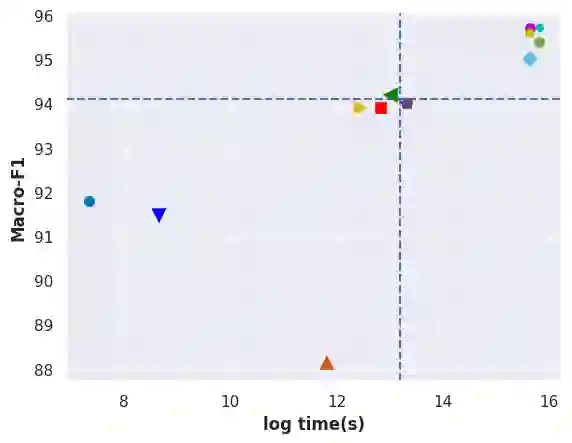
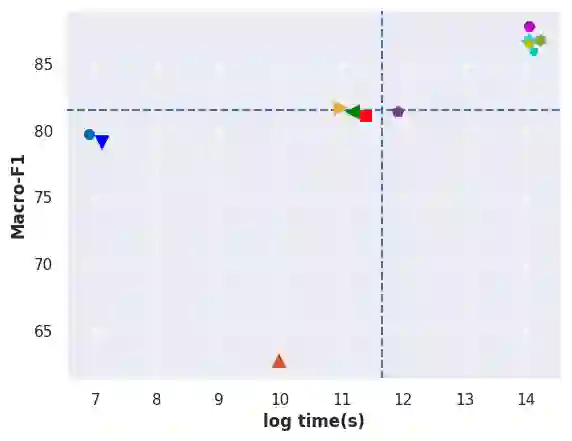
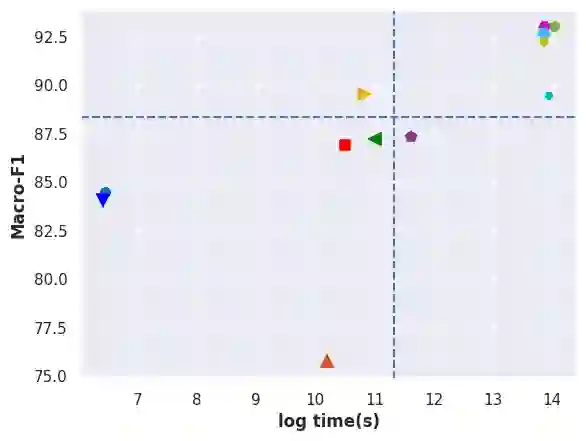
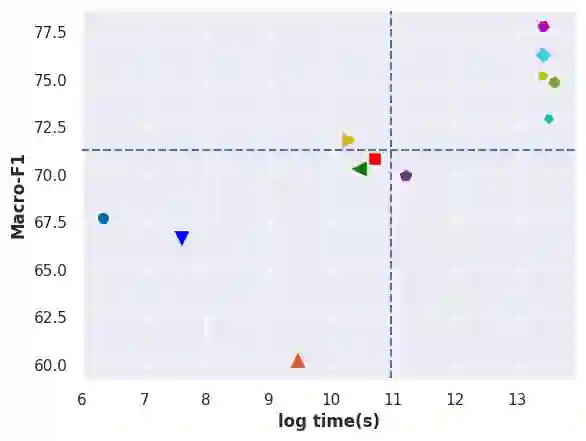
Automatic text classification (ATC) has experienced remarkable advancements in the past decade, best exemplified by recent small and large language models (SLMs and LLMs), leveraged by Transformer architectures. Despite recent effectiveness improvements, a comprehensive cost-benefit analysis investigating whether the effectiveness gains of these recent approaches compensate their much higher costs when compared to more traditional text classification approaches such as SVMs and Logistic Regression is still missing in the literature. In this context, this work's main contributions are twofold: (i) we provide a scientifically sound comparative analysis of the cost-benefit of twelve traditional and recent ATC solutions including five open LLMs, and (ii) a large benchmark comprising {22 datasets}, including sentiment analysis and topic classification, with their (train-validation-test) partitions based on folded cross-validation procedures, along with documentation, and code. The release of code, data, and documentation enables the community to replicate experiments and advance the field in a more scientifically sound manner. Our comparative experimental results indicate that LLMs outperform traditional approaches (up to 26%-7.1% on average) and SLMs (up to 4.9%-1.9% on average) in terms of effectiveness. However, LLMs incur significantly higher computational costs due to fine-tuning, being, on average 590x and 8.5x slower than traditional methods and SLMs, respectively. Results suggests the following recommendations: (1) LLMs for applications that require the best possible effectiveness and can afford the costs; (2) traditional methods such as Logistic Regression and SVM for resource-limited applications or those that cannot afford the cost of tuning large LLMs; and (3) SLMs like Roberta for near-optimal effectiveness-efficiency trade-off.
翻译:自动文本分类在过去十年中取得了显著进展,以基于Transformer架构的小型与大型语言模型为代表。尽管近期方法在效能上有所提升,但学界仍缺乏全面的成本效益分析,以评估这些新方法相较于支持向量机、逻辑回归等传统文本分类方法所获得的效能提升是否足以弥补其显著更高的成本。为此,本研究作出两方面主要贡献:(一)对十二种传统与新兴自动文本分类方案(包括五种开源大型语言模型)进行了科学严谨的成本效益对比分析;(二)构建了一个包含22个数据集的大规模基准测试集,涵盖情感分析与主题分类任务,所有数据集均基于折叠交叉验证流程划分训练集-验证集-测试集,并配套提供完整文档与代码。代码、数据及文档的发布将使研究社区能够复现实验,并以更科学的方式推动领域发展。对比实验结果表明,大型语言模型在效能上优于传统方法(平均提升达26%-7.1%)和中小型语言模型(平均提升达4.9%-1.9%)。然而,由于微调过程带来的计算负担,大型语言模型的计算成本显著更高,其平均运行速度分别比传统方法和中小型语言模型慢590倍和8.5倍。基于实验结果,我们提出以下建议:(1)对效能要求极高且能承担相应成本的应用场景,推荐采用大型语言模型;(2)资源受限或无法承担大型语言模型调优成本的应用场景,建议使用逻辑回归、支持向量机等传统方法;(3)若需在效能与效率间取得接近最优的平衡,可选用Roberta等中小型语言模型。