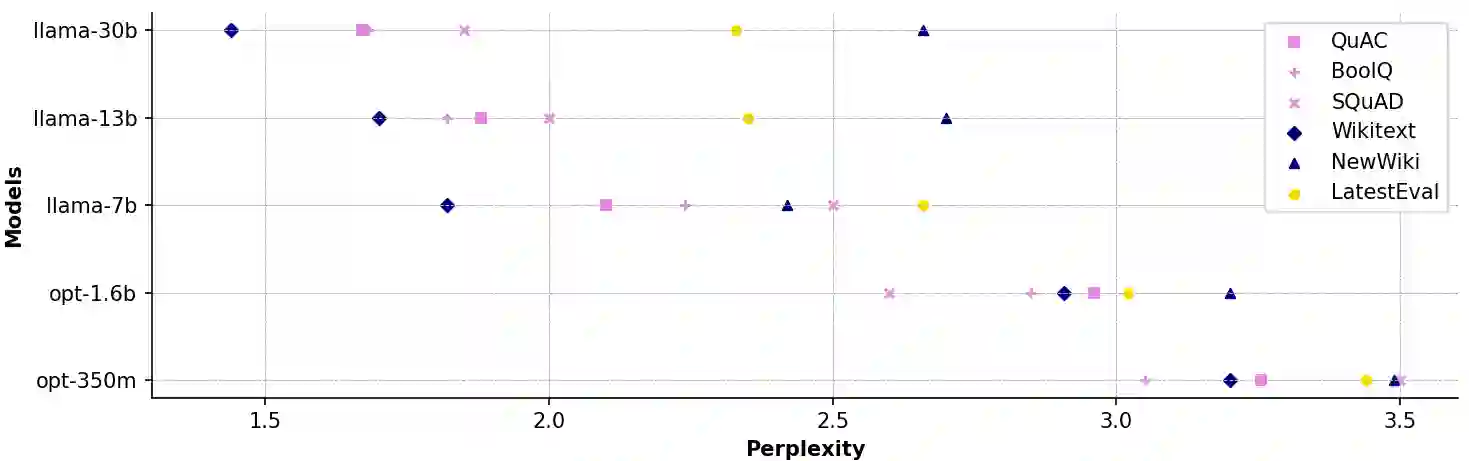
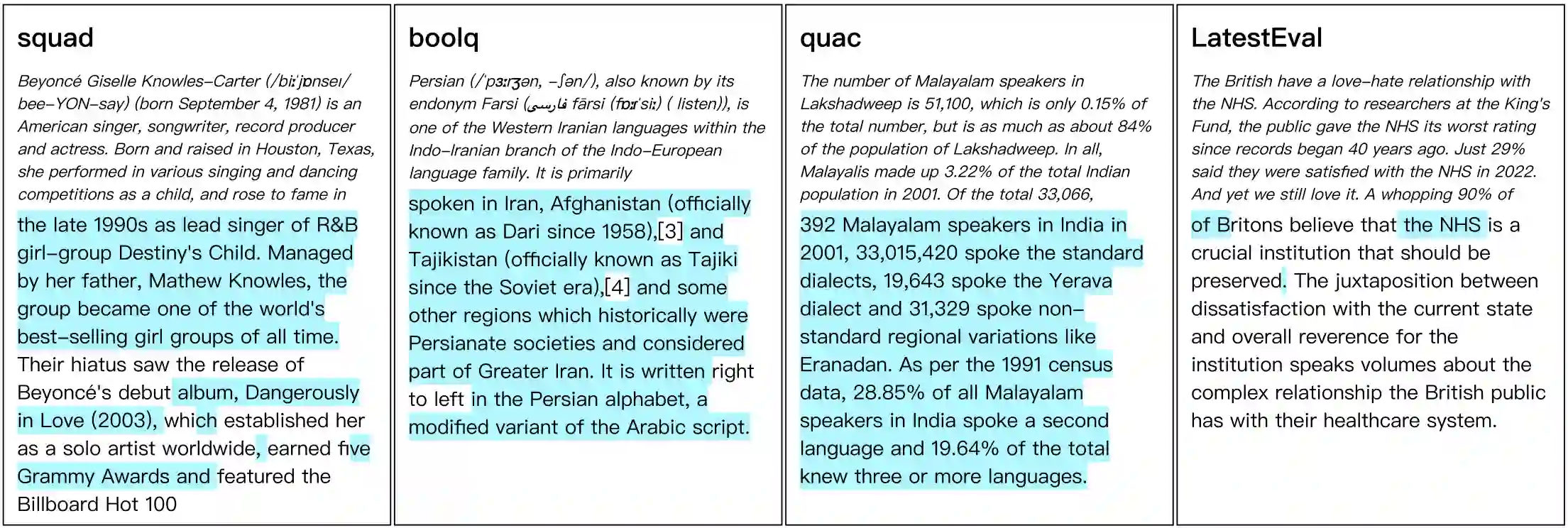
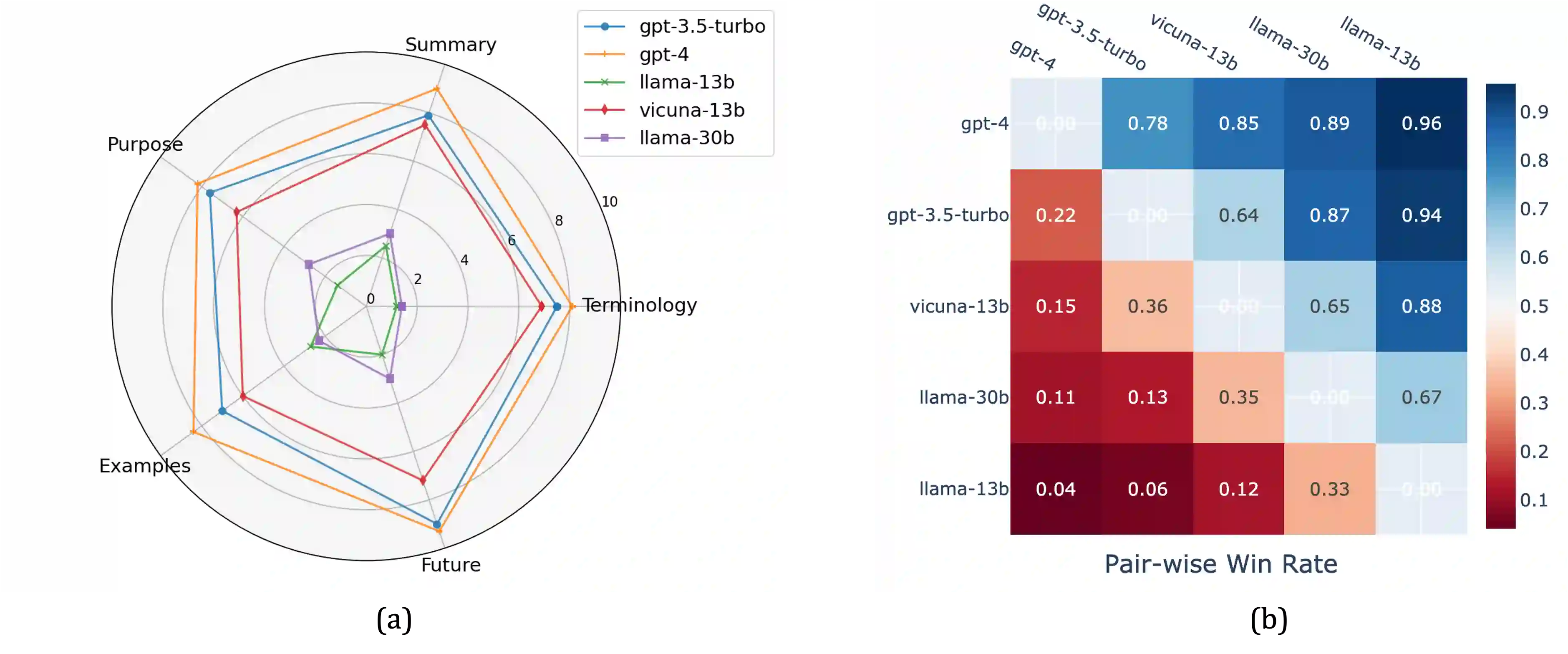
Data contamination in evaluation is getting increasingly prevalent with the emerge of language models pre-trained on super large, automatically-crawled corpora. This problem leads to significant challenges in accurate assessment of model capabilities and generalisations. In this paper, we propose LatestEval, an automatic method leverages the most recent texts to create uncontaminated reading comprehension evaluations. LatestEval avoids data contamination by only using texts published within a recent time window, ensuring no overlap with the training corpora of pre-trained language models. We develop LatestEval automated pipeline to 1) gather latest texts; 2) identify key information, and 3) construct questions targeting the information while removing the existing answers from the context. This encourages models to infer the answers themselves based on the remaining context, rather than just copy-paste. Our experiments demonstrate that language models exhibit negligible memorisation behaviours on LatestEval as opposed to previous benchmarks, suggesting a significantly reduced risk of data contamination and leading to a more robust evaluation. Data and code are publicly available at: https://github.com/liyucheng09/LatestEval.
翻译:随着基于超大规模自动爬取语料库预训练的语言模型出现,评估中的数据污染问题日益普遍。这一问题导致对模型能力与泛化性能的准确评估面临严峻挑战。本文提出LatestEval方法,这是一种利用最新文本自动构建无污染阅读理解评估的自动化方案。LatestEval通过仅采用近期发布时间窗口内的文本,确保与预训练语言模型的训练语料无重叠,从而避免数据污染。我们开发了LatestEval自动化流水线,包含以下步骤:1)采集最新文本;2)识别关键信息;3)构建针对该信息的问题,并从上下文中移除现有答案。该方法鼓励模型基于剩余上下文自主推断答案,而非简单复制粘贴。实验表明,与以往基准测试相比,语言模型在LatestEval上表现出可忽略的记忆行为,表明数据污染风险显著降低,从而实现更稳健的评估。数据和代码已开源在:https://github.com/liyucheng09/LatestEval。