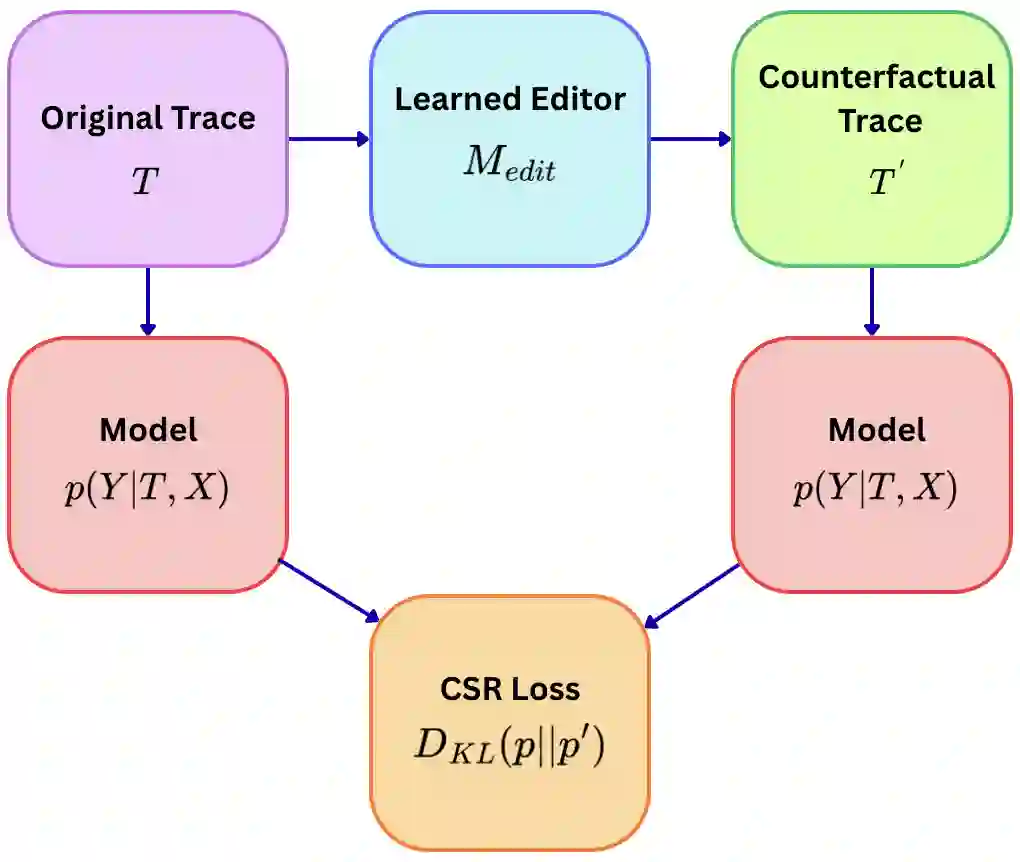
Large language models can produce correct answers while relying on flawed reasoning traces, partly because common training objectives reward final-answer correctness rather than faithful intermediate reasoning. This undermines trustworthiness in high-stakes settings. We propose Counterfactual Sensitivity Regularization (CSR), a training paradigm that improves reasoning faithfulness by enforcing causal consistency between reasoning steps and outcomes. CSR automatically applies operator-level interventions to reasoning traces, such as swapping "+" with "-", to generate minimally perturbed counterfactual rationales, and penalizes the model when these logically invalid traces still lead to the original answer. Our implementation is efficient, adding about 9 percent training overhead via a warm-start curriculum and token-subset optimization. We evaluate faithfulness using Counterfactual Outcome Sensitivity (COS), which measures how appropriately answers change under logical perturbations. Across arithmetic (GSM8K), logical deduction (ProofWriter), multi-hop question answering (HotpotQA), and code generation (MBPP), CSR yields improved accuracy versus faithfulness trade-offs, establishing a new Pareto frontier. CSR improves faithfulness over standard fine-tuning and process supervision by up to 70 percentage points, and transfers across model families with 94.2 to 96.7 percent success in structured domains. CSR also complements inference-time methods such as self-consistency. Overall, CSR offers a practical route to more reliable reasoning in structured domains, including mathematics, formal logic, and code, where operators are well-defined and verifiable, covering an estimated 40 to 60 percent of high-stakes reasoning deployments.
翻译:大型语言模型可能在依赖有缺陷的推理轨迹时仍产生正确答案,部分原因在于常见的训练目标仅奖励最终答案的正确性,而非忠实的中介推理。这削弱了高风险场景下的可信度。我们提出反事实敏感性正则化(CSR),一种通过强制推理步骤与结果间的因果一致性来提升推理忠实性的训练范式。CSR自动对推理轨迹施加操作符层面的干预(例如将“+”替换为“-”),以生成最小扰动的反事实依据,并在这些逻辑无效的轨迹仍导向原始答案时对模型进行惩罚。我们的实现高效,通过热启动课程与令牌子集优化仅增加约9%的训练开销。我们使用反事实结果敏感性(COS)评估忠实性,该指标衡量答案在逻辑扰动下发生恰当改变的程度。在算术(GSM8K)、逻辑演绎(ProofWriter)、多跳问答(HotpotQA)和代码生成(MBPP)任务上,CSR实现了准确性与忠实性权衡的改进,确立了新的帕累托前沿。与标准微调和过程监督相比,CSR将忠实性提升高达70个百分点,并在结构化领域中跨模型族迁移成功率达94.2%至96.7%。CSR还能与自洽性等推理时方法互补。总体而言,CSR为结构化领域(包括数学、形式逻辑和代码)中更可靠的推理提供了一条实用路径,这些领域操作符定义明确且可验证,覆盖了约40%至60%的高风险推理部署场景。