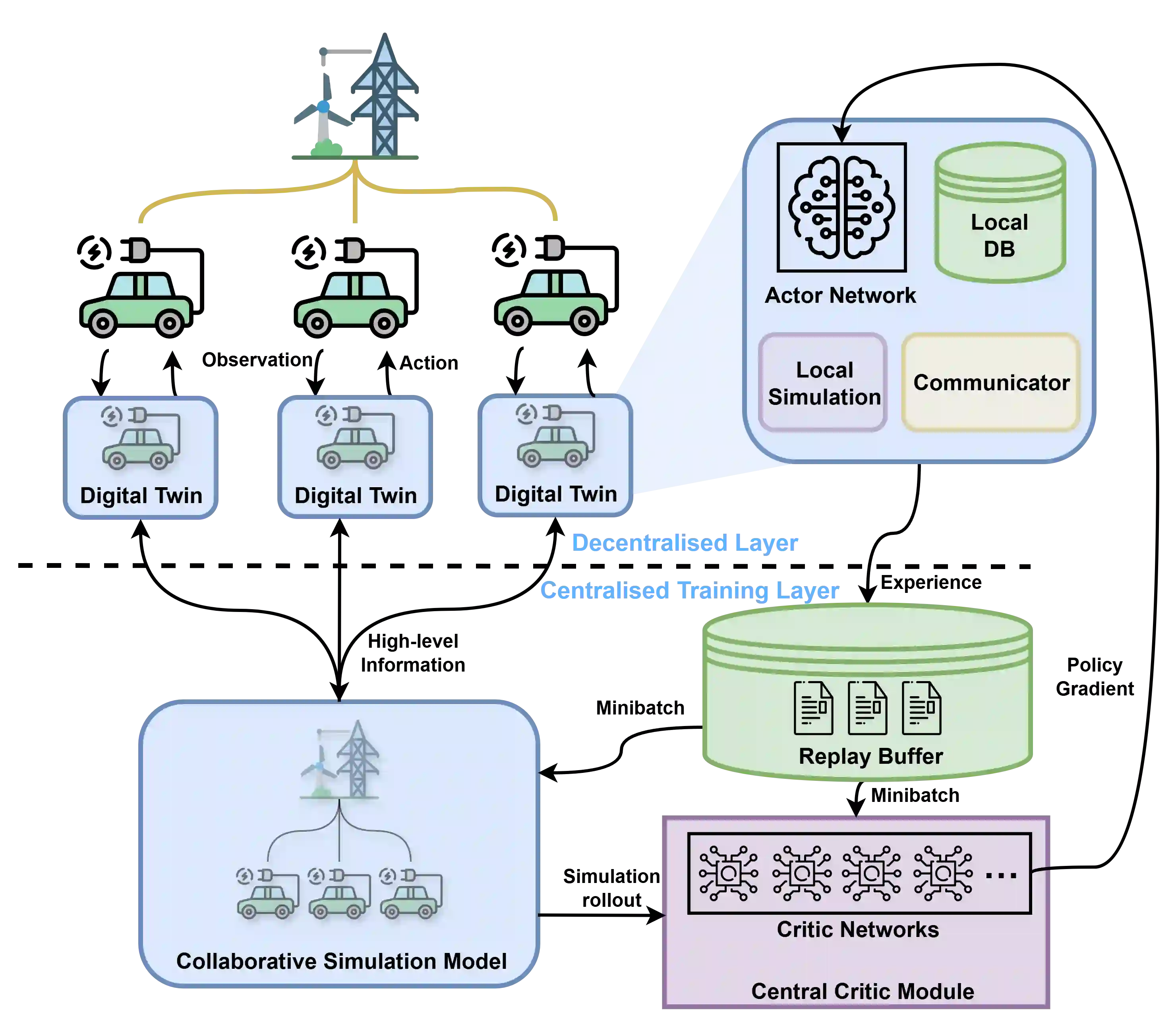
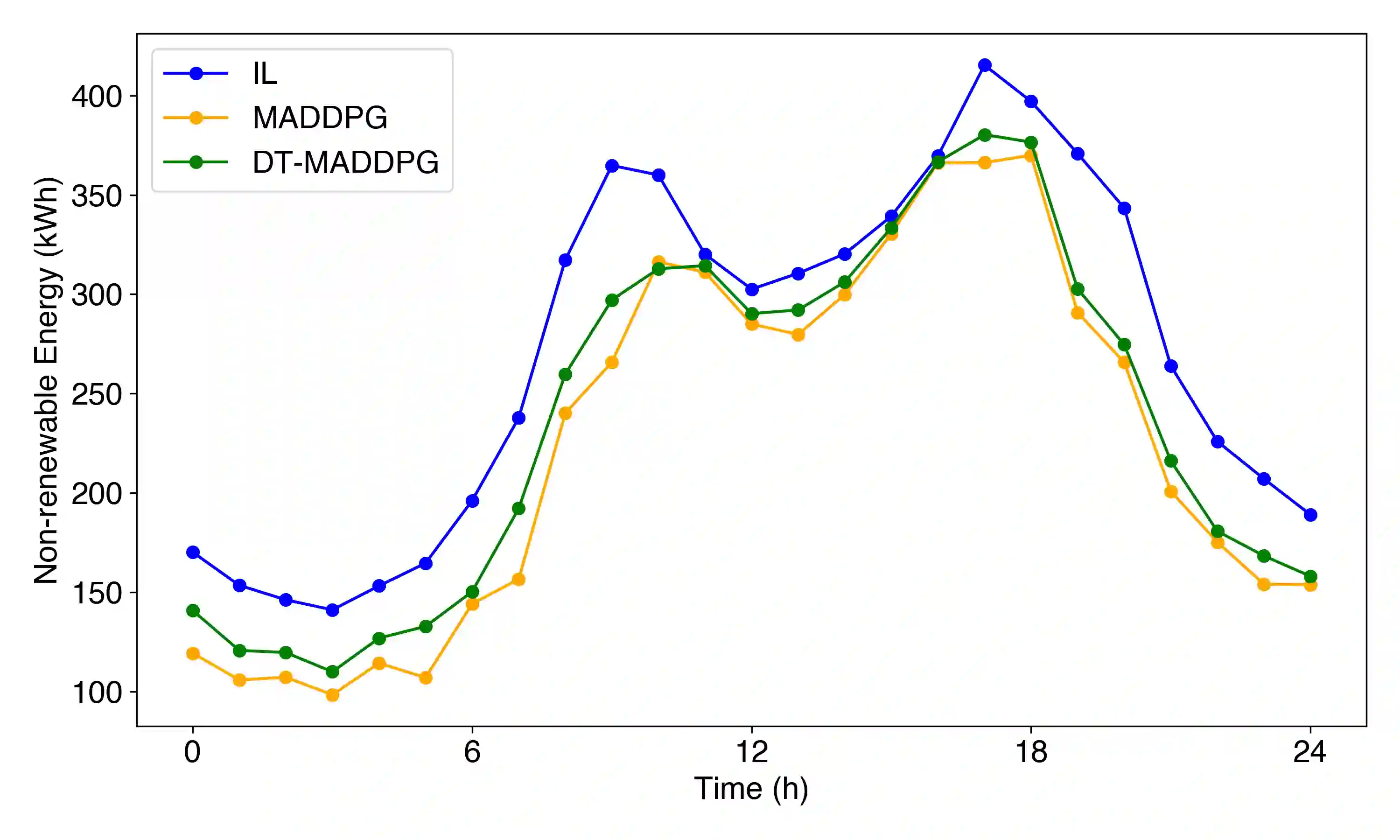
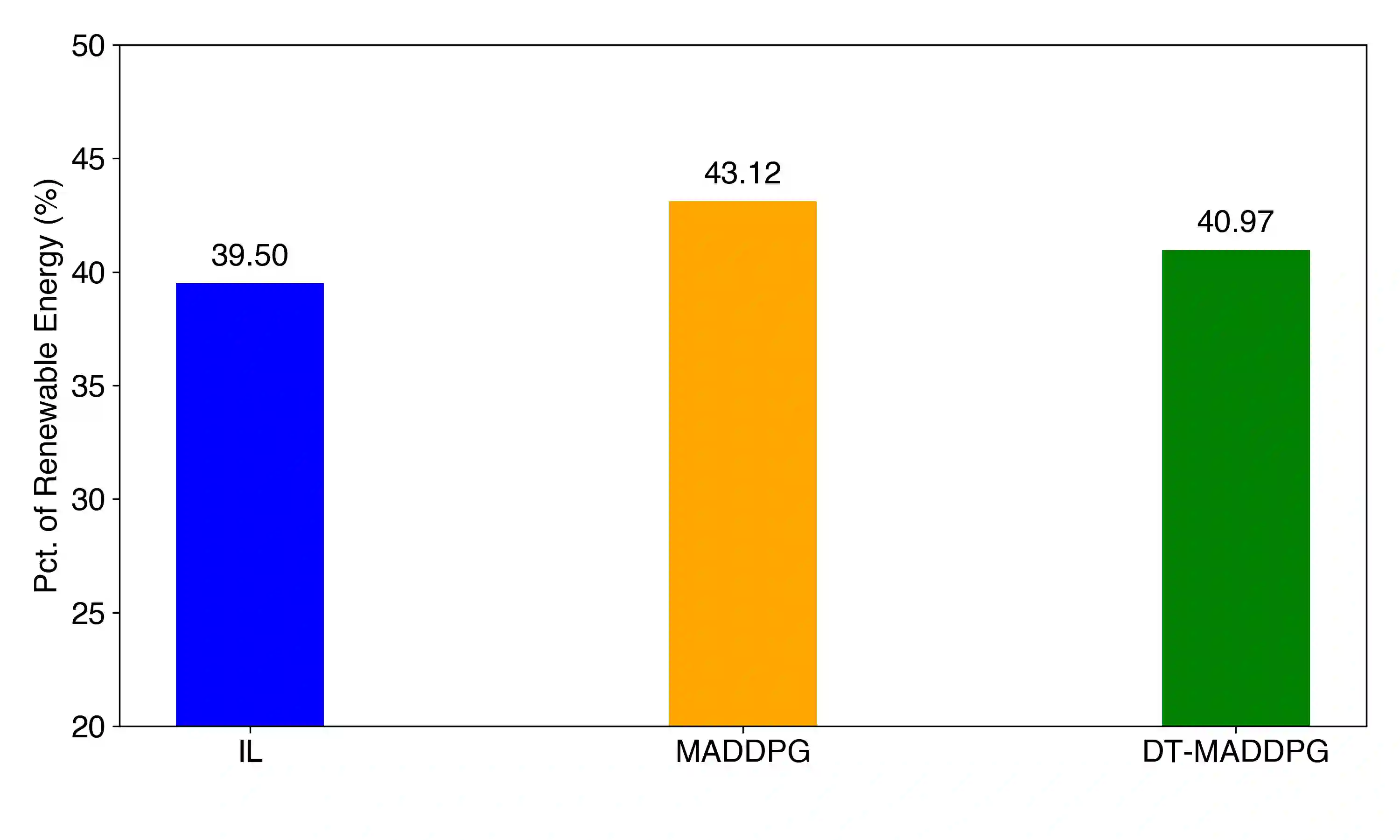
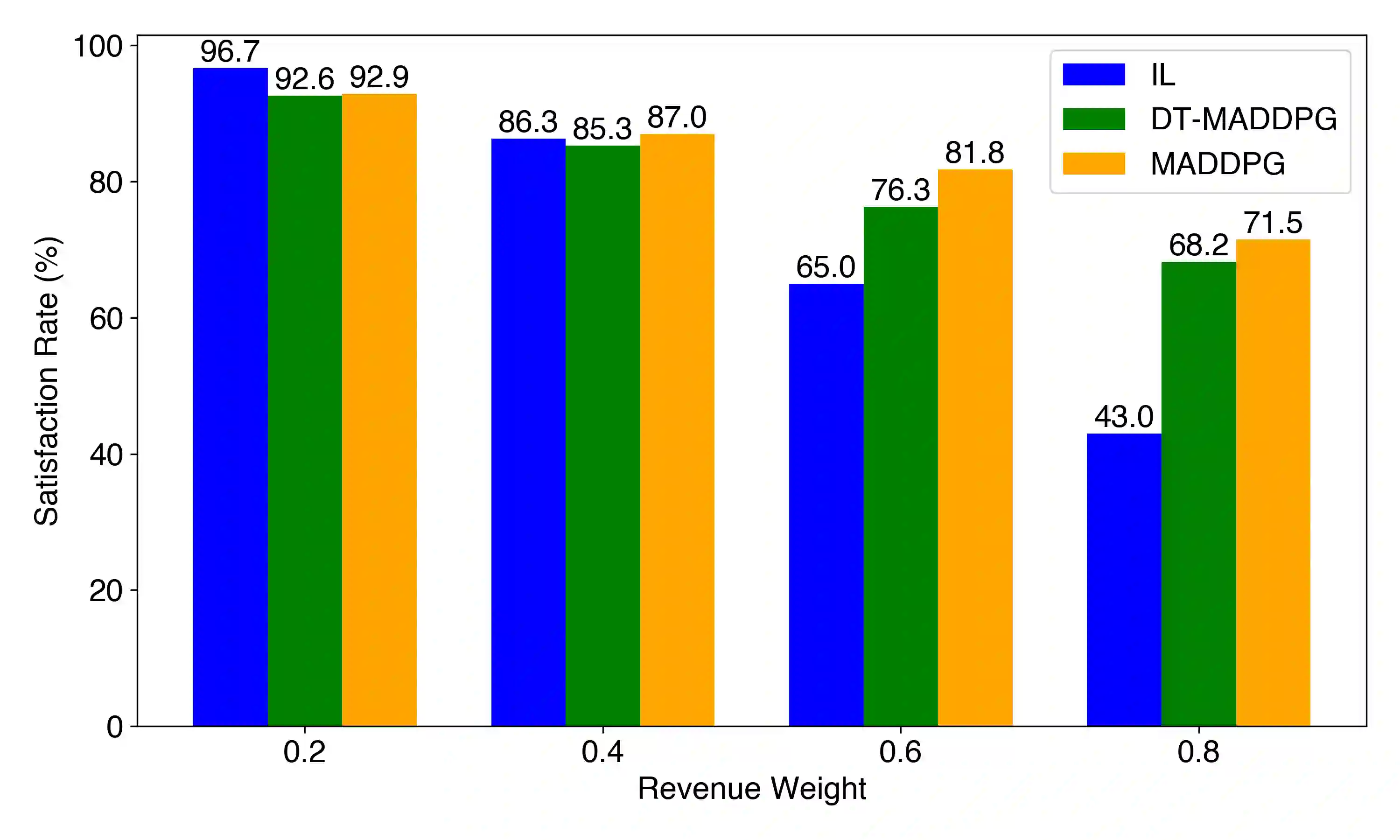
The coordination of large-scale, decentralised systems, such as a fleet of Electric Vehicles (EVs) in a Vehicle-to-Grid (V2G) network, presents a significant challenge for modern control systems. While collaborative Digital Twins have been proposed as a solution to manage such systems without compromising the privacy of individual agents, deriving globally optimal control policies from the high-level information they share remains an open problem. This paper introduces Digital Twin Assisted Multi-Agent Deep Deterministic Policy Gradient (DT-MADDPG) algorithm, a novel hybrid architecture that integrates a multi-agent reinforcement learning framework with a collaborative DT network. Our core contribution is a simulation-assisted learning algorithm where the centralised critic is enhanced by a predictive global model that is collaboratively built from the privacy-preserving data shared by individual DTs. This approach removes the need for collecting sensitive raw data at a centralised entity, a requirement of traditional multi-agent learning algorithms. Experimental results in a simulated V2G environment demonstrate that DT-MADDPG can achieve coordination performance comparable to the standard MADDPG algorithm while offering significant advantages in terms of data privacy and architectural decentralisation. This work presents a practical and robust framework for deploying intelligent, learning-based coordination in complex, real-world cyber-physical systems.
翻译:大规模分散式系统(如车联网(V2G)中的电动汽车车队)的协调对现代控制系统构成了重大挑战。尽管协作式数字孪生已被提出作为管理此类系统且不损害个体智能体隐私的解决方案,但从其共享的高层信息中推导全局最优控制策略仍是一个开放性问题。本文提出了数字孪生辅助多智能体深度确定性策略梯度(DT-MADDPG)算法,这是一种将多智能体强化学习框架与协作式数字孪生网络相结合的新型混合架构。我们的核心贡献是一种仿真辅助学习算法,其中集中式评论器通过一个预测性全局模型得到增强,该模型由各个数字孪生共享的隐私保护数据协作构建。这种方法消除了在集中实体处收集敏感原始数据的需求,而这是传统多智能体学习算法的必要条件。在模拟V2G环境中的实验结果表明,DT-MADDPG能够实现与标准MADDPG算法相当的协调性能,同时在数据隐私和架构去中心化方面具有显著优势。这项工作为在复杂的现实世界信息物理系统中部署基于学习的智能协调提供了一个实用且稳健的框架。