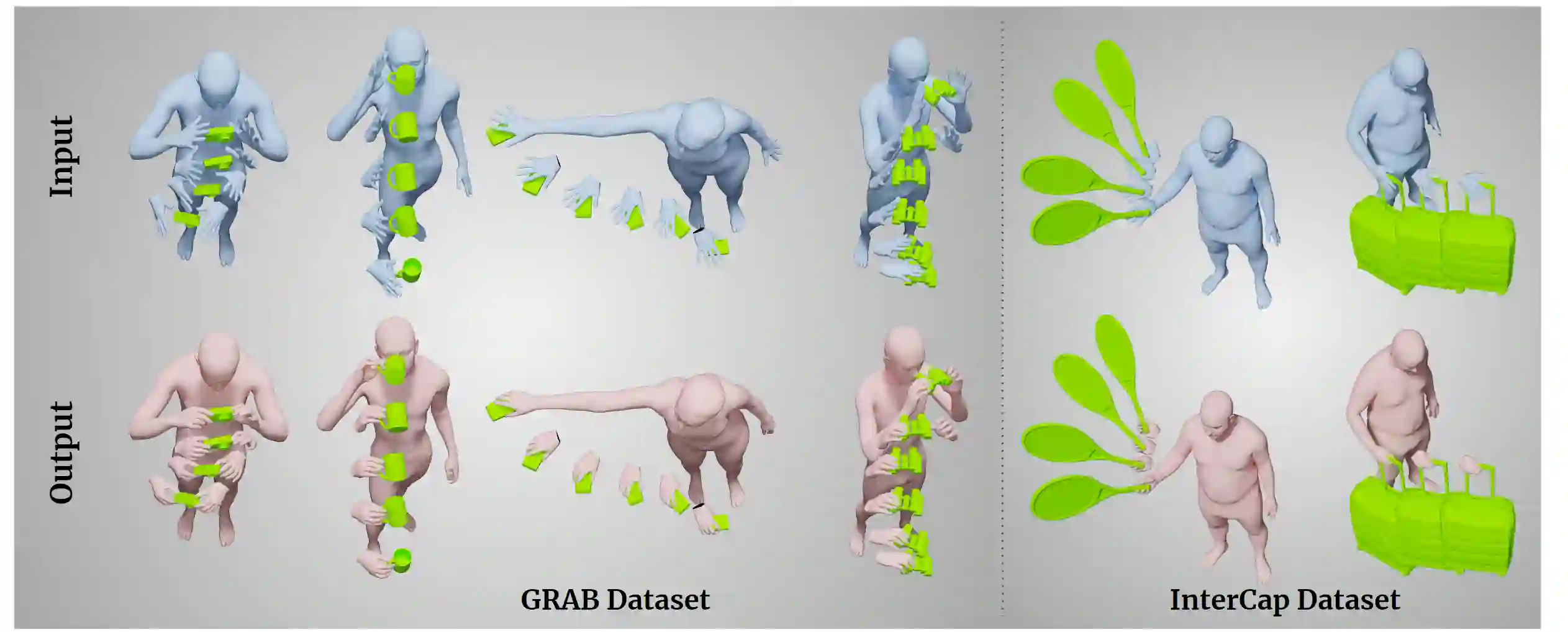
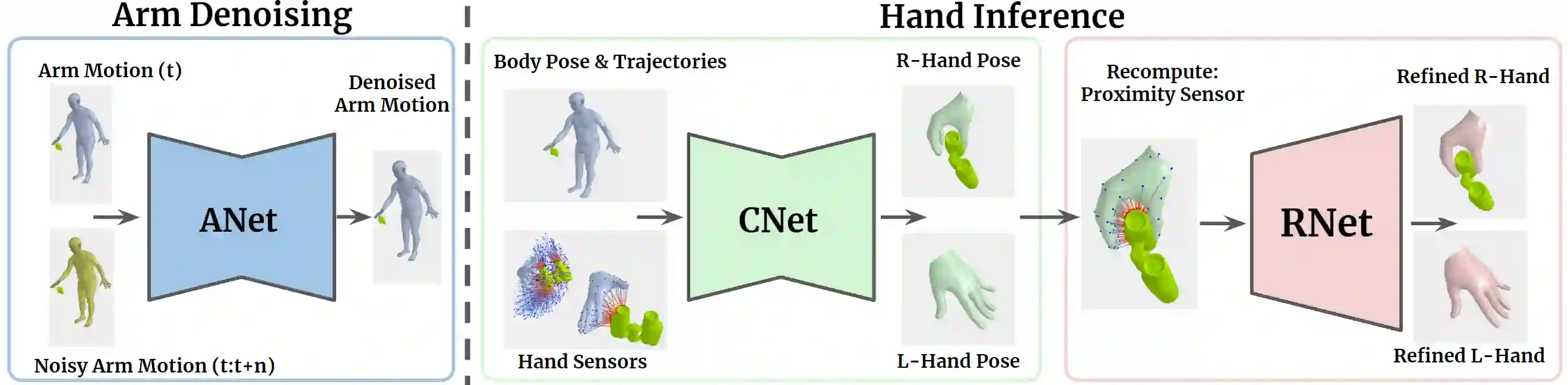
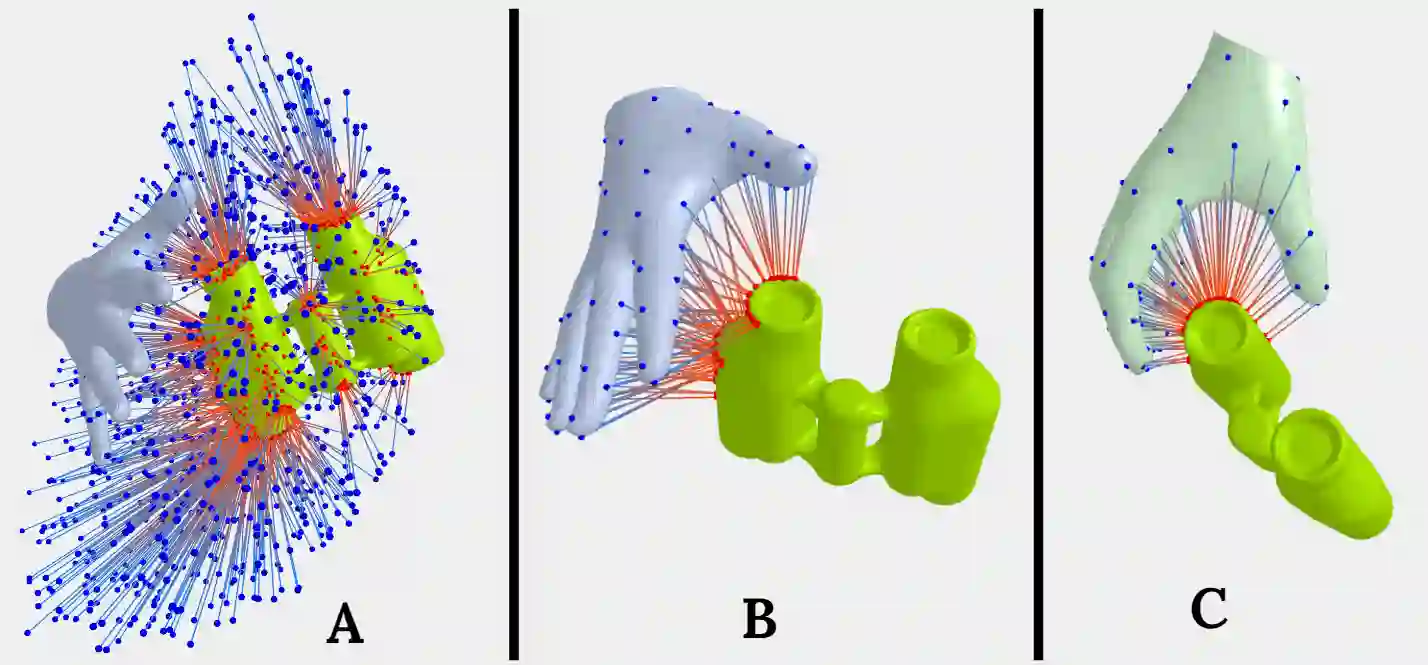
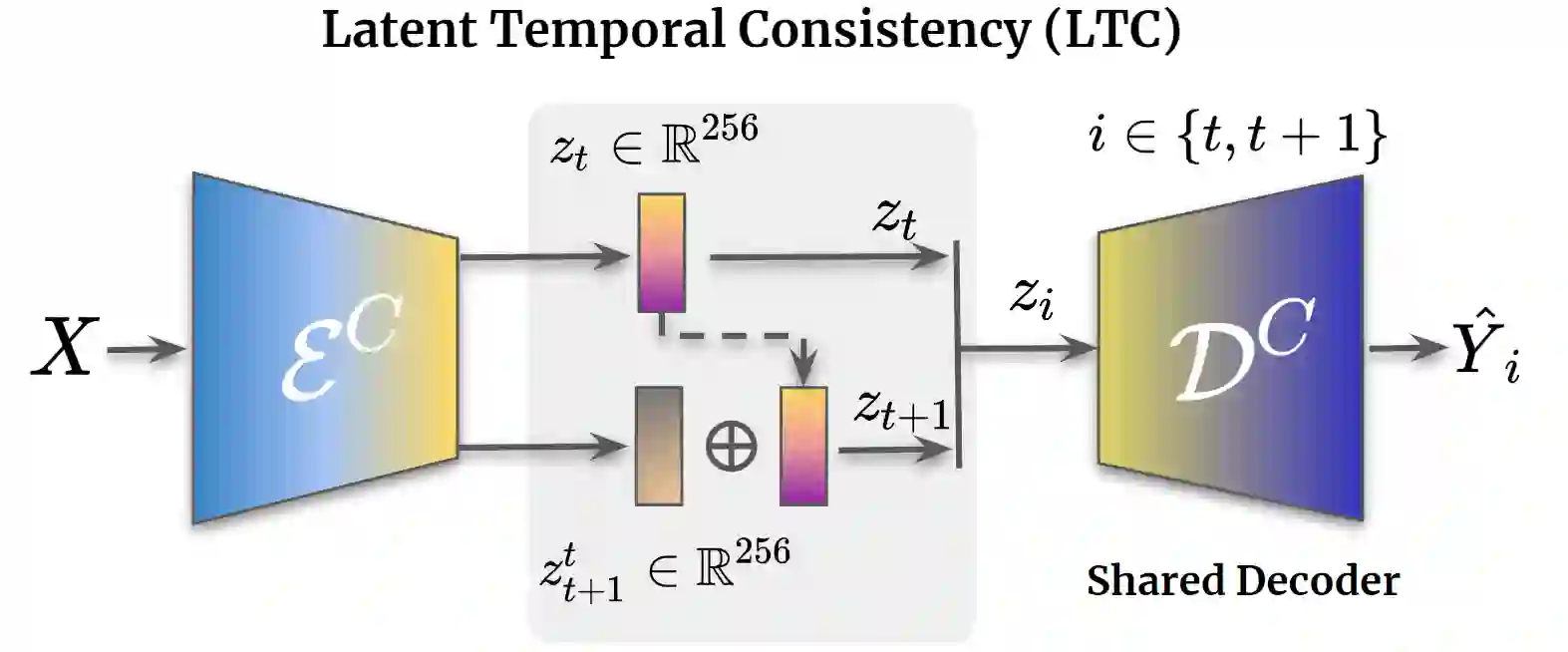
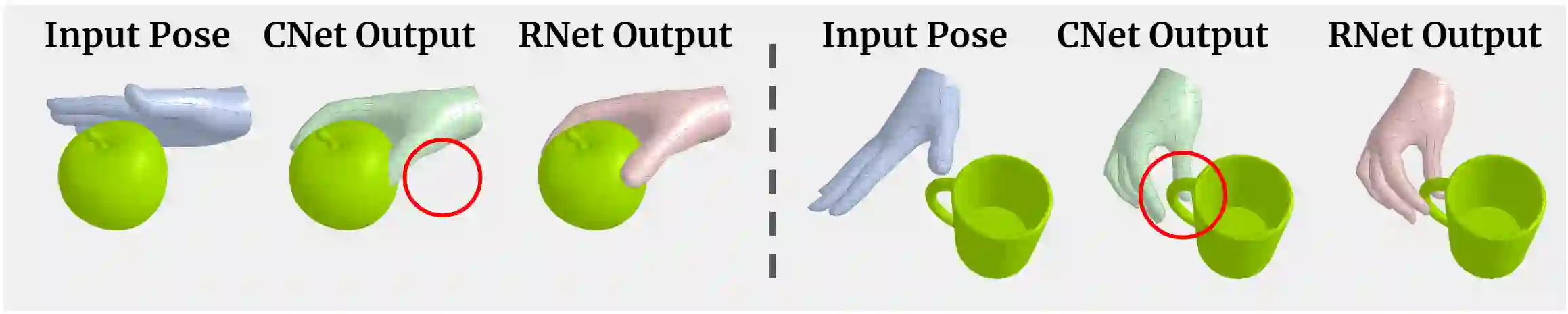
Hands are dexterous and highly versatile manipulators that are central to how humans interact with objects and their environment. Consequently, modeling realistic hand-object interactions, including the subtle motion of individual fingers, is critical for applications in computer graphics, computer vision, and mixed reality. Prior work on capturing and modeling humans interacting with objects in 3D focuses on the body and object motion, often ignoring hand pose. In contrast, we introduce GRIP, a learning-based method that takes, as input, the 3D motion of the body and the object, and synthesizes realistic motion for both hands before, during, and after object interaction. As a preliminary step before synthesizing the hand motion, we first use a network, ANet, to denoise the arm motion. Then, we leverage the spatio-temporal relationship between the body and the object to extract two types of novel temporal interaction cues, and use them in a two-stage inference pipeline to generate the hand motion. In the first stage, we introduce a new approach to enforce motion temporal consistency in the latent space (LTC), and generate consistent interaction motions. In the second stage, GRIP generates refined hand poses to avoid hand-object penetrations. Given sequences of noisy body and object motion, GRIP upgrades them to include hand-object interaction. Quantitative experiments and perceptual studies demonstrate that GRIP outperforms baseline methods and generalizes to unseen objects and motions from different motion-capture datasets.
翻译:手部是灵巧且高度通用的操纵器,在人类与物体及环境交互中起着核心作用。因此,对逼真的手-物体交互进行建模(包括单个手指的细微运动),对于计算机图形学、计算机视觉和混合现实领域的应用至关重要。以往关于捕捉和建模人类与物体三维交互的研究主要关注身体和物体的运动,往往忽略手部姿态。相比之下,我们提出GRIP——一种基于学习的方法,它以身体和物体的三维运动作为输入,并在物体交互之前、期间和之后合成为双手的逼真运动。作为合成手部运动前的预处理步骤,我们首先使用一个名为ANet的网络来去噪手臂运动。随后,我们利用身体与物体之间的时空关系,提取出两种新型的时域交互线索,并通过两阶段推理流程生成手部运动。在第一阶段,我们引入了一种新方法,在潜在空间中强制实现运动的时间一致性(LTC),从而生成一致的交互运动。在第二阶段,GRIP生成精化的手部姿态以避免手-物体穿透。给定含噪声的身体和物体运动序列,GRIP对其进行升级以包含手-物体交互。定量实验和感知研究表明,GRIP优于基线方法,并能泛化到来自不同动作捕捉数据集的未见物体和运动。