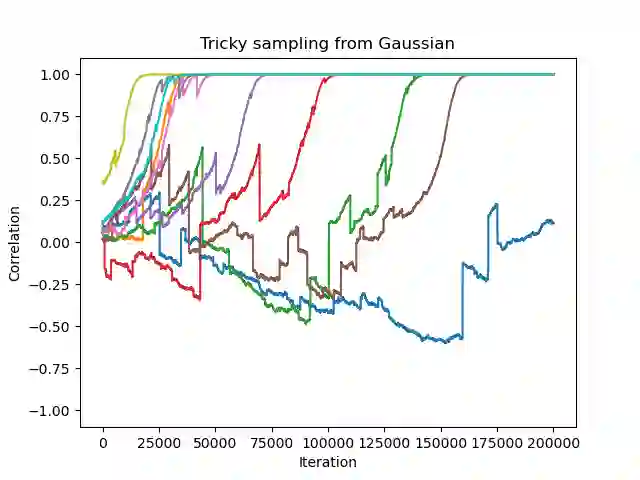
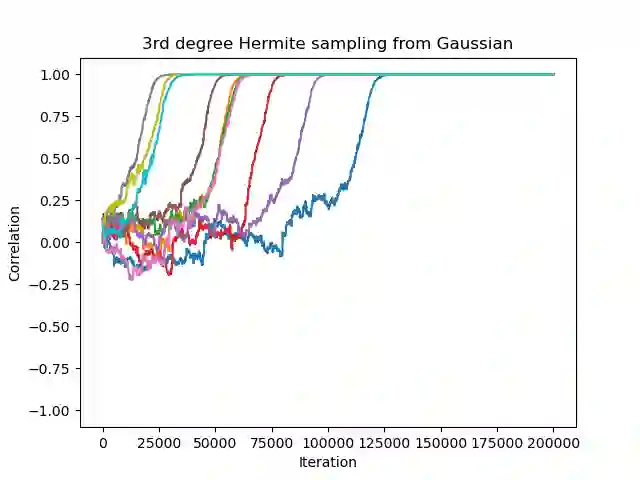
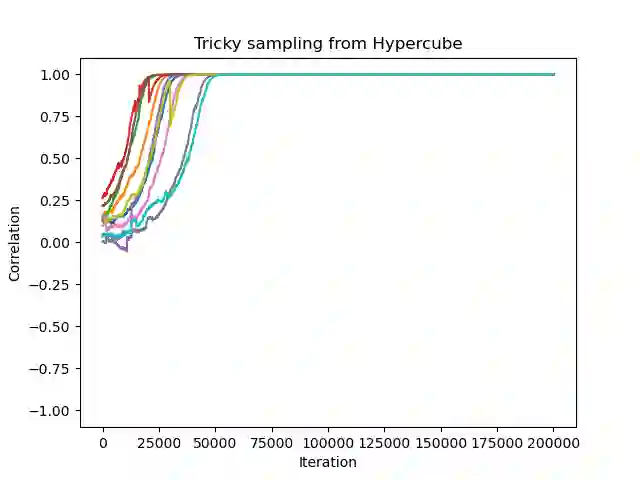
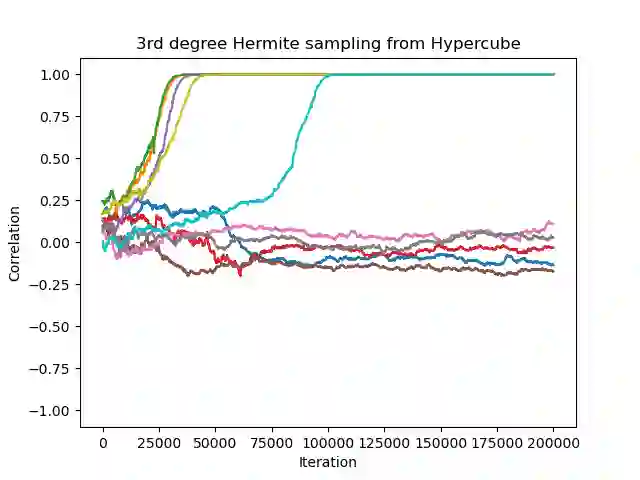
Sparse high-dimensional functions have arisen as a rich framework to study the behavior of gradient-descent methods using shallow neural networks, showcasing their ability to perform feature learning beyond linear models. Amongst those functions, the simplest are single-index models $f(x) = \phi( x \cdot \theta^*)$, where the labels are generated by an arbitrary non-linear scalar link function $\phi$ applied to an unknown one-dimensional projection $\theta^*$ of the input data. By focusing on Gaussian data, several recent works have built a remarkable picture, where the so-called information exponent (related to the regularity of the link function) controls the required sample complexity. In essence, these tools exploit the stability and spherical symmetry of Gaussian distributions. In this work, building from the framework of \cite{arous2020online}, we explore extensions of this picture beyond the Gaussian setting, where both stability or symmetry might be violated. Focusing on the planted setting where $\phi$ is known, our main results establish that Stochastic Gradient Descent can efficiently recover the unknown direction $\theta^*$ in the high-dimensional regime, under assumptions that extend previous works \cite{yehudai2020learning,wu2022learning}.
翻译:稀疏高维函数已成为研究浅层神经网络梯度下降方法行为的丰富框架,展示了其在超越线性模型的特征学习能力。在这类函数中,最简单的单指标模型 $f(x) = \phi( x \cdot \theta^*)$ 通过将未知的一维投影 $\theta^*$ 作用于输入数据,再由任意非线性标量链接函数 $\phi$ 生成标签。以高斯数据为研究对象,近期多项工作描绘了一幅引人注目的图景:所谓的信息指数(与链接函数的正则性相关)控制着所需的样本复杂度。本质而言,这些工具利用了高斯分布的稳定性和球对称性。本研究基于 \cite{arous2020online} 的框架框架,探讨该图景在高斯设置之外的扩展——其中稳定性或对称性可能被破坏。聚焦于 $\phi$ 已知的植入式设定,我们的主要结果表明:在拓展先前工作 \cite{yehudai2020learning,wu2022learning} 的假设条件下,随机梯度下降能高效恢复高维场景中的未知方向 $\theta^*$。