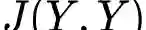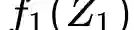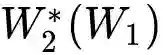The calibration and training of a neural network is a complex and time-consuming procedure that requires significant computational resources to achieve satisfactory results. Key obstacles are a large number of hyperparameters to select and the onset of overfitting in the face of a small amount of data. In this framework, we propose an innovative training strategy for feed-forward architectures - called split-boost - that improves performance and automatically includes a regularizing behaviour without modeling it explicitly. Such a novel approach ultimately allows us to avoid explicitly modeling the regularization term, decreasing the total number of hyperparameters and speeding up the tuning phase. The proposed strategy is tested on a real-world (anonymized) dataset within a benchmark medical insurance design problem.
翻译:神经网络的校准与训练是一个复杂且耗时的过程,需要大量计算资源才能获得满意结果。其主要障碍在于需要选择大量超参数,以及在数据量较少时出现过拟合现象。在此框架下,我们提出了一种针对前馈架构的创新训练策略——称为"分割增强"——该策略在不显式建模正则化行为的情况下,能提升性能并自动包含正则化效果。这种新方法最终使我们能够避免显式建模正则化项,从而减少超参数总数并加速调优阶段。所提出的策略在基准医疗保险设计问题中的真实(匿名化)数据集上进行了测试。