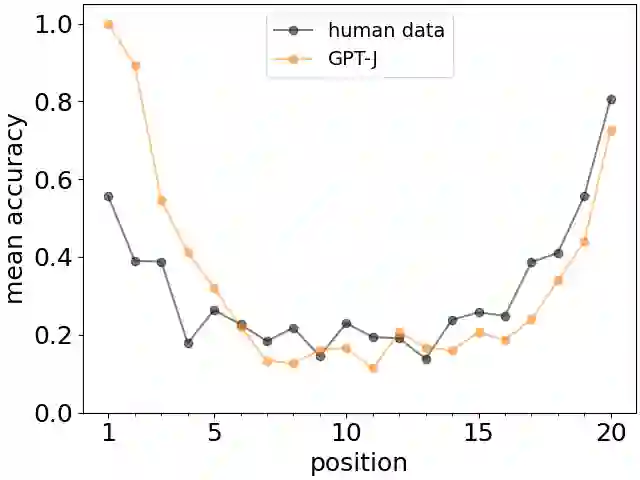
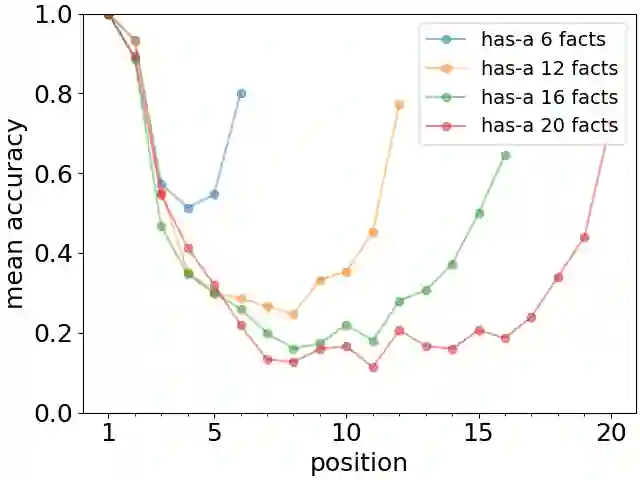
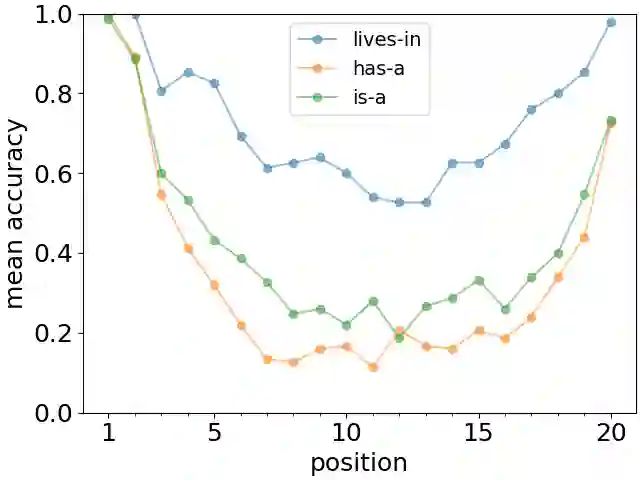
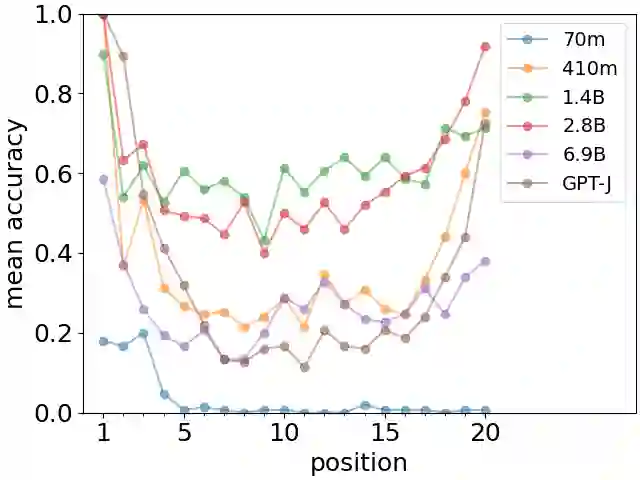
Large Language Models (LLMs) are huge artificial neural networks which primarily serve to generate text, but also provide a very sophisticated probabilistic model of language use. Since generating a semantically consistent text requires a form of effective memory, we investigate the memory properties of LLMs and find surprising similarities with key characteristics of human memory. We argue that the human-like memory properties of the Large Language Model do not follow automatically from the LLM architecture but are rather learned from the statistics of the training textual data. These results strongly suggest that the biological features of human memory leave an imprint on the way that we structure our textual narratives.
翻译:大语言模型(LLMs)是庞大的人工神经网络,主要用于生成文本,同时也提供了极为精密的语言使用概率模型。由于生成语义连贯的文本需要有效记忆机制,我们研究了LLMs的记忆特性,并发现其与人类记忆的关键特征存在惊人相似性。我们论证认为,大语言模型所具备的类人记忆特性并非自动源于其架构设计,而是从训练文本数据的统计特征中习得的。这些结果强有力地表明,人类记忆的生物学特征在我们构建文本叙事的组织方式中留下了深刻印记。