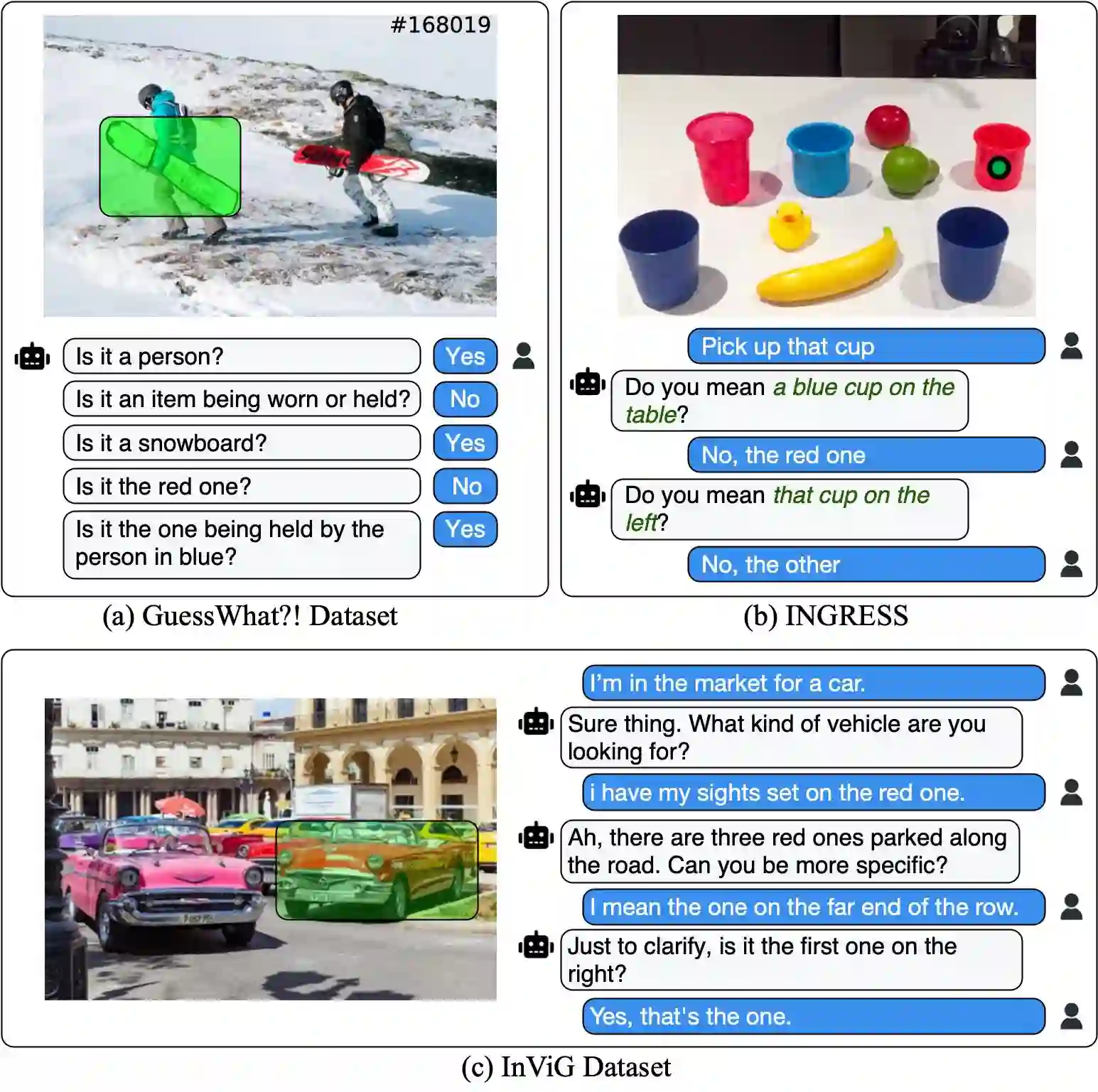
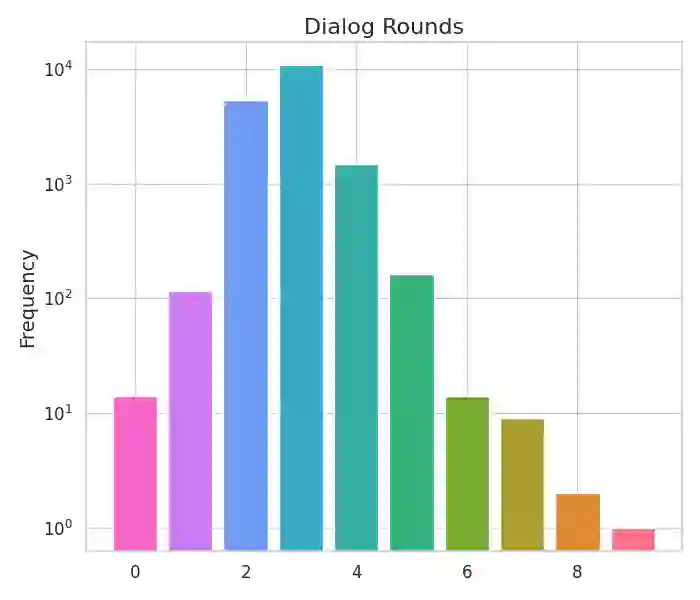
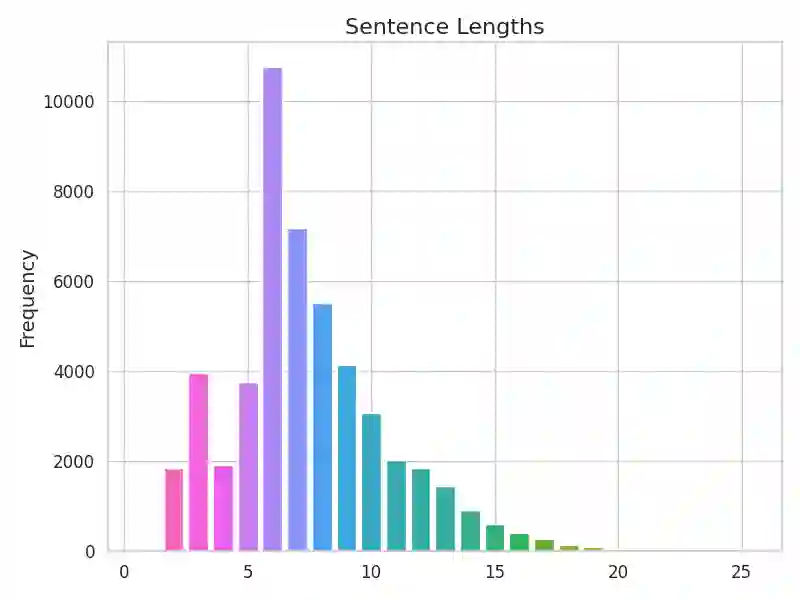
Ambiguity is ubiquitous in human communication. Previous approaches in Human-Robot Interaction (HRI) have often relied on predefined interaction templates, leading to reduced performance in realistic and open-ended scenarios. To address these issues, we present a large-scale dataset, \invig, for interactive visual grounding under language ambiguity. Our dataset comprises over 520K images accompanied by open-ended goal-oriented disambiguation dialogues, encompassing millions of object instances and corresponding question-answer pairs. Leveraging the \invig dataset, we conduct extensive studies and propose a set of baseline solutions for end-to-end interactive visual disambiguation and grounding, achieving a 45.6\% success rate during validation. To the best of our knowledge, the \invig dataset is the first large-scale dataset for resolving open-ended interactive visual grounding, presenting a practical yet highly challenging benchmark for ambiguity-aware HRI. Codes and datasets are available at: \href{https://openivg.github.io}{https://openivg.github.io}.
翻译:歧义是人类交流中的普遍现象。先前的人机交互方法常依赖预定义的交互模板,导致在真实且开放场景中性能下降。为解决这些问题,我们提出大规模数据集InViG,用于语言歧义下的交互式视觉定位。该数据集包含超过52万张图像,配有开放式目标导向消歧对话,涵盖数百万个对象实例及对应的问答对。基于InViG数据集,我们开展了深入研究,并提出一套端到端交互式视觉消歧与定位的基线方案,在验证中达到45.6%的成功率。据我们所知,InViG是首个用于解决开放式交互式视觉定位的大规模数据集,为歧义感知型人机交互提供了实用且极具挑战性的基准。代码与数据集见:https://openivg.github.io。