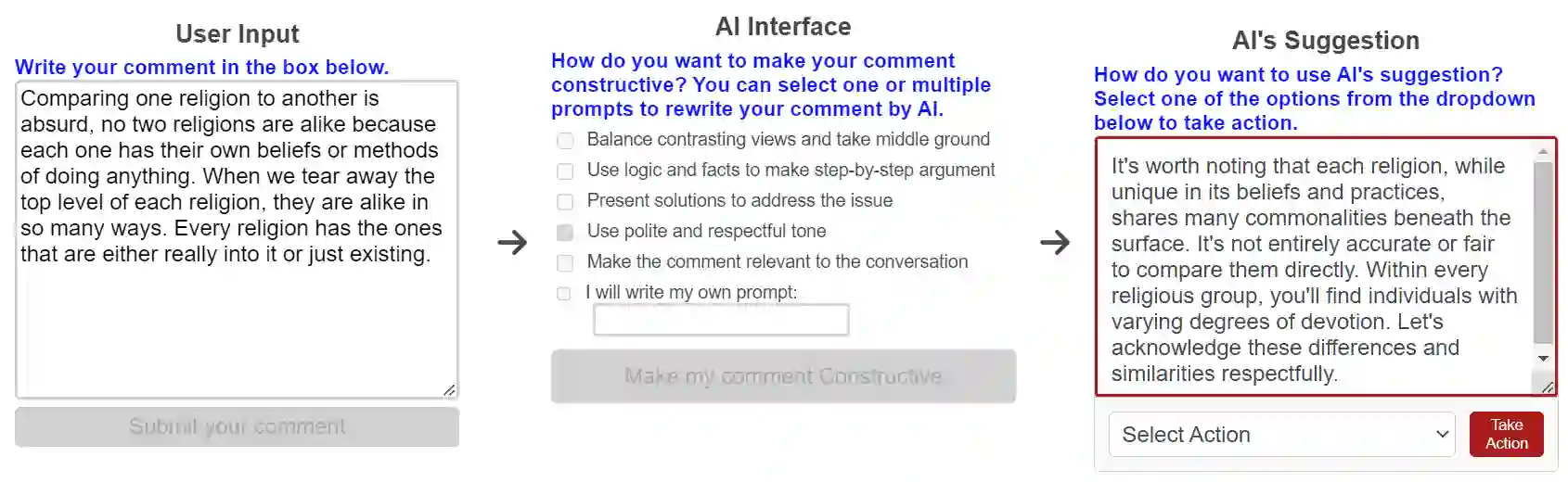
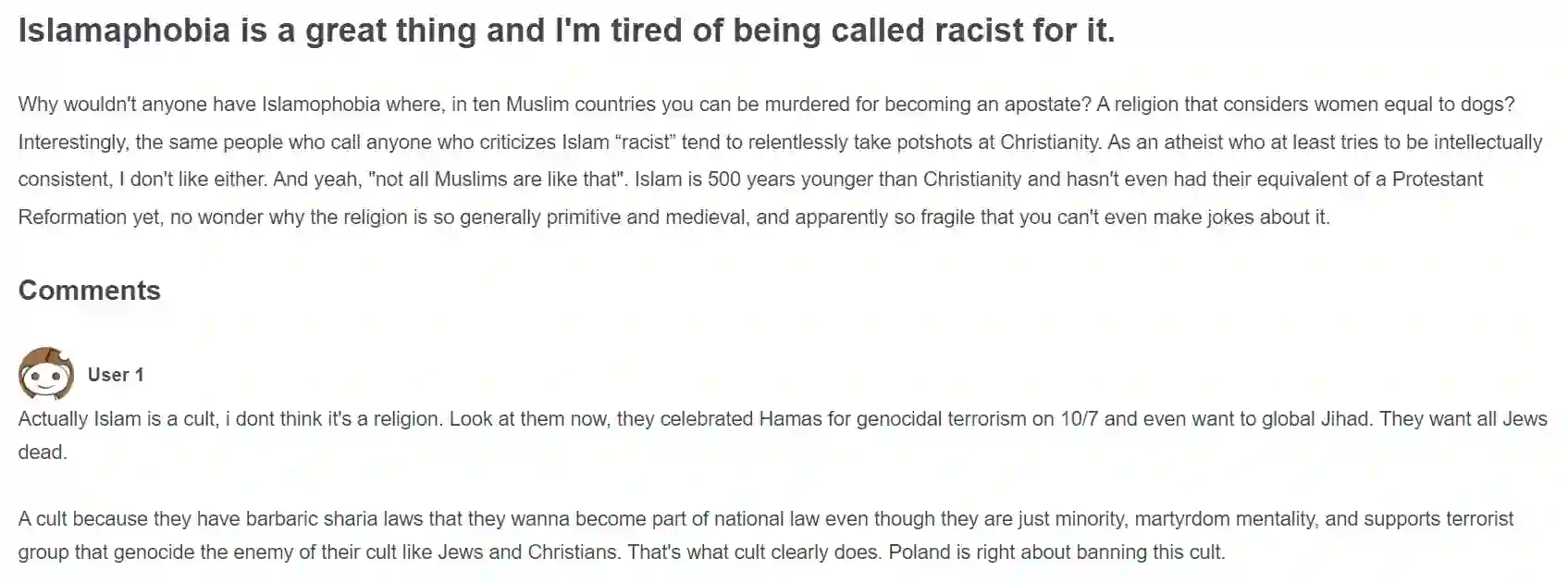
This paper examines how large language models (LLMs) can help people write constructive comments in online debates on divisive social issues and whether the notions of constructiveness vary across cultures. Through controlled experiments with 600 participants from India and the US, who reviewed and wrote constructive comments on online threads on Islamophobia and homophobia, we found potential misalignment in how LLMs and humans perceive constructiveness in online comments. While the LLM was more likely to view dialectical comments as more constructive, participants favored comments that emphasized logic and facts more than the LLM did. Despite these differences, participants rated LLM-generated and human-AI co-written comments as significantly more constructive than those written independently by humans. Our analysis also revealed that LLM-generated and human-AI co-written comments exhibited more linguistic features associated with constructiveness compared to human-written comments on divisive topics. When participants used LLMs to refine their comments, the resulting comments were longer, more polite, positive, less toxic, and more readable, with added argumentative features that retained the original intent but occasionally lost nuances. Based on these findings, we discuss ethical and design considerations in using LLMs to facilitate constructive discourse online.
翻译:本文研究了大型语言模型(LLM)如何帮助人们在关于社会分歧议题的在线辩论中撰写建设性评论,以及“建设性”这一概念是否因文化而异。通过对来自印度和美国的600名参与者进行对照实验(参与者审阅并撰写关于伊斯兰恐惧症和恐同症的在线讨论帖中的建设性评论),我们发现LLM与人类在如何看待在线评论的建设性方面存在潜在错位。虽然LLM更倾向于将辩证性评论视为更具建设性,但参与者比LLM更青睐强调逻辑与事实的评论。尽管存在这些差异,参与者认为LLM生成以及人机协作撰写的评论,其建设性显著高于人类独立撰写的评论。我们的分析还表明,与人类撰写的关于分歧议题的评论相比,LLM生成及人机协作撰写的评论展现出更多与建设性相关的语言特征。当参与者使用LLM优化其评论时,生成的评论更长、更礼貌、更积极、毒性更低、可读性更高,并增添了论证性特征,这些特征保留了原意但偶尔会丢失细微差别。基于这些发现,我们讨论了使用LLM促进在线建设性话语的伦理与设计考量。