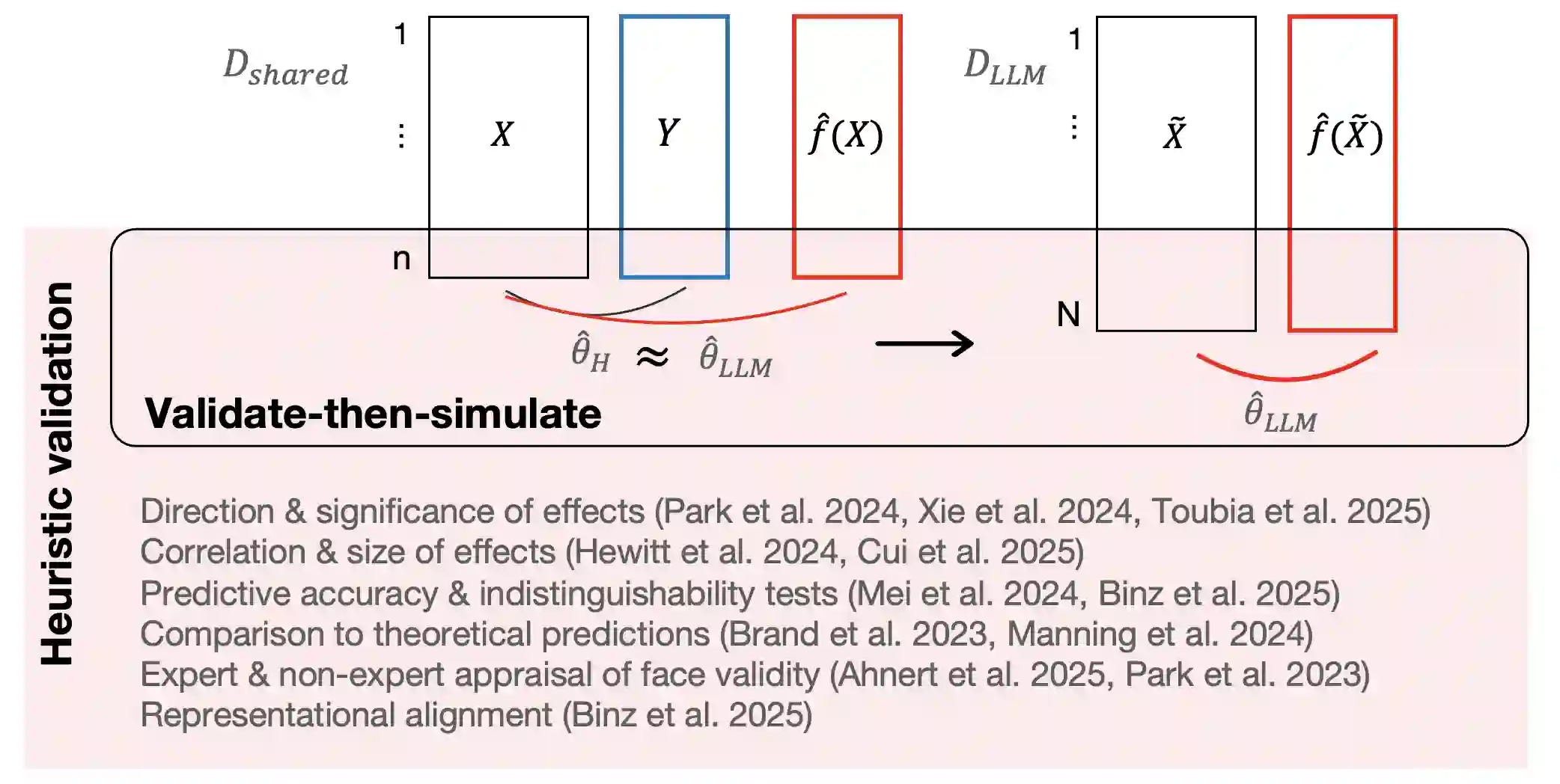
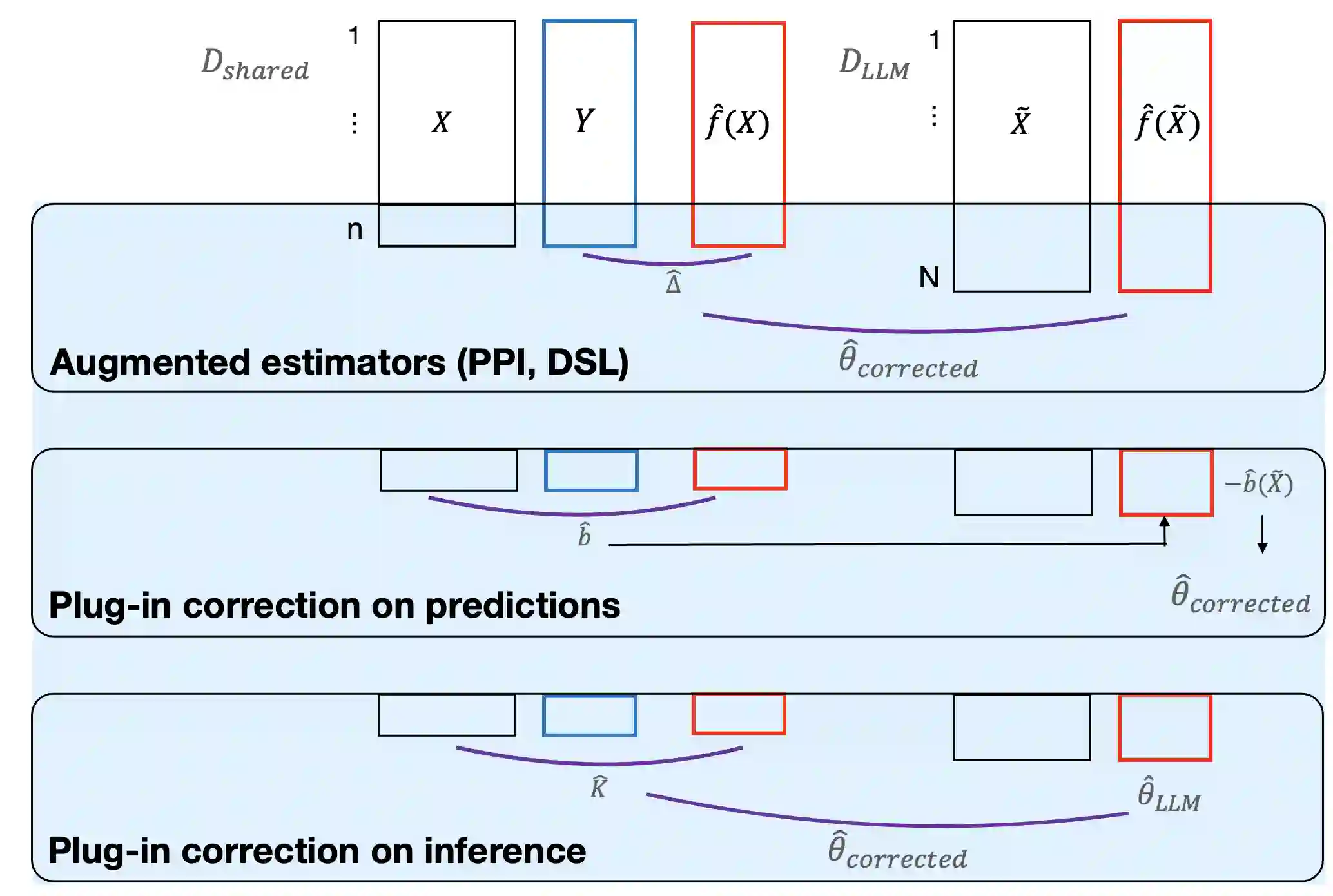
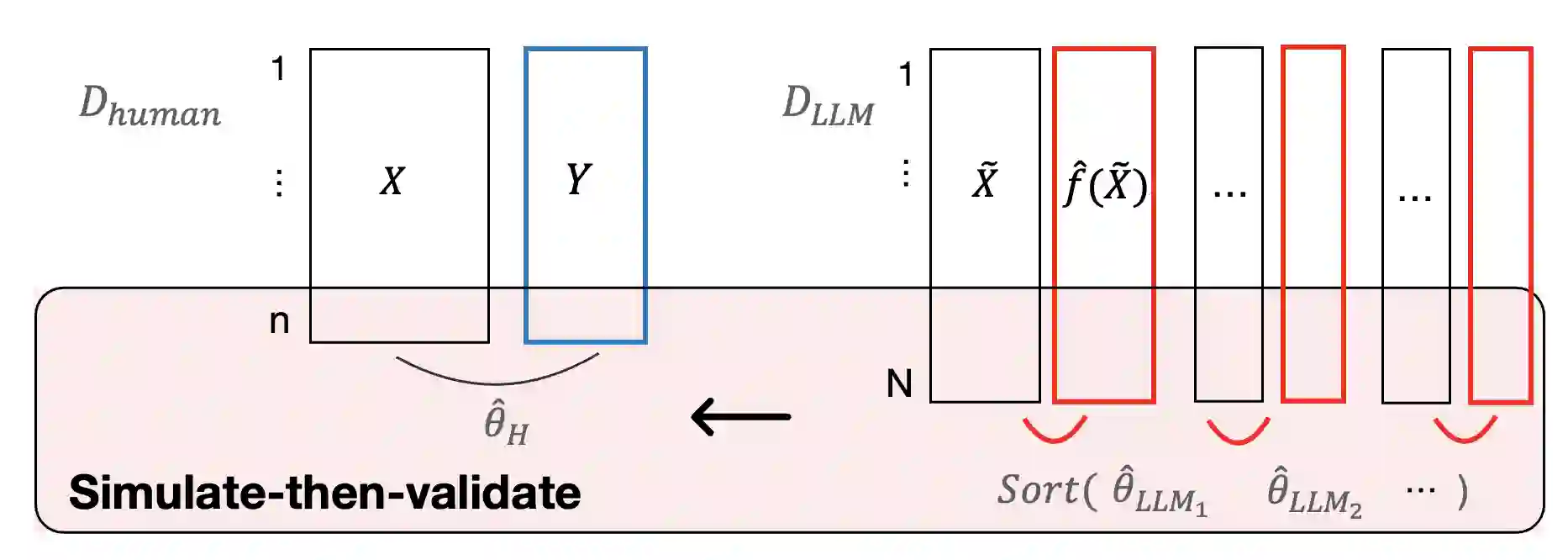
A growing literature uses large language models (LLMs) as synthetic participants to generate cost-effective and nearly instantaneous responses in social science experiments. However, there is limited guidance on when such simulations support valid inference about human behavior. We contrast two strategies for obtaining valid estimates of causal effects and clarify the assumptions under which each is suitable for exploratory versus confirmatory research. Heuristic approaches seek to establish that simulated and observed human behavior are interchangeable through prompt engineering, model fine-tuning, and other repair strategies designed to reduce LLM-induced inaccuracies. While useful for many exploratory tasks, heuristic approaches lack the formal statistical guarantees typically required for confirmatory research. In contrast, statistical calibration combines auxiliary human data with statistical adjustments to account for discrepancies between observed and simulated responses. Under explicit assumptions, statistical calibration preserves validity and provides more precise estimates of causal effects at lower cost than experiments that rely solely on human participants. Yet the potential of both approaches depends on how well LLMs approximate the relevant populations. We consider what opportunities are overlooked when researchers focus myopically on substituting LLMs for human participants in a study.
翻译:越来越多的研究使用大型语言模型(LLM)作为合成参与者,以在社会科学实验中生成成本效益高且近乎即时的响应。然而,关于此类模拟何时能够支持对人类行为的有效推断,目前指导有限。我们对比了两种获取因果效应有效估计的策略,并阐明了每种策略适用于探索性研究与验证性研究的假设条件。启发式方法旨在通过提示工程、模型微调及其他旨在减少LLM引入误差的修正策略,确立模拟行为与观测到的人类行为可互换。尽管启发式方法对许多探索性任务有用,但缺乏验证性研究通常所需的正式统计保证。相比之下,统计校准将辅助人类数据与统计调整相结合,以解释观测响应与模拟响应之间的差异。在明确假设下,统计校准保持了有效性,并以比仅依赖人类参与者的实验更低的成本提供更精确的因果效应估计。然而,两种方法的潜力均取决于LLM对相关人群的近似程度。我们探讨了当研究者狭隘地专注于在研究中用LLM替代人类参与者时,哪些机会被忽视了。