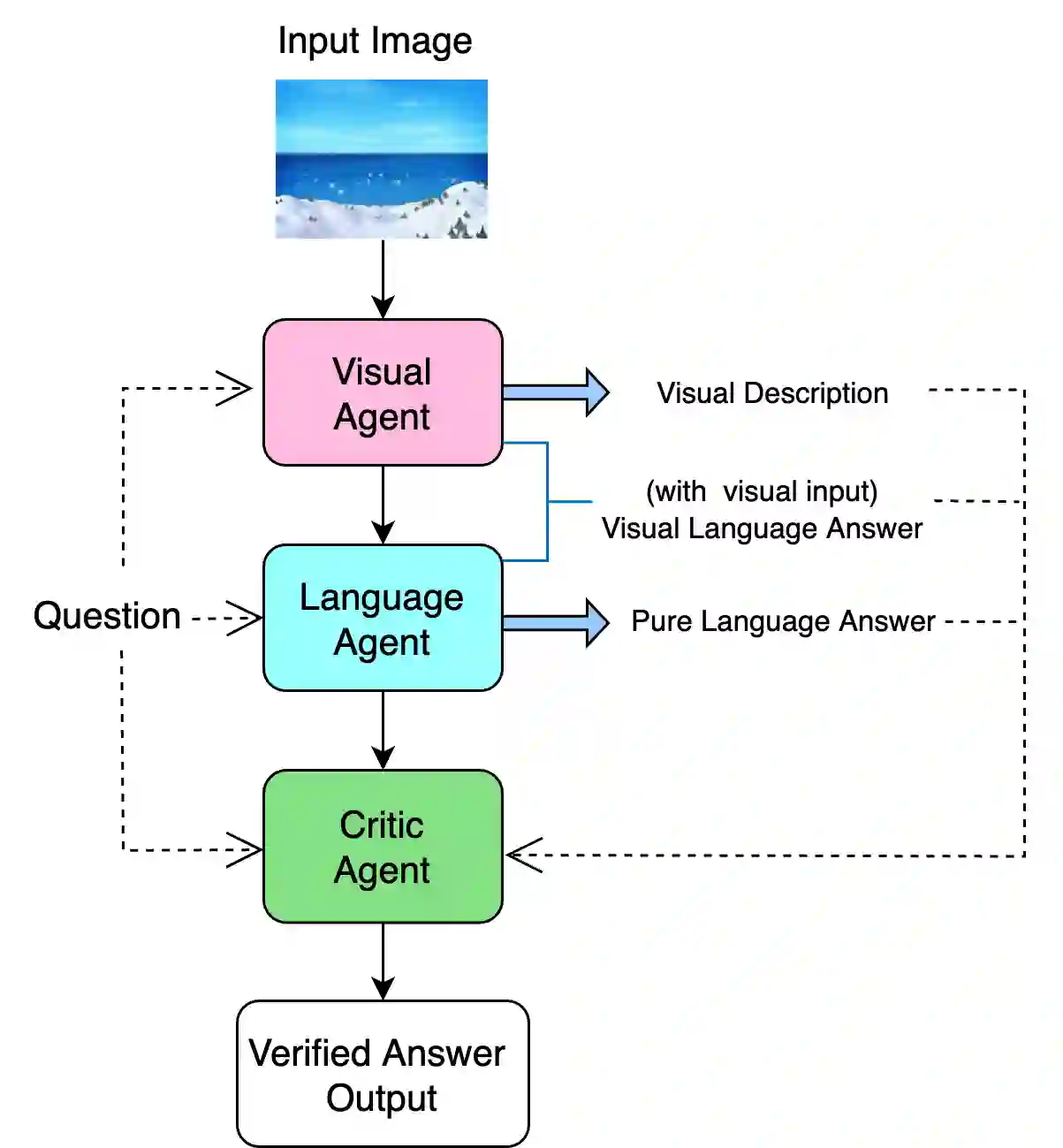
Visual Question Answering (VQA) for stylised cartoon imagery presents challenges, such as interpreting exaggerated visual abstraction and narrative-driven context, which are not adequately addressed by standard large language models (LLMs) trained on natural images. To investigate this issue, a multi-agent LLM framework is introduced, specifically designed for VQA tasks in cartoon imagery. The proposed architecture consists of three specialised agents: visual agent, language agent and critic agent, which work collaboratively to support structured reasoning by integrating visual cues and narrative context. The framework was systematically evaluated on two cartoon-based VQA datasets: Pororo and Simpsons. Experimental results provide a detailed analysis of how each agent contributes to the final prediction, offering a deeper understanding of LLM-based multi-agent behaviour in cartoon VQA and multimodal inference.
翻译:针对风格化卡通图像的视觉问答任务面临诸多挑战,例如需要理解夸张的视觉抽象和叙事驱动的上下文信息,而基于自然图像训练的标准大语言模型难以有效应对这些问题。为探究此问题,本文提出一种专为卡通图像视觉问答任务设计的多智能体大语言模型框架。该架构包含三个专用智能体:视觉智能体、语言智能体和评判智能体,它们通过整合视觉线索与叙事上下文协同工作,以支持结构化推理。该框架在Pororo和Simpsons两个卡通视觉问答数据集上进行了系统评估。实验结果详细分析了每个智能体对最终预测的贡献机制,从而深化了对基于大语言模型的多智能体在卡通视觉问答及多模态推理中行为模式的理解。