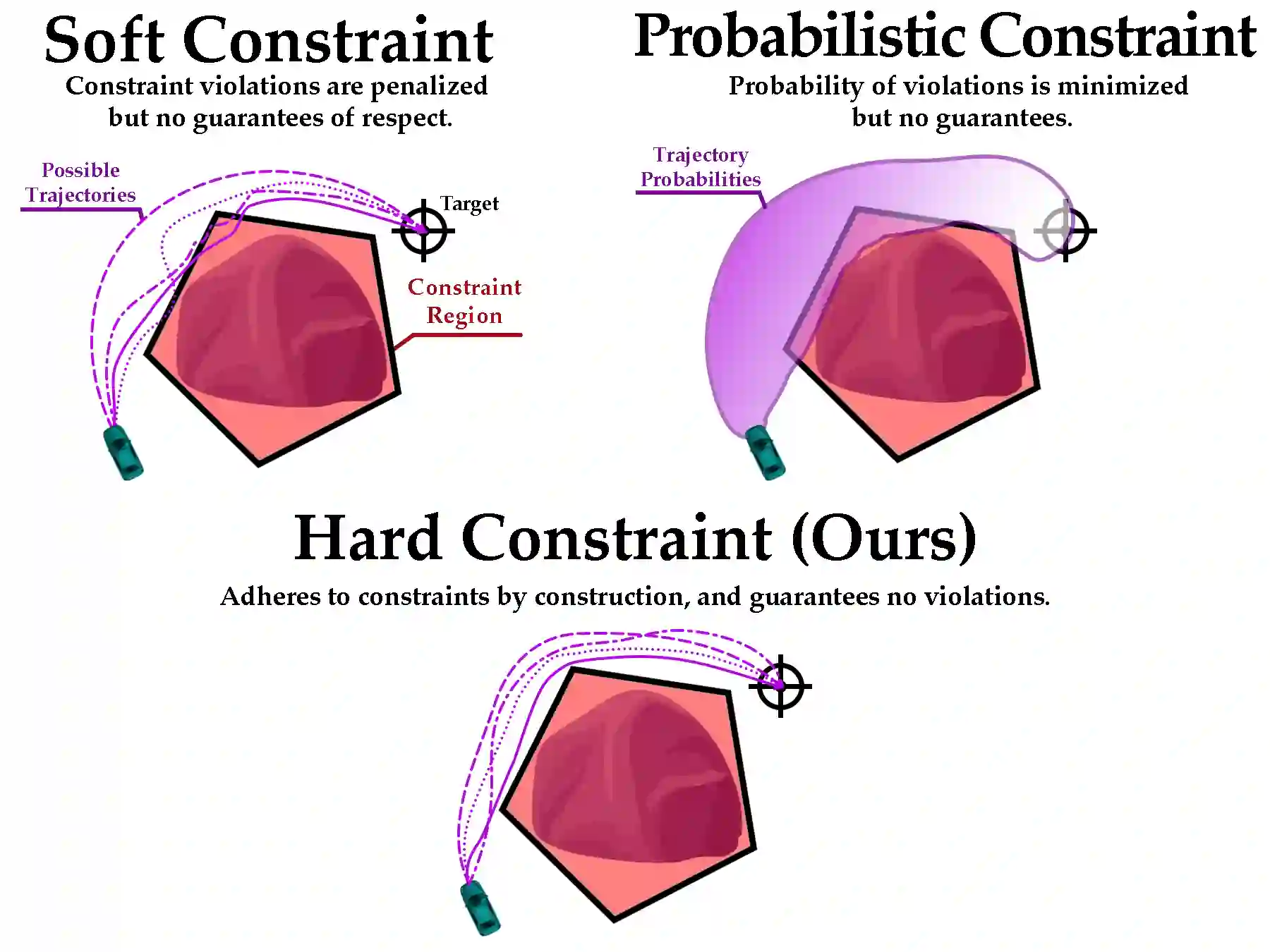
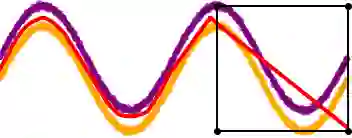
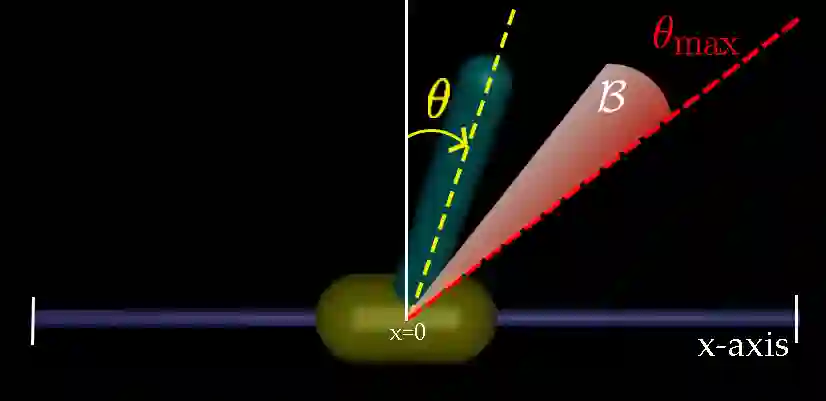
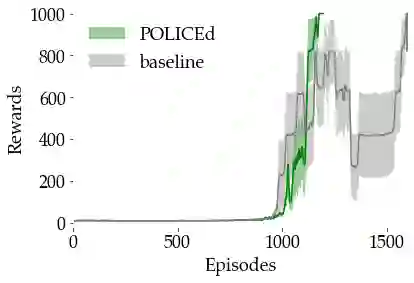
In this paper, we seek to learn a robot policy guaranteed to satisfy state constraints. To encourage constraint satisfaction, existing RL algorithms typically rely on Constrained Markov Decision Processes and discourage constraint violations through reward shaping. However, such soft constraints cannot offer verifiable safety guarantees. To address this gap, we propose POLICEd RL, a novel RL algorithm explicitly designed to enforce affine hard constraints in closed-loop with a black-box environment. Our key insight is to force the learned policy to be affine around the unsafe set and use this affine region as a repulsive buffer to prevent trajectories from violating the constraint. We prove that such policies exist and guarantee constraint satisfaction. Our proposed framework is applicable to both systems with continuous and discrete state and action spaces and is agnostic to the choice of the RL training algorithm. Our results demonstrate the capacity of POLICEd RL to enforce hard constraints in robotic tasks while significantly outperforming existing methods.
翻译:本文旨在学习一种能够保证满足状态约束的机器人策略。现有强化学习算法通常依赖于约束马尔可夫决策过程,并通过奖励塑形来抑制约束违反。然而,此类软约束无法提供可验证的安全性保证。为弥补这一不足,我们提出POLICEd RL——一种新颖的强化学习算法,其明确设计用于在黑盒环境的闭环中强制执行仿射硬约束。我们的核心见解是强制学习策略在不安全集附近呈仿射特性,并利用该仿射区域作为排斥缓冲区以防止轨迹违反约束。我们证明了此类策略的存在性及其对约束满足性的保证。所提出的框架适用于具有连续和离散状态与动作空间的系统,且与具体强化学习训练算法的选择无关。实验结果表明,POLICEd RL能够在机器人任务中强制执行硬约束,同时显著优于现有方法。