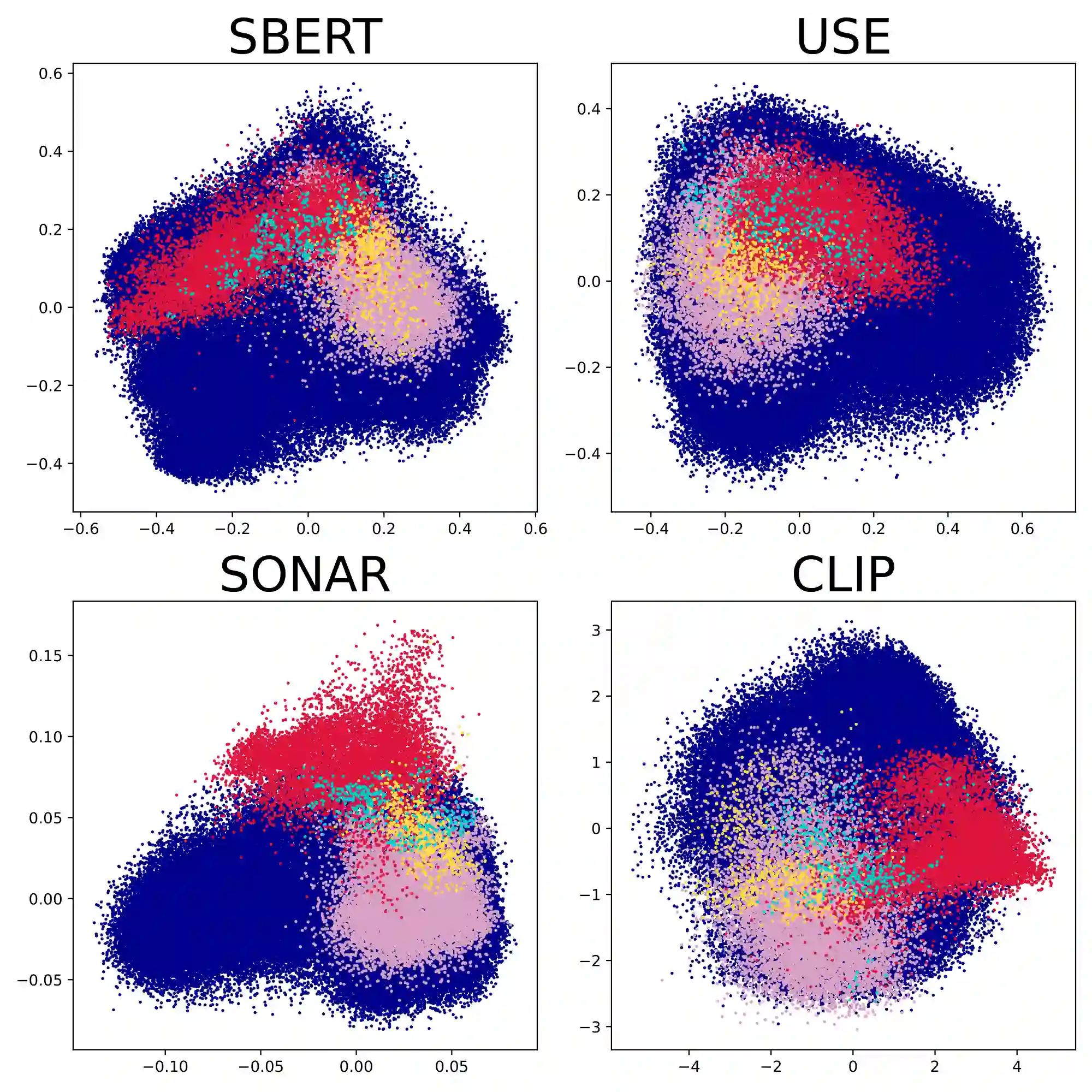
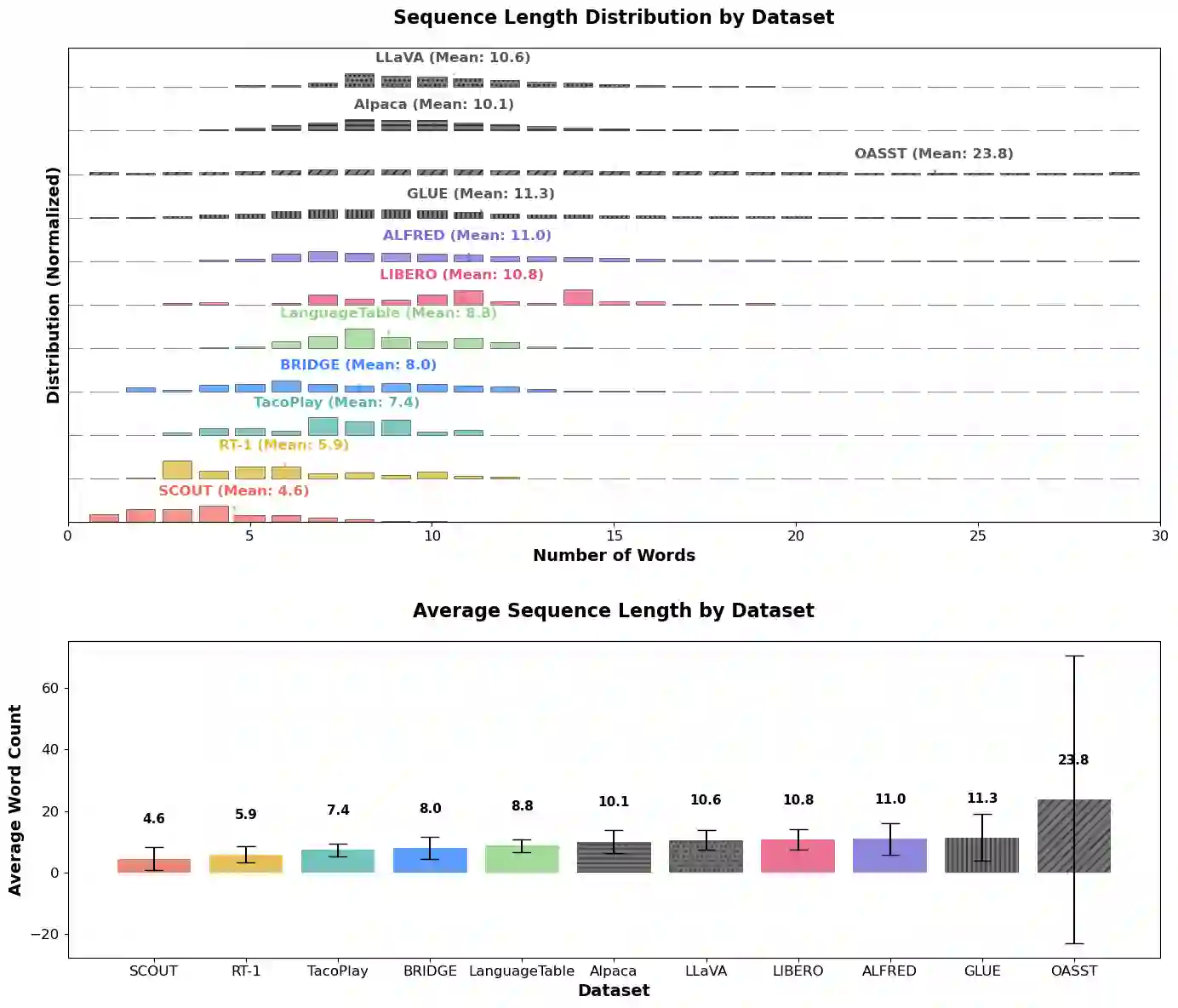
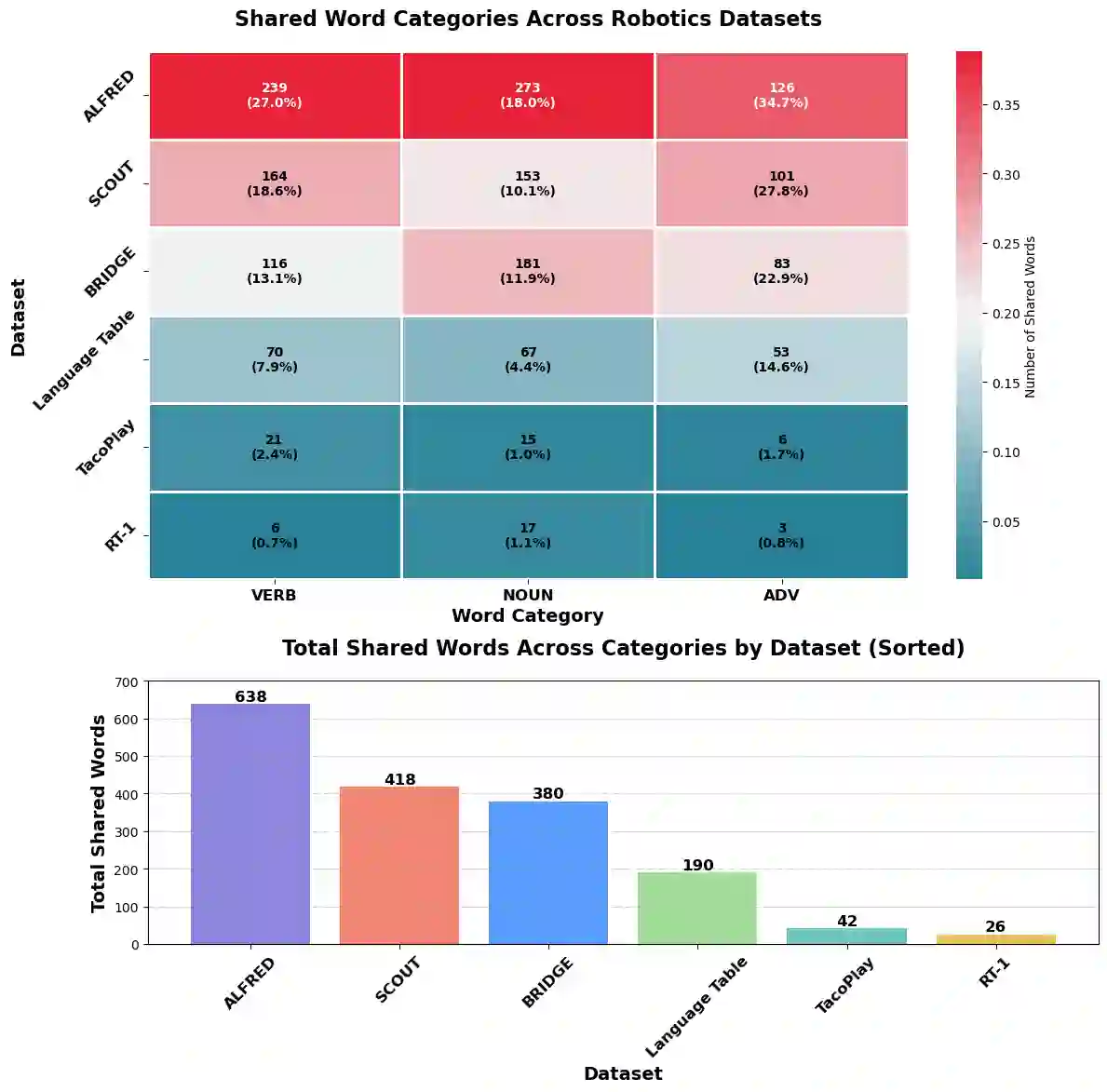
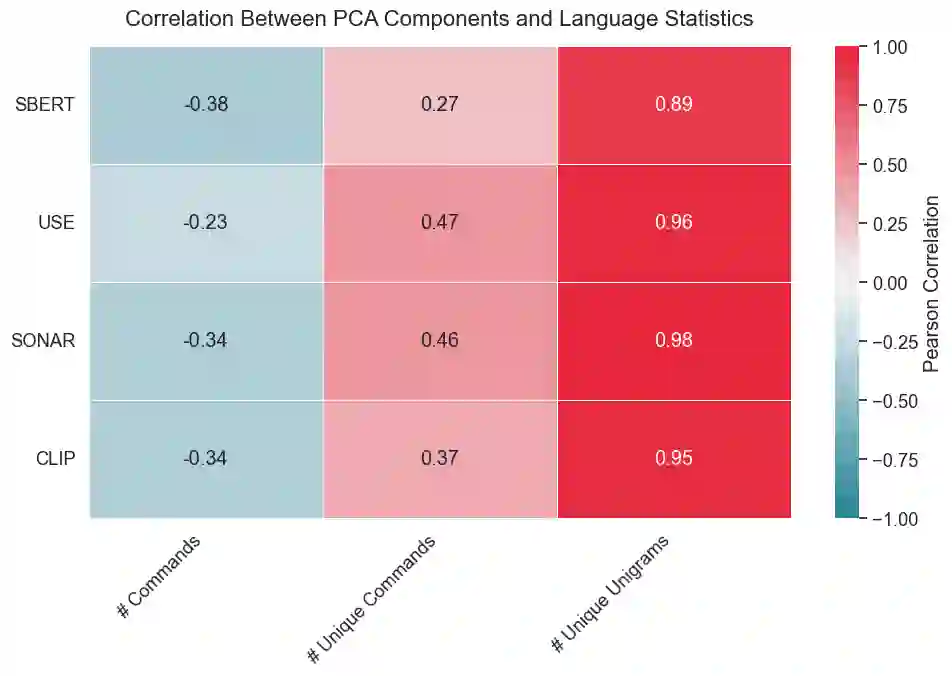
Language plays a critical role in Vision-Language-Action (VLA) models, yet the linguistic characteristics of the datasets used to train and evaluate these systems remain poorly documented. In this work, we present a systematic dataset audit of several widely used VLA corpora, aiming to characterize what kinds of instructions these datasets actually contain and how much linguistic variety they provide. We quantify instruction language along complementary dimensions-including lexical variety, duplication and overlap, semantic similarity, and syntactic complexity. Our analysis shows that many datasets rely on highly repetitive, template-like commands with limited structural variation, yielding a narrow distribution of instruction forms. We position these findings as descriptive documentation of the language signal available in current VLA training and evaluation data, intended to support more detailed dataset reporting, more principled dataset selection, and targeted curation or augmentation strategies that broaden language coverage.
翻译:语言在视觉-语言-动作(VLA)模型中起着关键作用,然而用于训练和评估这些系统的数据集的语言特性仍缺乏充分记录。本研究对多个广泛使用的VLA语料库进行了系统性数据集审计,旨在刻画这些数据集实际包含的指令类型及其提供的语言多样性程度。我们从互补维度对指令语言进行量化分析——包括词汇多样性、重复与重叠度、语义相似性以及句法复杂性。分析表明,许多数据集依赖高度重复、模板化的命令,其结构变化有限,导致指令形式的分布范围狭窄。我们将这些发现定位为对当前VLA训练与评估数据中可用语言信号的描述性记录,旨在支持更细致的数据集报告、更基于原则的数据集选择,以及通过针对性整理或增强策略来拓宽语言覆盖范围。