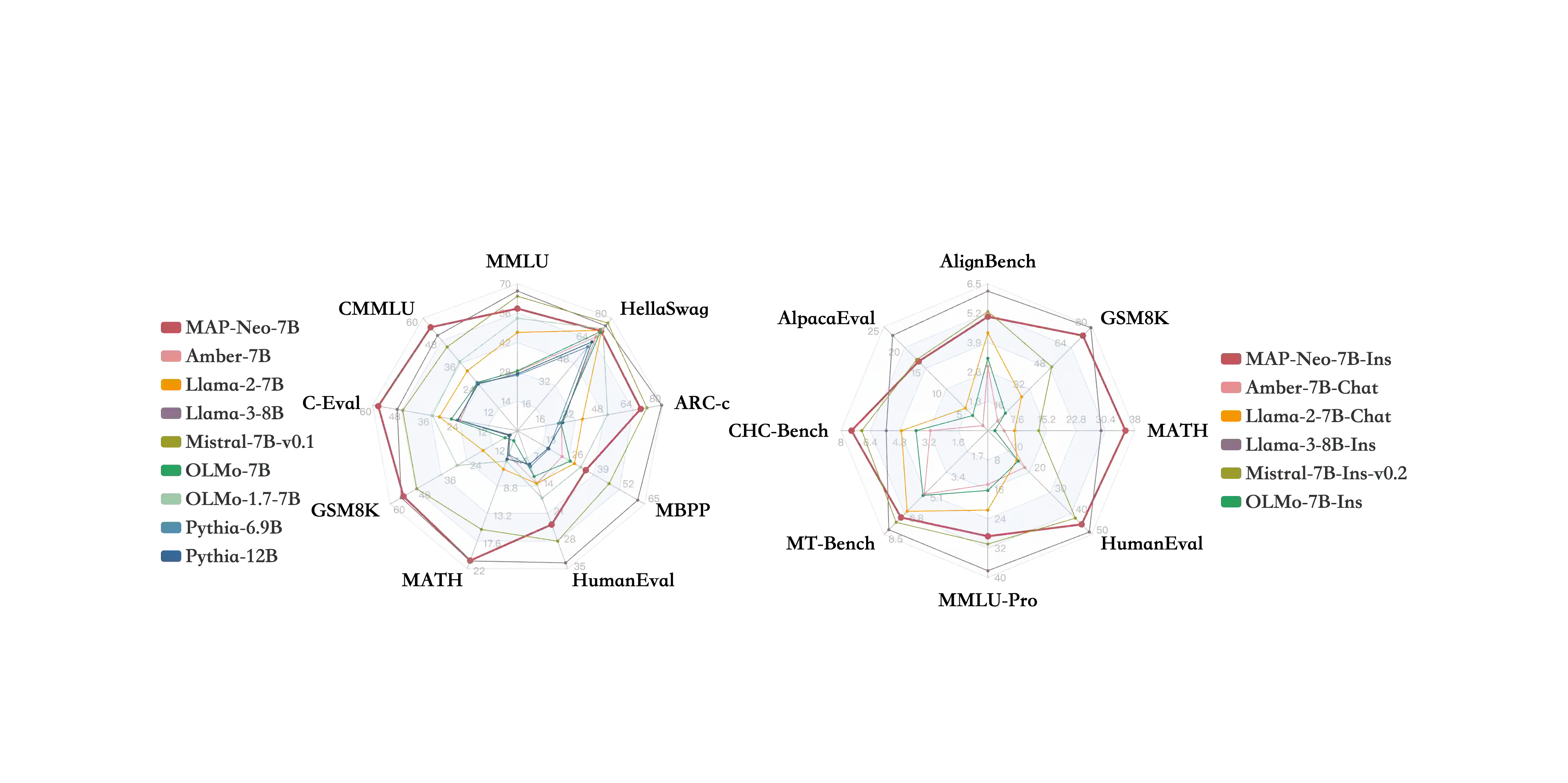
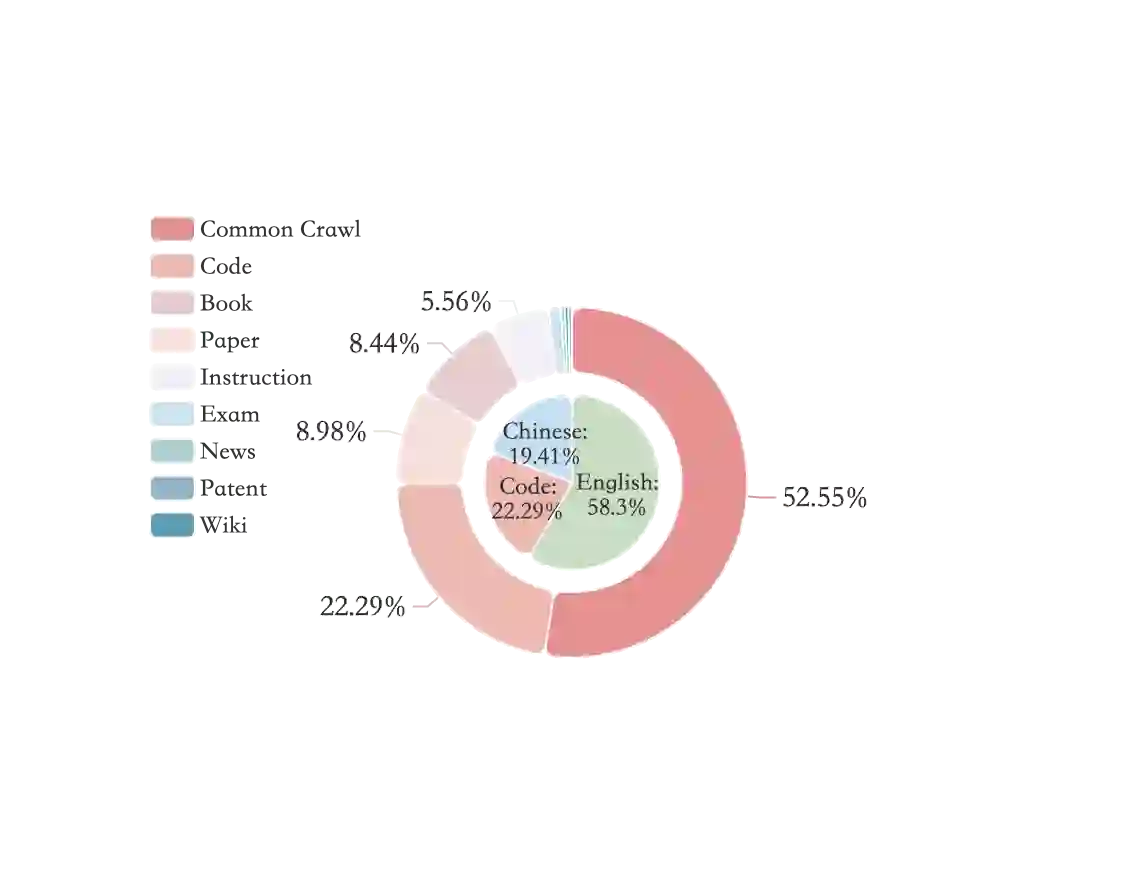
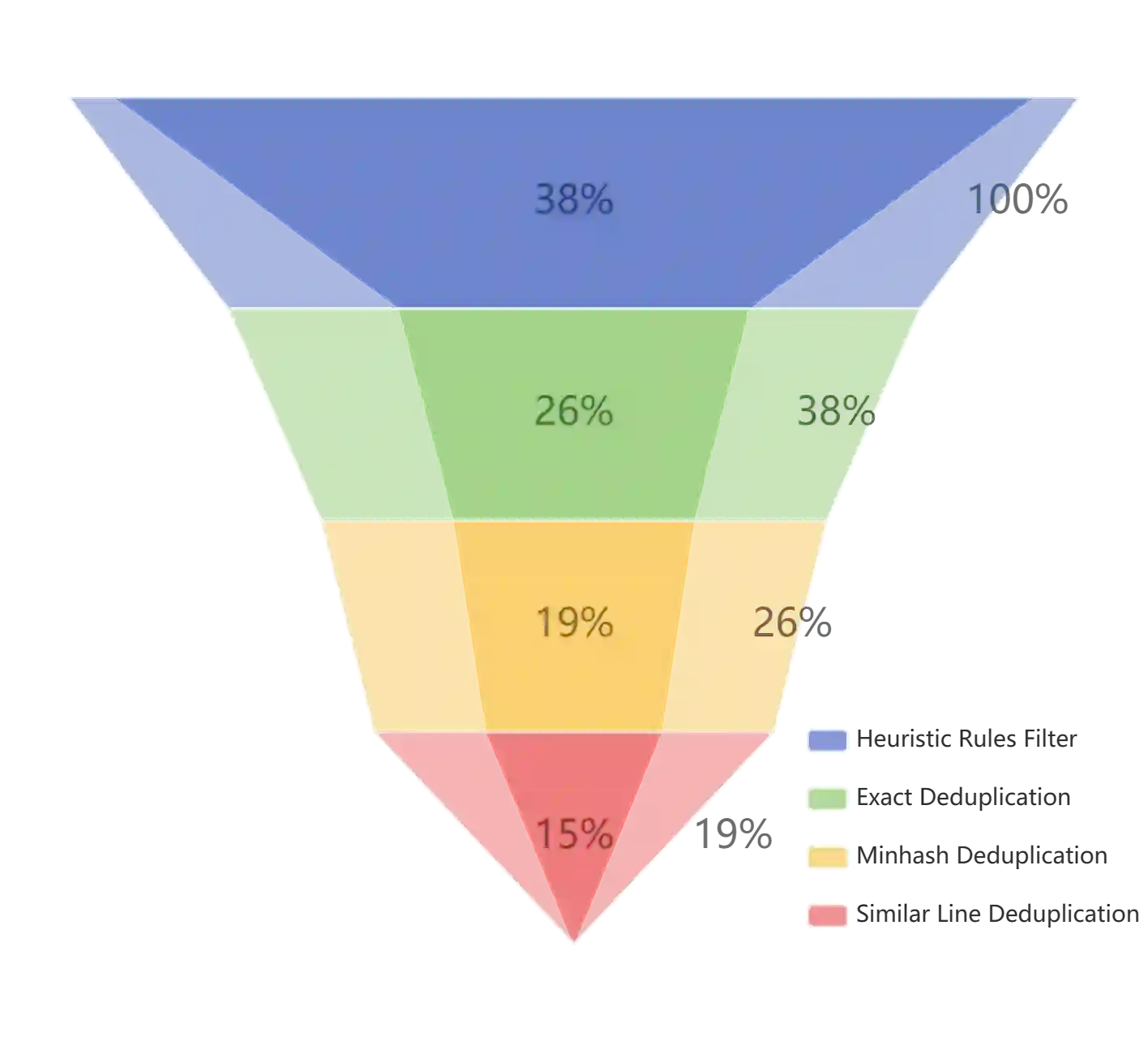
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details. Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model's weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed. To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases and risks. However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens. Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided. Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.
翻译:近年来,大语言模型(LLMs)取得了巨大进展,在各种任务上实现了前所未有的性能。然而,出于商业利益考量,最具竞争力的模型(如GPT、Gemini和Claude)均通过专有接口封闭提供,未公开训练细节。近期,许多机构开源了多个性能强大的LLM(如LLaMA-3),其能力可与现有闭源LLM相媲美。但这些模型通常仅提供权重参数,多数关键细节(如中间检查点、预训练语料库和训练代码等)仍未公开。为提升LLM的透明度,研究界已开始推动真正开源LLM的发展(如Pythia、Amber、OLMo),这些模型提供了更多细节(如预训练语料库和训练代码)。这些工作极大推进了对大模型优势、缺陷、偏见及风险等方面的科学研究。然而,我们观察到现有真正开源的LLM在推理、知识和代码任务上的表现,仍逊于同规模的最先进LLM。为此,我们开源了MAP-Neo——一个基于4.5万亿高质量词元从头训练、拥有70亿参数的高性能透明双语语言模型。MAP-Neo是首个完全开源且性能与现有最先进LLM相当的双语LLM。此外,我们开源了复现MAP-Neo所需的全部细节,包括清洗后的预训练语料库、数据清洗流程、检查点以及高度优化的训练/评估框架。我们期待MAP-Neo能够推动开源研究社区的发展,激发更多创新与创造力,从而促进LLM的持续进步。