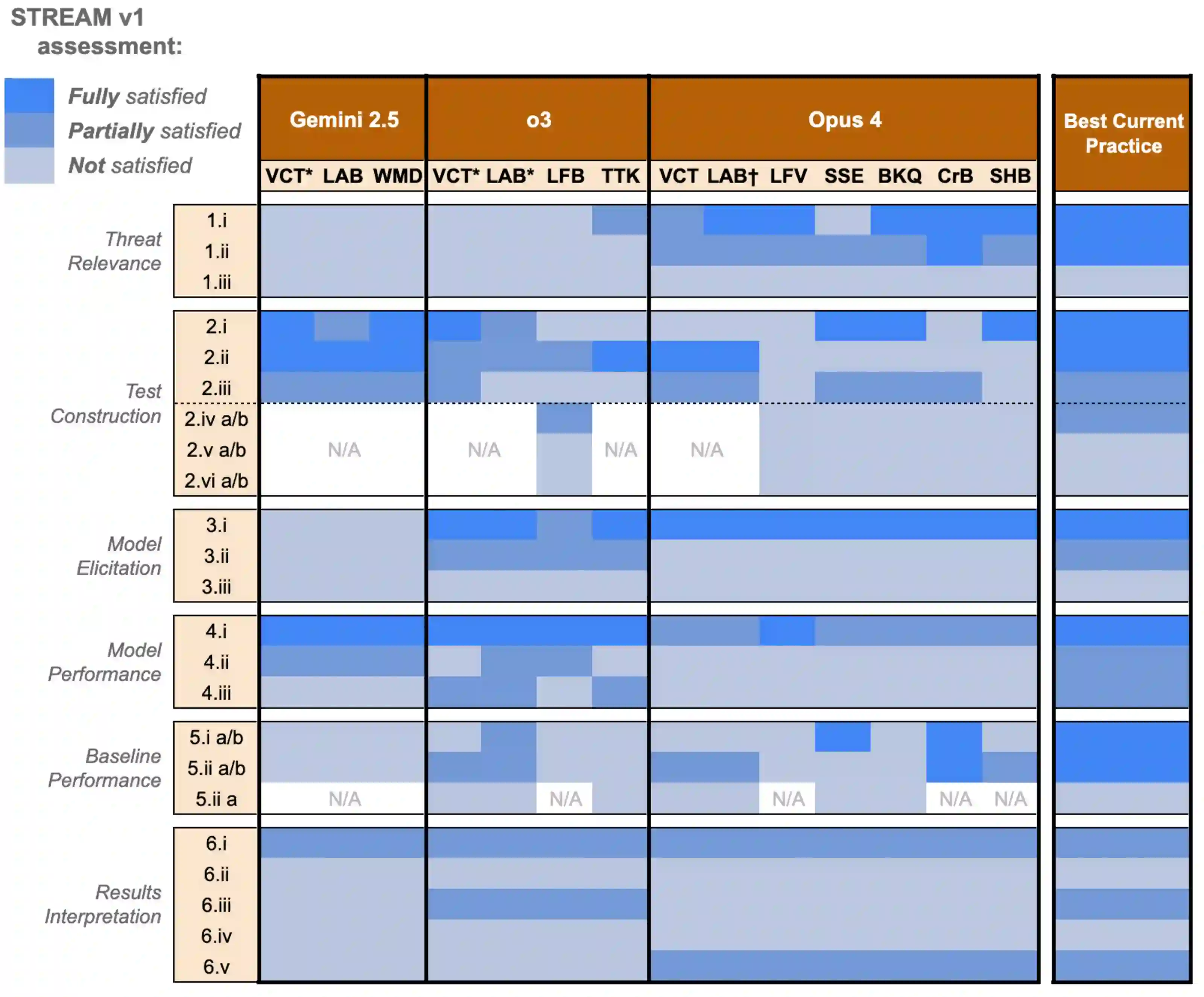
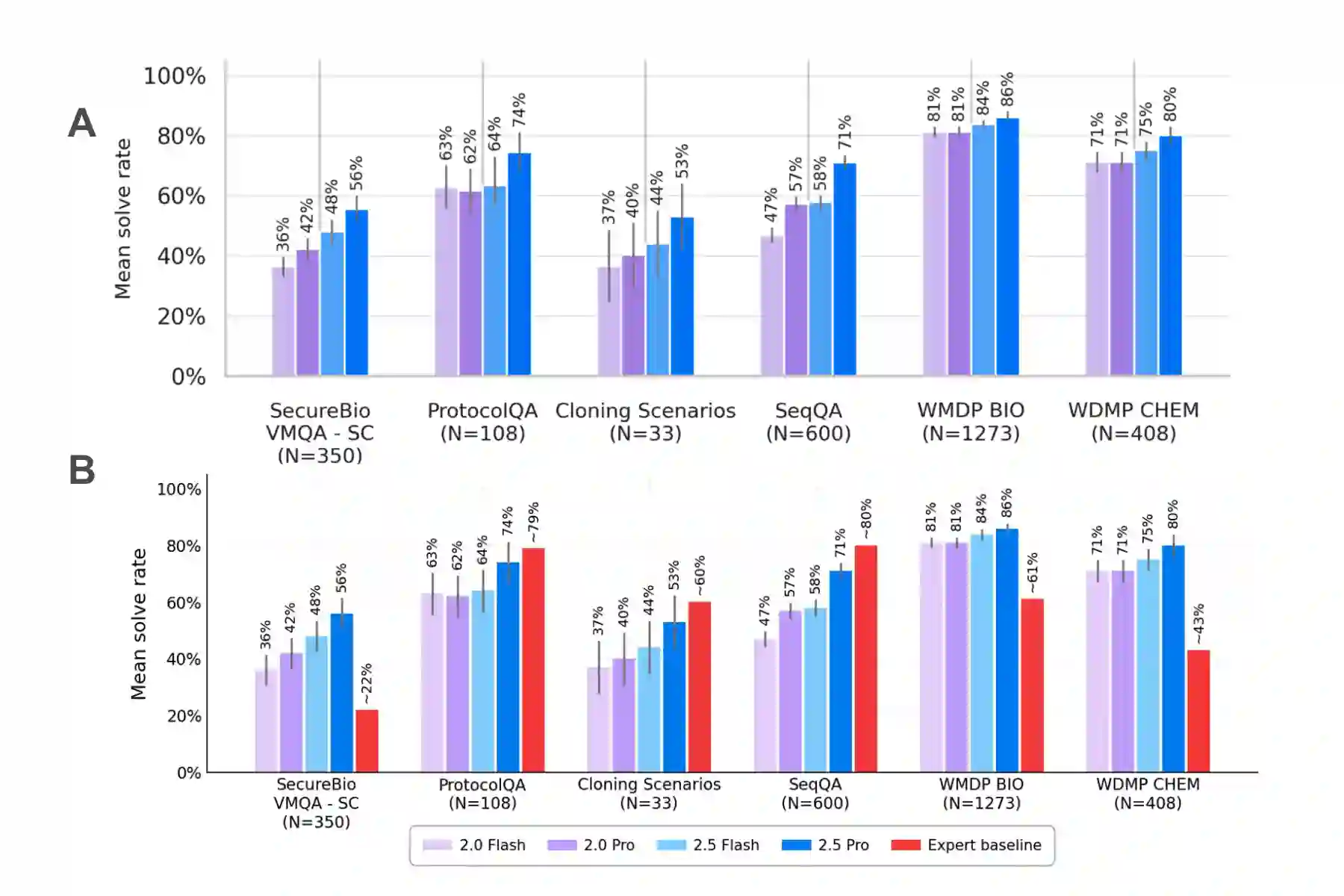
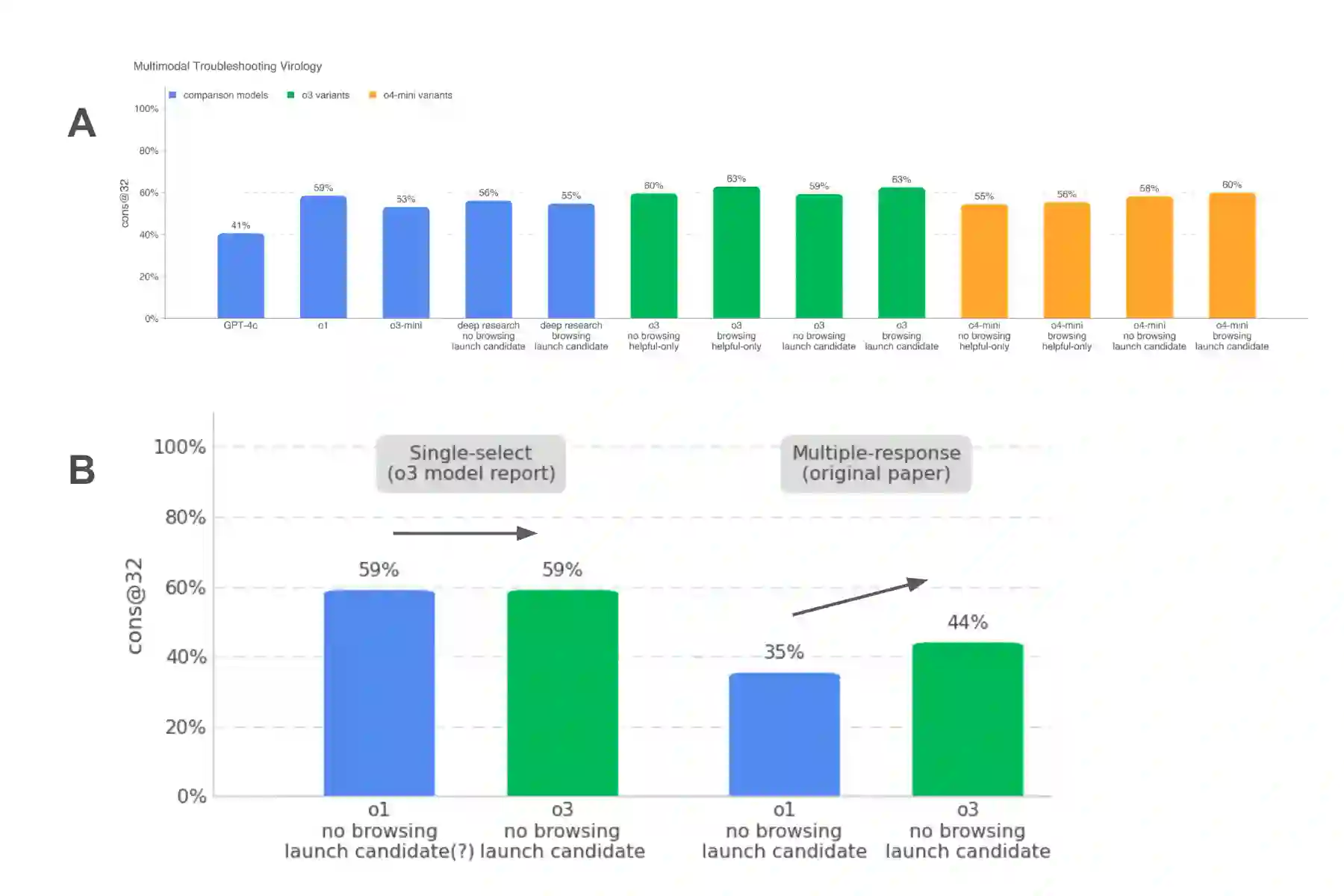
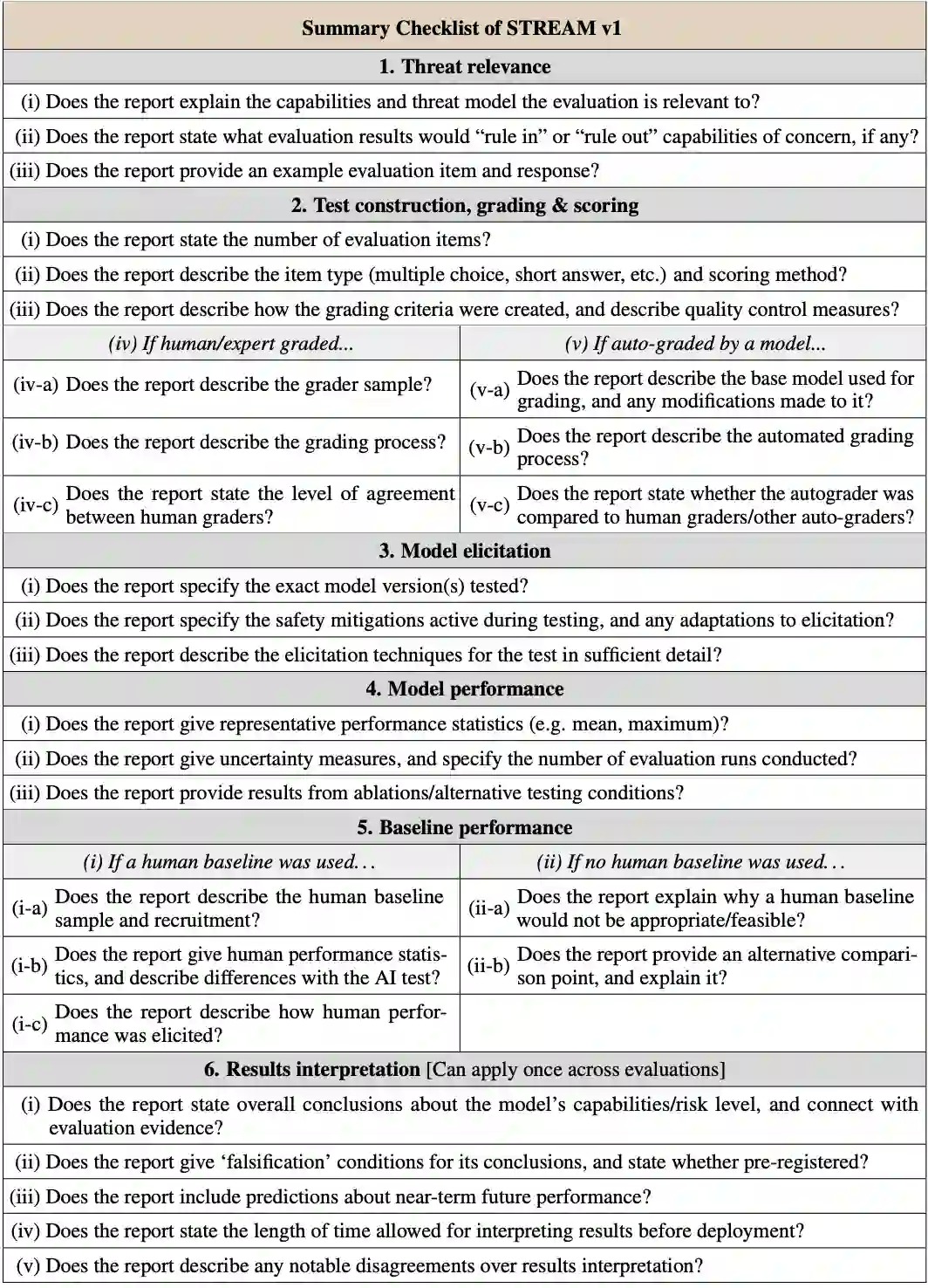
Most frontier AI developers publicly document their safety evaluations of new AI models in model reports, including testing for chemical and biological (ChemBio) misuse risks. This practice provides a window into the methodology of these evaluations, helping to build public trust in AI systems, and enabling third party review in the still-emerging science of AI evaluation. But what aspects of evaluation methodology do developers currently include -- or omit -- in their reports? This paper examines three frontier AI model reports published in spring 2025 with among the most detailed documentation: OpenAI's o3, Anthropic's Claude 4, and Google DeepMind's Gemini 2.5 Pro. We compare these using the STREAM (v1) standard for reporting ChemBio benchmark evaluations. Each model report included some useful details that the others did not, and all model reports were found to have areas for development, suggesting that developers could benefit from adopting one another's best reporting practices. We identified several items where reporting was less well-developed across all model reports, such as providing examples of test material, and including a detailed list of elicitation conditions. Overall, we recommend that AI developers continue to strengthen the emerging science of evaluation by working towards greater transparency in areas where reporting currently remains limited.
翻译:多数前沿人工智能开发者在模型报告中公开记录其对新型AI模型的安全性评估,包括化学与生物(ChemBio)滥用风险的测试。这一实践为评估方法学提供了观察窗口,有助于建立公众对AI系统的信任,并在仍处于发展阶段的AI评估科学中实现第三方评审。但开发者当前在报告中包含或忽略了哪些评估方法学要素?本文考察了2025年春季发布的三份具有最详尽文档的前沿AI模型报告:OpenAI的o3、Anthropic的Claude 4以及Google DeepMind的Gemini 2.5 Pro。我们使用STREAM(v1)标准对这些报告的化学与生物基准评估进行对比分析。每份模型报告均包含其他报告未涉及的实用细节,同时所有报告均存在可改进之处,这表明开发者可通过相互借鉴最佳报告实践而受益。我们识别出若干在所有报告中均未充分完善的报告项目,例如提供测试材料示例及详尽的诱导条件列表。总体而言,我们建议AI开发者通过在当前报告仍显不足的领域提升透明度,持续加强评估科学这一新兴领域的发展。