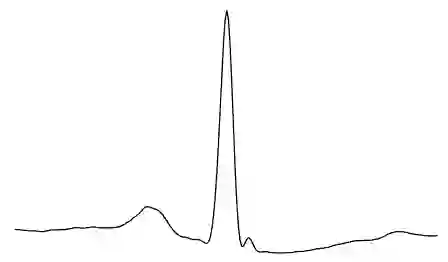
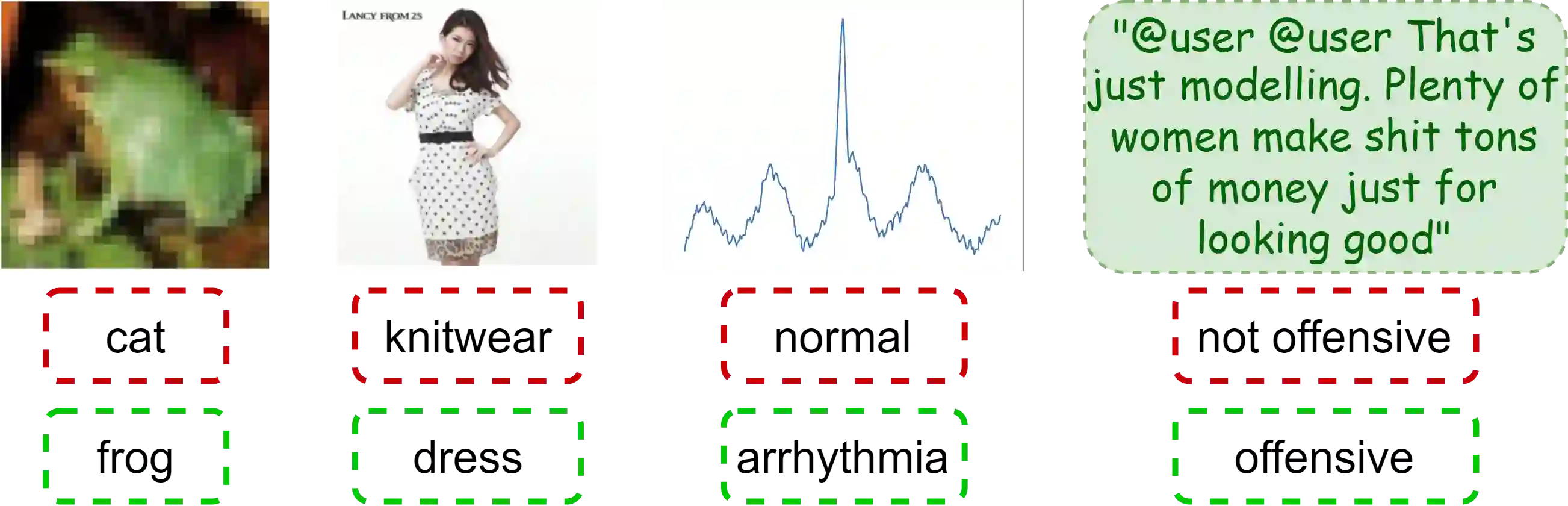
Machine learning (ML) models are only as good as the data they are trained on. But recent studies have found datasets widely used to train and evaluate ML models, e.g. ImageNet, to have pervasive labeling errors. Erroneous labels on the train set hurt ML models' ability to generalize, and they impact evaluation and model selection using the test set. Consequently, learning in the presence of labeling errors is an active area of research, yet this field lacks a comprehensive benchmark to evaluate these methods. Most of these methods are evaluated on a few computer vision datasets with significant variance in the experimental protocols. With such a large pool of methods and inconsistent evaluation, it is also unclear how ML practitioners can choose the right models to assess label quality in their data. To this end, we propose a benchmarking environment AQuA to rigorously evaluate methods that enable machine learning in the presence of label noise. We also introduce a design space to delineate concrete design choices of label error detection models. We hope that our proposed design space and benchmark enable practitioners to choose the right tools to improve their label quality and that our benchmark enables objective and rigorous evaluation of machine learning tools facing mislabeled data.
翻译:机器学习(ML)模型的有效性取决于其训练数据的质量。然而,近期研究发现,广泛用于训练和评估机器学习模型的数据集(如ImageNet)普遍存在标注错误。训练集中的错误标注会损害模型的泛化能力,并影响基于测试集的评估与模型选择。因此,在存在标注错误的情况下进行学习已成为一个活跃的研究领域,但该领域仍缺乏全面的基准测试来评估相关方法。目前多数方法仅在少量计算机视觉数据集上评估,且实验方案差异显著。面对众多方法及不一致的评估标准,机器学习从业者也难以确定如何选择合适的模型来评估自身数据的标注质量。为此,我们提出基准测试环境AQuA,用于严格评估支持标注噪声下机器学习的方法。同时引入设计空间,系统刻画标签错误检测模型的具体设计选择。我们期望提出的设计空间与基准测试能帮助从业者选择恰当工具以提升标注质量,并为面临错误标注数据的机器学习工具提供客观、严谨的评估标准。