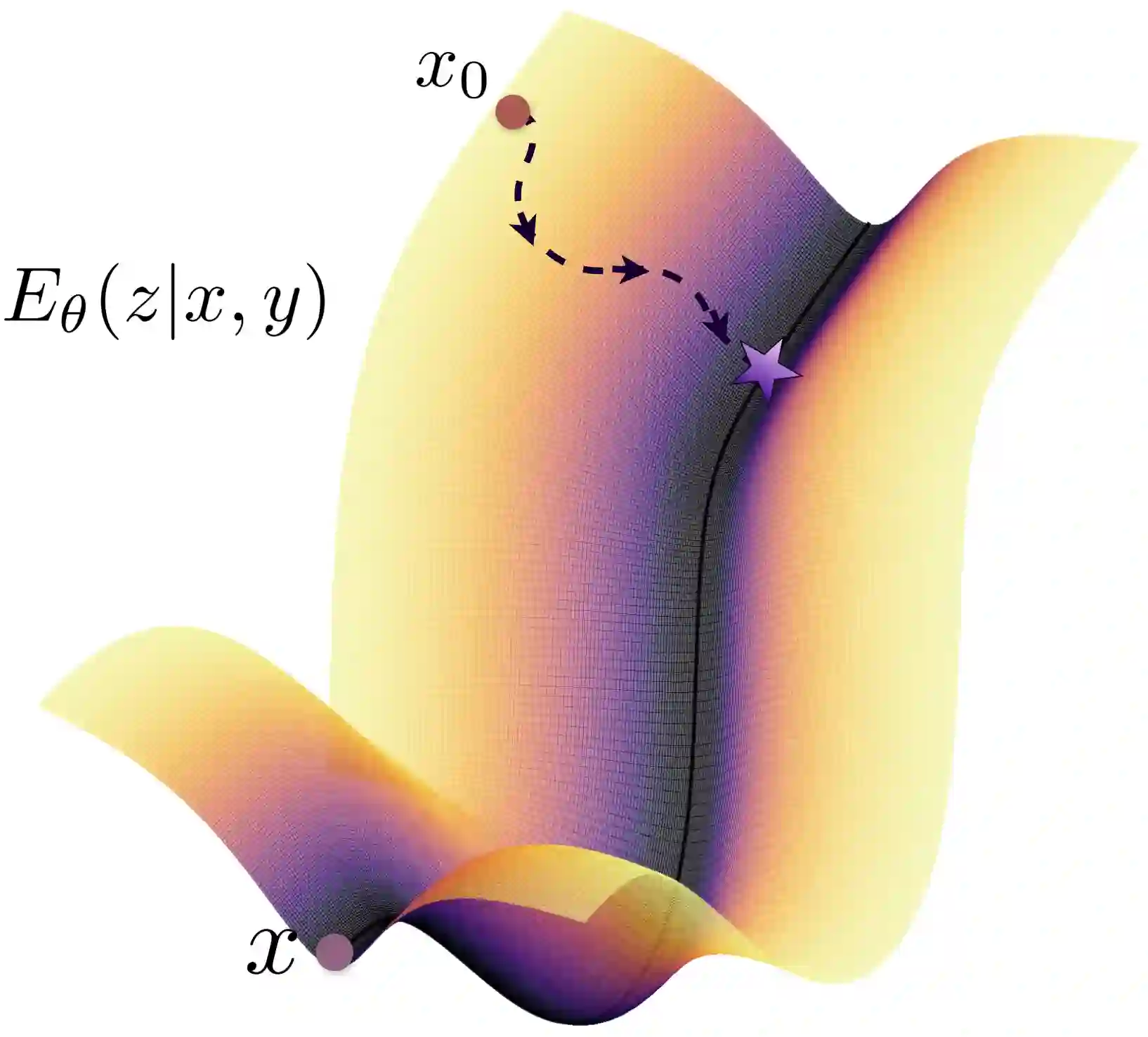
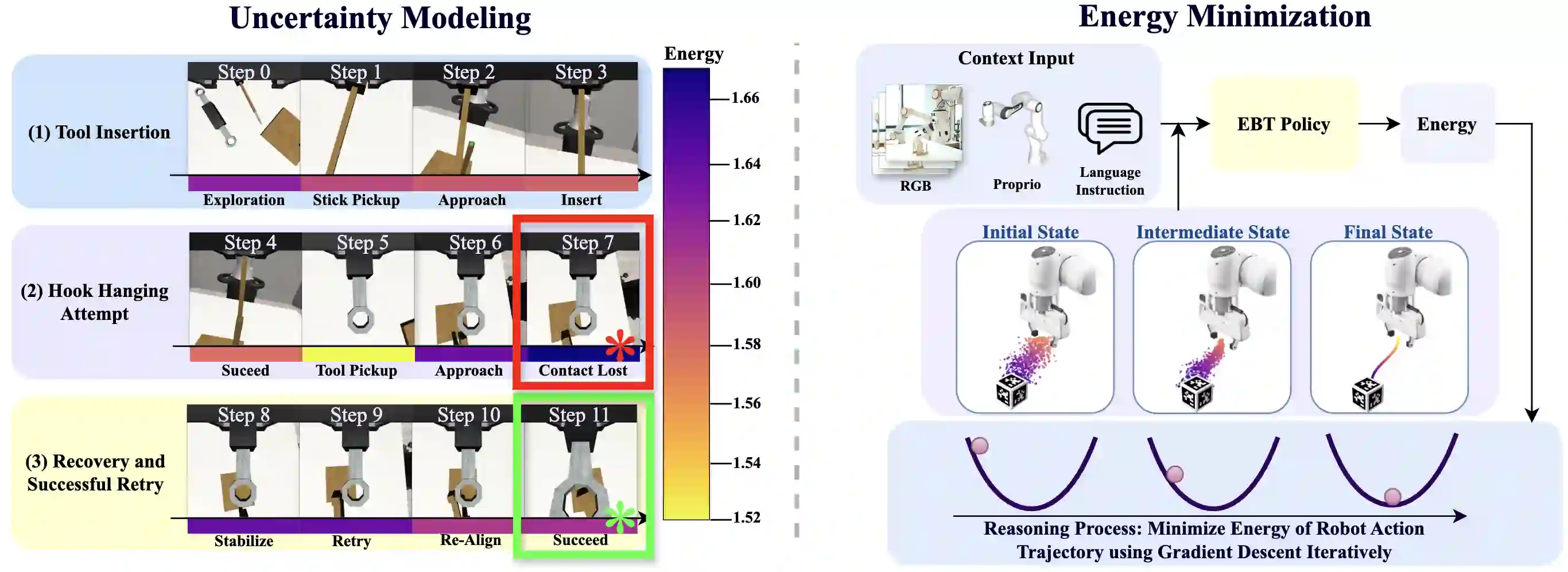
Implicit policies parameterized by generative models, such as Diffusion Policy, have become the standard for policy learning and Vision-Language-Action (VLA) models in robotics. However, these approaches often suffer from high computational cost, exposure bias, and unstable inference dynamics, which lead to divergence under distribution shifts. Energy-Based Models (EBMs) address these issues by learning energy landscapes end-to-end and modeling equilibrium dynamics, offering improved robustness and reduced exposure bias. Yet, policies parameterized by EBMs have historically struggled to scale effectively. Recent work on Energy-Based Transformers (EBTs) demonstrates the scalability of EBMs to high-dimensional spaces, but their potential for solving core challenges in physically embodied models remains underexplored. We introduce a new energy-based architecture, EBT-Policy, that solves core issues in robotic and real-world settings. Across simulated and real-world tasks, EBT-Policy consistently outperforms diffusion-based policies, while requiring less training and inference computation. Remarkably, on some tasks it converges within just two inference steps, a 50x reduction compared to Diffusion Policy's 100. Moreover, EBT-Policy exhibits emergent capabilities not seen in prior models, such as zero-shot recovery from failed action sequences using only behavior cloning and without explicit retry training. By leveraging its scalar energy for uncertainty-aware inference and dynamic compute allocation, EBT-Policy offers a promising path toward robust, generalizable robot behavior under distribution shifts.
翻译:由生成模型参数化的隐式策略,如扩散策略(Diffusion Policy),已成为机器人学中策略学习和视觉-语言-动作(VLA)模型的标准方法。然而,这些方法通常存在计算成本高、暴露偏差以及推理动态不稳定等问题,导致在分布偏移下出现发散。基于能量的模型(EBMs)通过端到端学习能量景观并建模平衡动态,解决了这些问题,提供了更强的鲁棒性和更低的暴露偏差。然而,由EBMs参数化的策略在历史上一直难以有效扩展。近期关于基于能量的Transformer(EBTs)的研究证明了EBMs在高维空间中的可扩展性,但其在解决物理实体模型核心挑战方面的潜力仍未得到充分探索。我们提出了一种新的基于能量的架构——EBT-Policy,它解决了机器人和现实世界设置中的核心问题。在模拟和现实世界任务中,EBT-Policy始终优于基于扩散的策略,同时需要更少的训练和推理计算。值得注意的是,在某些任务中,它仅需两次推理步骤即可收敛,相比扩散策略的100步减少了50倍。此外,EBT-Policy展现出先前模型中未见的涌现能力,例如仅通过行为克隆、无需显式重试训练即可实现失败动作序列的零样本恢复。通过利用其标量能量进行不确定性感知推理和动态计算分配,EBT-Policy为在分布偏移下实现鲁棒、可泛化的机器人行为提供了一条有前景的路径。