we present DINO World Model (DINO-WM), a new method to model visual dynamics without reconstructing the visual world. DINO-WM leverages spatial patch features pre-trained with DINOv2, enabling it to learn from offline behavioral trajectories by predicting future patch features. This design allows DINO-WM to achieve observational goals through action sequence optimization, facilitating task-agnostic behavior planning by treating desired goal patch features as prediction targets. We evaluate DINO-WM across various domains, including maze navigation, tabletop pushing, and particle manipulation. Our experiments demonstrate that DINO-WM can generate zero-shot behavioral solutions at test time without relying on expert demonstrations, reward modeling, or pre-learned inverse models. Notably, DINO-WM exhibits strong generalization capabilities compared to prior state-of-the-art work, adapting to diverse task families such as arbitrarily configured mazes, push manipulation with varied object shapes, and multi-particle scenarios.
翻译:在给定控制动作的情况下预测未来结果的能力是物理推理的基础。然而,这类通常被称为世界模型的预测模型已被证明难以学习,并且通常是为结合在线策略学习的任务特定解决方案而开发的。我们认为,世界模型的真正潜力在于其仅利用被动数据就能在不同问题上进行推理和规划的能力。具体而言,我们要求世界模型具备以下三个属性:1) 可在离线预收集的轨迹上进行训练,2) 支持测试时的行为优化,3) 促进任务无关的推理。为实现这一目标,我们提出了DINO世界模型(DINO-WM),这是一种无需重建视觉世界即可对视觉动态进行建模的新方法。DINO-WM利用了通过DINOv2预训练的空间图像块特征,使其能够通过预测未来的图像块特征来从离线行为轨迹中学习。这种设计使得DINO-WM能够通过动作序列优化来实现观测目标,通过将期望的目标图像块特征作为预测目标,从而促进任务无关的行为规划。我们在多个领域评估了DINO-WM,包括迷宫导航、桌面推物和粒子操控。我们的实验表明,DINO-WM能够在测试时生成零样本行为解决方案,而无需依赖专家演示、奖励建模或预学习的逆模型。值得注意的是,与先前最先进的工作相比,DINO-WM展现出强大的泛化能力,能够适应多样化的任务族,例如任意配置的迷宫、不同物体形状的推物操作以及多粒子场景。