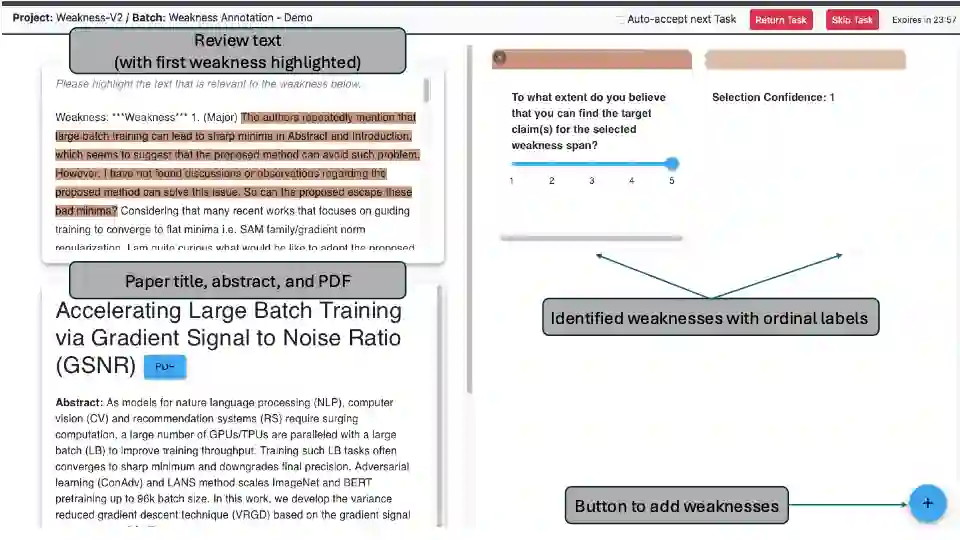
A core part of scientific peer review involves providing expert critiques that directly assess the scientific claims a paper makes. While it is now possible to automatically generate plausible (if generic) reviews, ensuring that these reviews are sound and grounded in the papers' claims remains challenging. To facilitate LLM benchmarking on these challenges, we introduce CLAIMCHECK, an annotated dataset of NeurIPS 2023 and 2024 submissions and reviews mined from OpenReview. CLAIMCHECK is richly annotated by ML experts for weakness statements in the reviews and the paper claims that they dispute, as well as fine-grained labels of the validity, objectivity, and type of the identified weaknesses. We benchmark several LLMs on three claim-centric tasks supported by CLAIMCHECK, requiring models to (1) associate weaknesses with the claims they dispute, (2) predict fine-grained labels for weaknesses and rewrite the weaknesses to enhance their specificity, and (3) verify a paper's claims with grounded reasoning. Our experiments reveal that cutting-edge LLMs, while capable of predicting weakness labels in (2), continue to underperform relative to human experts on all other tasks.
翻译:科学同行评审的核心环节在于提供直接评估论文科学主张的专家评议。尽管目前已有方法能自动生成看似合理(即便较为笼统)的评审意见,但确保这些评议的严谨性及其与论文主张的关联性仍具挑战性。为推进大语言模型在此类挑战上的基准测试,我们引入了CLAIMCHECK——一个基于OpenReview平台采集的NeurIPS 2023与2024投稿及评审数据构建的标注数据集。该数据集由机器学习专家对评审意见中的缺陷陈述及其反驳的论文主张进行了深度标注,并对所识别缺陷的有效性、客观性和类型提供了细粒度标签。我们基于CLAIMCHECK支持的三个以主张为中心的任务对多个大语言模型进行基准测试,要求模型能够:(1)将缺陷陈述与其反驳的主张相关联;(2)预测缺陷的细粒度标签并重写缺陷陈述以提升其针对性;(3)通过扎实推理验证论文主张。实验表明,前沿大语言模型虽能完成任务(2)中的缺陷标签预测,但在其余所有任务上仍显著逊色于人类专家。