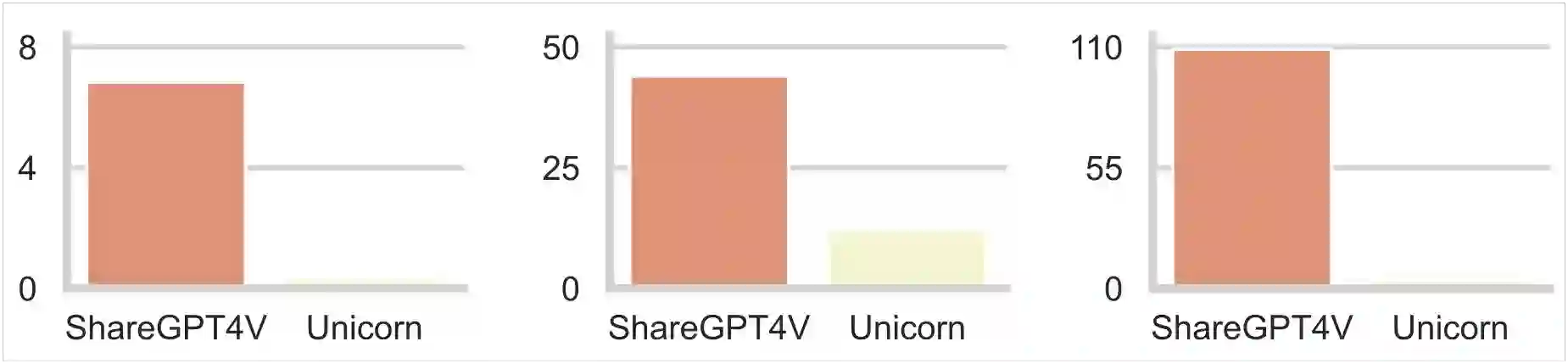
Training vision-language models (VLMs) typically requires large-scale, high-quality image-text pairs, but collecting or synthesizing such data is costly. In contrast, text data is abundant and inexpensive, prompting the question: can high-quality multimodal training data be synthesized purely from text? To tackle this, we propose a cross-integrated three-stage multimodal data synthesis framework, which generates two datasets: Unicorn-1.2M and Unicorn-471K-Instruction. In Stage 1: Diverse Caption Data Synthesis, we construct 1.2M semantically diverse high-quality captions by expanding sparse caption seeds using large language models (LLMs). In Stage 2: Instruction-Tuning Data Generation, we further process 471K captions into multi-turn instruction-tuning tasks to support complex reasoning. Finally, in Stage 3: Modality Representation Transfer, these textual captions representations are transformed into visual representations, resulting in diverse synthetic image representations. This three-stage process enables us to construct Unicorn-1.2M for pretraining and Unicorn-471K-Instruction for instruction-tuning, without relying on real images. By eliminating the dependency on real images while maintaining data quality and diversity, our framework offers a cost-effective and scalable solution for VLMs training. Code is available at https://github.com/Yu-xm/Unicorn.git.
翻译:训练视觉语言模型通常需要大规模高质量的图像-文本对,但收集或合成此类数据成本高昂。相比之下,文本数据丰富且廉价,这引发了一个问题:能否仅从文本合成高质量的多模态训练数据?为此,我们提出了一种交叉集成的三阶段多模态数据合成框架,该框架生成两个数据集:Unicorn-1.2M 和 Unicorn-471K-Instruction。在第一阶段:多样化描述数据合成中,我们通过使用大语言模型扩展稀疏描述种子,构建了120万个语义多样化的高质量描述。在第二阶段:指令调优数据生成中,我们将47.1万个描述进一步处理为多轮指令调优任务,以支持复杂推理。最后在第三阶段:模态表示迁移中,这些文本描述表示被转化为视觉表示,从而产生多样化的合成图像表示。通过这三阶段流程,我们能够构建用于预训练的 Unicorn-1.2M 和用于指令调优的 Unicorn-471K-Instruction,且无需依赖真实图像。该框架在消除对真实图像依赖的同时保持了数据质量与多样性,为视觉语言模型训练提供了经济高效且可扩展的解决方案。代码发布于 https://github.com/Yu-xm/Unicorn.git。